

使用 PyTorch FSDP 实现 Lora 及 Q-Lora 微调 Llama 3 70B 模型
本文介绍如何使用 PyTorch FSDP 和 Q-Lora,通过 Hugging Face TRL、Transformers、peft 和 datasets 来微调 Llama 3。我们还将使用 Pytorch SDPA 实现的 Flash Attention v2。
注意
本文在无问芯穹 AIStudio 平台上,使用含 8 张 NVIDIA A100 的资源规格验证。如果你计算资源有限,可更改配置(yaml)。
学习目标
- 如何构建自定义镜像
- 如何下载和准备数据
- 如何使用 PyTorch FSDP、Q-Lora 和 SDPA 微调 LLM
- 如何使用 PyTorch FSDP、Lora 和 SDPA 微调 LLM
- 如何在智算云平台提交训练任务
- 如何在智算云平台查看训练过程数据
FSDP 优势
PyTorch FSDP(全分片数据并行)一种数据/模型并行技术,将模型分片到多个 GPU 上,减少内存需求并更高效地训练更大的模型。
使用 DDP(Distributed Data Parallelism)时,如果单个 GPU 无法存储一个完整的模型副本,可以配合使用 DeepSpeed 或 Megatron-LM 实现实现模型并行和流水线并行,但方案相对更为复杂。
前提条件
本教程使用了 8 卡 A100 的计算资源和较大的文件存储。
设置环境
作为最佳实践,我们建议先将依赖的软件制作成自定义镜像,方便后续在开发机、任务功能等多处引用。
点击下方前往智算云平台,切换到自定义镜像标签页后,点击构建镜像。
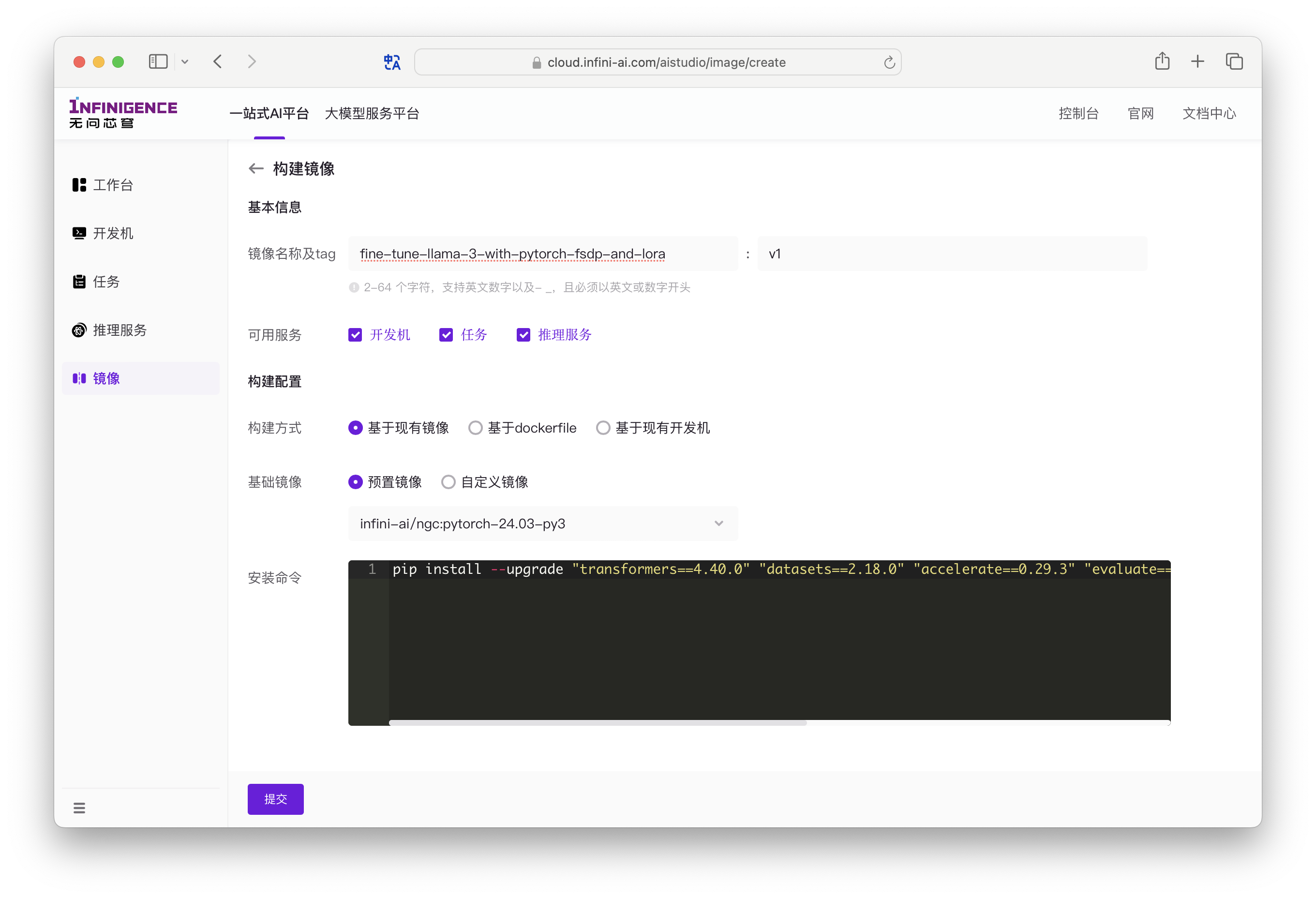
在上方界面中,我们选择 AIStudio 的 NGC 镜像为基础镜像(cr.infini-ai.com/infini-ai/ngc:pytorch-24.03-py3),安装 Hugging Face 的 trl、transformers 和 datasets 等软件。
# 该 NGC 镜像已预置 pytorch,无需额外安装
pip install --upgrade "transformers==4.40.0" "datasets==2.18.0" "accelerate==0.29.3" "evaluate==0.4.1" "bitsandbytes==0.43.1" "huggingface_hub==0.22.2" "trl==0.8.6" "peft==0.10.0"该镜像将在提交训练任务时使用。镜像构建完成需要一定时间,你可以先进行下一步。
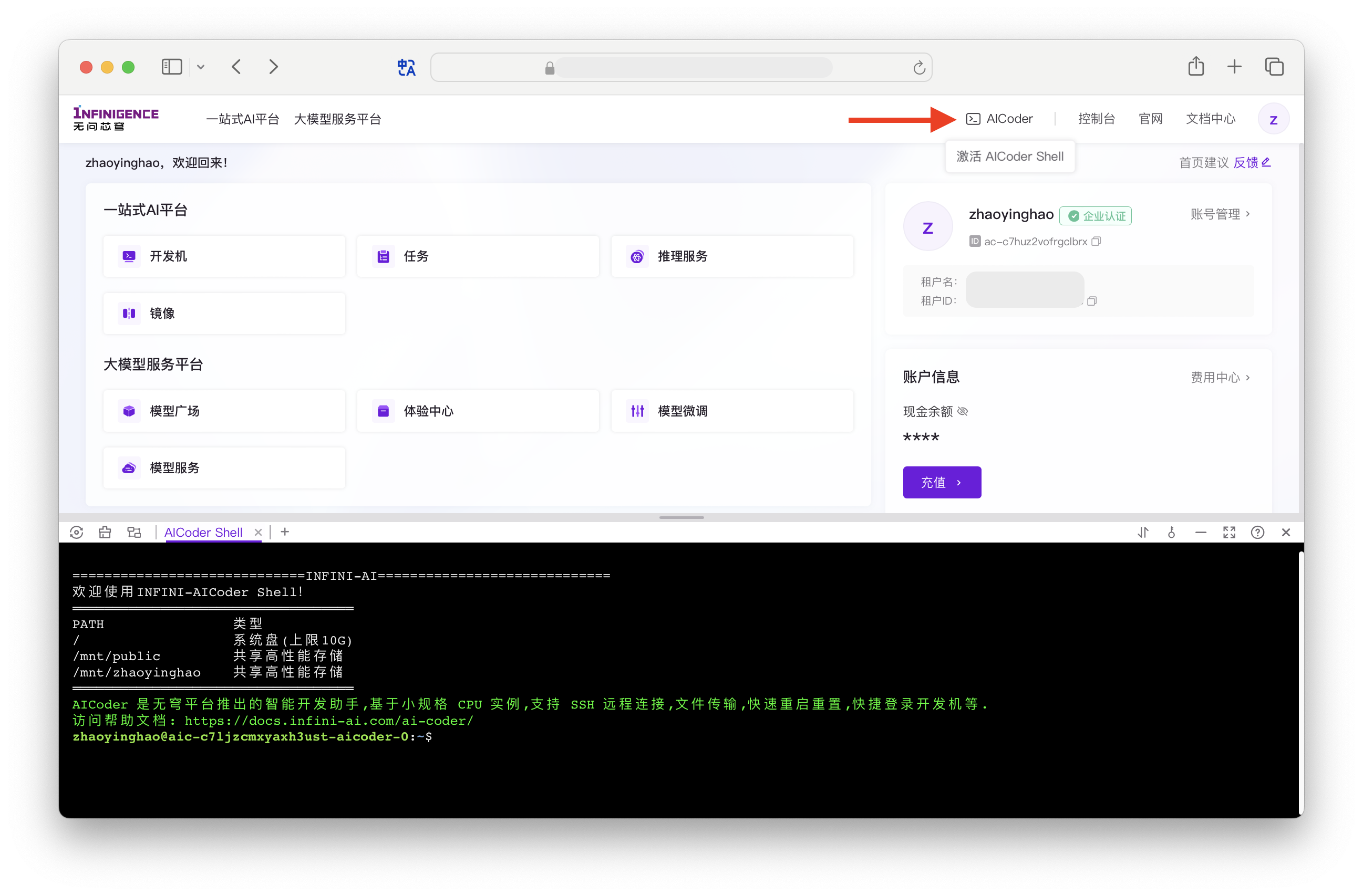
接下来,你可以打开 AICoder Shell,准备下载和预处理数据。AICoder 是智算云平台免费为租户提供的 CPU 实例,可用于完成训练前将数据传输、数据处理等任务。
注意
- AICoder 支持远程 SSH 登录、与本地计算机之间传输数据。
- 如果租户下有足够的资源,你也可以创建一台挂载 GPU 的开发机。开发机不仅可以用于传输和预处理数据,也可以用于调试训练代码。在开发机列表页面,点击 创建开发机。根据页面提示,选择 A100 x 8 的资源规格,并选择刚才构建的镜像。
下载模型和微调数据集
下载工具这部分大家可以各显神通。本教程使用了 HuggingFace 镜像站点(hf-mirror.com)及多线程下载工具 hfd.sh。
注意
由于 Meta-Llama-3-70B 属于 Gated 模型,需要请先从 HuggingFace 申请访问 Llama 3 70b 模型,等待审批通过后可以下载。
我们使用 HuggingFaceH4/no_robots 作为微调数据集,这是一个由人类注释员创建的 10,000 条指令的高质量数据集。
在 AICoder Shell 或开发机中,执行以下操作,将 Meta-Llama-3-70B 和微调数据集下载到共享高性能存储。
# 使用 root 用户,安装 aria2
apt update
apt install aria2
# 切换会普通用户
su your_user_name
# 进入挂载的共享共性能存储
cd /mnt/public
# 获取 hfd 脚本
wget https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
# 设置环境变量
export HF_ENDPOINT=https://hf-mirror.com
# 由于模型较大,需要下载到共享高性能文件存储中
cd /mnt/public
# 下载数据集
./hfd.sh HuggingFaceH4/no_robots --dataset --tool aria2c -x 4
# 下载模型,下载 Gated 模型需要提供 HuggingFace 用户名和 Token
# token 从 https://huggingface.co/settings/tokens 获取
# 模型较大,请耐心等待
mkdir models
cd models
../hfd.sh meta-llama/Meta-Llama-3-70B --hf_username your_hf_username --hf_token your_hf_token --tool aria2c -x 4预处理数据集
HuggingFaceH4/no_robots 数据为 parquet 格式,需要转换为 json 格式。
# process_datasets.py
from datasets import load_dataset
# Convert dataset to OAI messages
system_message = """You are Llama, an AI assistant created by Infinigence-AI to be helpful and honest. Your knowledge spans a wide range of topics, allowing you to engage in substantive conversations and provide analysis on complex subjects."""
def create_conversation(sample):
if sample["messages"][0]["role"] == "system":
return sample
else:
sample["messages"] = [{"role": "system", "content": system_message}] + sample["messages"]
return sample
# Load dataset from the hub
dataset = load_dataset("parquet", data_files={'train': './data/train_sft-00000-of-00001.parquet', 'test': './data/test_sft-00000-of-00001.parquet'})
# Add system message to each conversation
columns_to_remove = list(dataset["train"].features)
columns_to_remove.remove("messages")
dataset = dataset.map(create_conversation, remove_columns=columns_to_remove,batched=False)
# Filter out conversations which are corrupted with wrong turns, keep which have even number of turns after adding system message
dataset["train"] = dataset["train"].filter(lambda x: len(x["messages"][1:]) % 2 == 0)
dataset["test"] = dataset["test"].filter(lambda x: len(x["messages"][1:]) % 2 == 0)
# save datasets to disk
dataset["train"].to_json("train_dataset.json", orient="records", force_ascii=False)
dataset["test"].to_json("test_dataset.json", orient="records", force_ascii=False)使用 PyTorch FSDP、Q-Lora 和 SDPA 微调 LLM
准备脚本 run_fsdp_qlora.py,加载数据集,准备模型和 tokenizer,并启动训练。使用 trl 中的 SFTTrainer 微调模型。
run_fsdp_qlora.py
import logging
from dataclasses import dataclass, field
import os
import random
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, TrainingArguments
from trl.commands.cli_utils import TrlParser
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import setup_chat_format
from peft import LoraConfig
from trl import (
SFTTrainer)
# Comment in if you want to use the Llama 3 instruct template but make sure to add modules_to_save
# LLAMA_3_CHAT_TEMPLATE="{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}"
# Anthropic/Vicuna like template without the need for special tokens
LLAMA_3_CHAT_TEMPLATE = (
"{% for message in messages %}"
"{% if message['role'] == 'system' %}"
"{{ message['content'] }}"
"{% elif message['role'] == 'user' %}"
"{{ '\n\nHuman: ' + message['content'] + eos_token }}"
"{% elif message['role'] == 'assistant' %}"
"{{ '\n\nAssistant: ' + message['content'] + eos_token }}"
"{% endif %}"
"{% endfor %}"
"{% if add_generation_prompt %}"
"{{ '\n\nAssistant: ' }}"
"{% endif %}"
)
# ACCELERATE_USE_FSDP=1 FSDP_CPU_RAM_EFFICIENT_LOADING=1 torchrun --nproc_per_node=4 ./scripts/run_fsdp_qlora.py --config llama_3_70b_fsdp_qlora.yaml
@dataclass
class ScriptArguments:
dataset_path: str = field(
default=None,
metadata={
"help": "Path to the dataset"
},
)
model_id: str = field(
default=None, metadata={"help": "Model ID to use for SFT training"}
)
max_seq_length: int = field(
default=512, metadata={"help": "The maximum sequence length for SFT Trainer"}
)
def training_function(script_args, training_args):
################
# Dataset
################
train_dataset = load_dataset(
"json",
data_files=os.path.join(script_args.dataset_path, "train_dataset.json"),
split="train",
)
test_dataset = load_dataset(
"json",
data_files=os.path.join(script_args.dataset_path, "test_dataset.json"),
split="train",
)
################
# Model & Tokenizer
################
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(script_args.model_id, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.chat_template = LLAMA_3_CHAT_TEMPLATE
# template dataset
def template_dataset(examples):
return{"text": tokenizer.apply_chat_template(examples["messages"], tokenize=False)}
train_dataset = train_dataset.map(template_dataset, remove_columns=["messages"])
test_dataset = test_dataset.map(template_dataset, remove_columns=["messages"])
# print random sample
with training_args.main_process_first(
desc="Log a few random samples from the processed training set"
):
for index in random.sample(range(len(train_dataset)), 2):
print(train_dataset[index]["text"])
# Model
torch_dtype = torch.bfloat16
quant_storage_dtype = torch.bfloat16
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_quant_storage=quant_storage_dtype,
)
model = AutoModelForCausalLM.from_pretrained(
script_args.model_id,
quantization_config=quantization_config,
attn_implementation="sdpa", # use sdpa, alternatively use "flash_attention_2"
torch_dtype=quant_storage_dtype,
use_cache=False if training_args.gradient_checkpointing else True, # this is needed for gradient checkpointing
)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
################
# PEFT
################
# LoRA config based on QLoRA paper & Sebastian Raschka experiment
peft_config = LoraConfig(
lora_alpha=8,
lora_dropout=0.05,
r=16,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
# modules_to_save = ["lm_head", "embed_tokens"] # add if you want to use the Llama 3 instruct template
)
################
# Training
################
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
dataset_text_field="text",
eval_dataset=test_dataset,
peft_config=peft_config,
max_seq_length=script_args.max_seq_length,
tokenizer=tokenizer,
packing=True,
dataset_kwargs={
"add_special_tokens": False, # We template with special tokens
"append_concat_token": False, # No need to add additional separator token
},
)
if trainer.accelerator.is_main_process:
trainer.model.print_trainable_parameters()
##########################
# Train model
##########################
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
trainer.train(resume_from_checkpoint=checkpoint)
##########################
# SAVE MODEL FOR SAGEMAKER
##########################
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model()
if __name__ == "__main__":
parser = TrlParser((ScriptArguments, TrainingArguments))
script_args, training_args = parser.parse_args_and_config()
# set use reentrant to False
if training_args.gradient_checkpointing:
training_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
# set seed
set_seed(training_args.seed)
# launch training
training_function(script_args, training_args)llama_3_70b_fsdp_qlora.yaml
# script parameters
model_id: "/mnt/public/models/Meta-Llama-3-70B" # Hugging Face model id
dataset_path: "/mnt/public/no_robots" # path to dataset
max_seq_len: 3072 # 2048 # max sequence length for model and packing of the dataset
# training parameters
output_dir: "/mnt/public/llama-3-70b-hf-no-robot" # Temporary output directory for model checkpoints
report_to: "tensorboard" # report metrics to tensorboard
learning_rate: 0.0002 # learning rate 2e-4
lr_scheduler_type: "constant" # learning rate scheduler
num_train_epochs: 1 # number of training epochs
per_device_train_batch_size: 1 # batch size per device during training
per_device_eval_batch_size: 1 # batch size for evaluation
gradient_accumulation_steps: 2 # number of steps before performing a backward/update pass
optim: adamw_torch # use torch adamw optimizer
logging_steps: 10 # log every 10 steps
save_strategy: epoch # save checkpoint every epoch
evaluation_strategy: epoch # evaluate every epoch
max_grad_norm: 0.3 # max gradient norm
warmup_ratio: 0.03 # warmup ratio
bf16: true # use bfloat16 precision
tf32: true # use tf32 precision
gradient_checkpointing: true # use gradient checkpointing to save memory
# FSDP parameters: https://huggingface.co/docs/transformers/main/en/fsdp
fsdp: "full_shard auto_wrap" # Add offload if not enough GPU memory
fsdp_config:
backward_prefetch: "backward_pre"
forward_prefetch: "false"
use_orig_params: "false"在智算云平台提交训练任务
智算云平台提供任务功能,内置了容错能力、TensorBoard 可视化、分布式框架支持等能力。推荐使用任务功能进行训练。在调试训练代码时,也可以使用开发机进行调试。
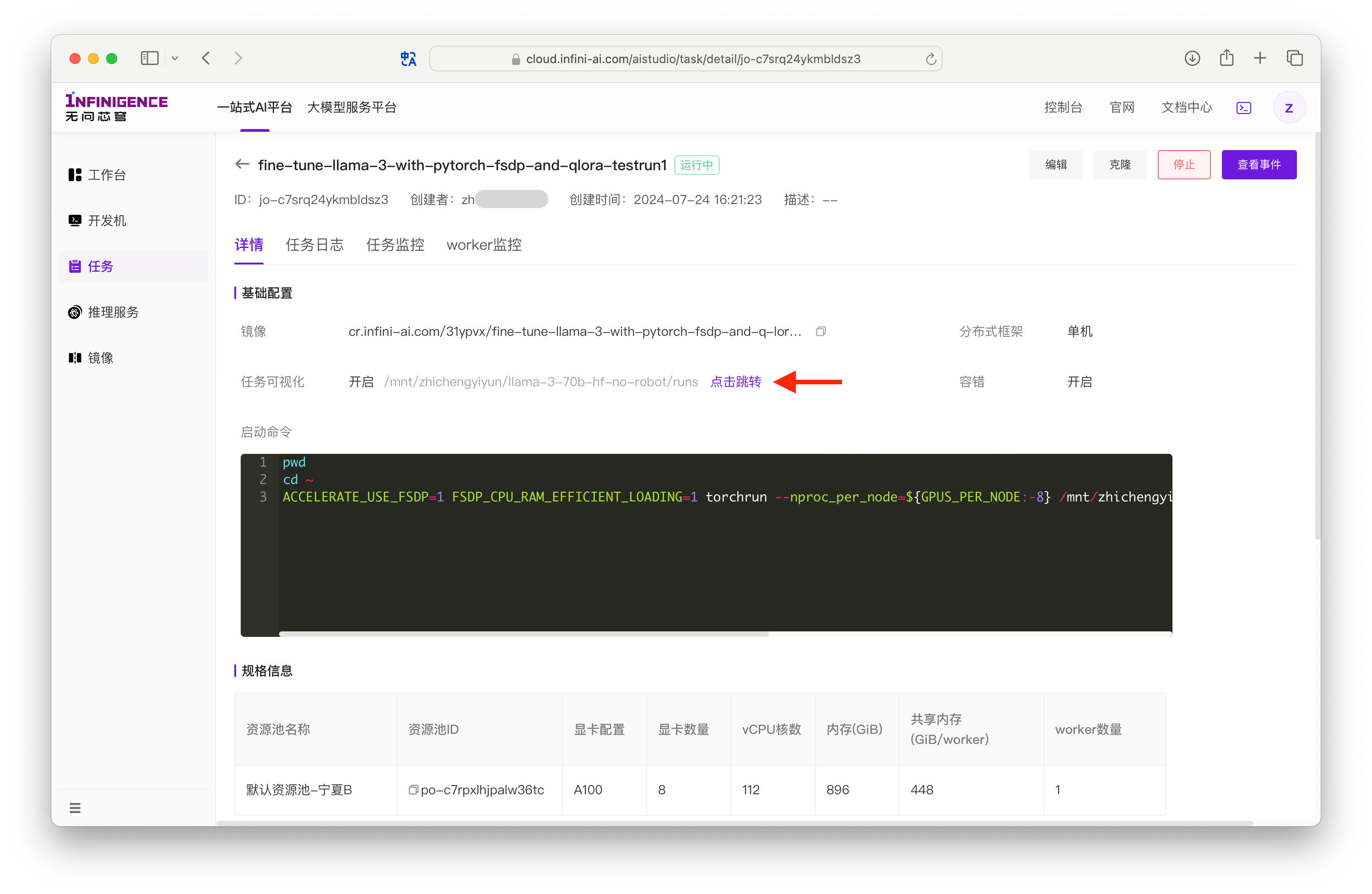
前往智算云平台任务列表页面,发起单机任务。
训练任务配置表单:
Worker 规格:选择 A100 x 8 的负载规格,用于运行微调任务。
共享内存:当前为固定值,每个 Worker 可使用的共享内存为 Work 规格内存的一半。
Worker 数量:单机训练时建议保持为 1。
镜像:选择我们创建的自定义镜像。
分布式框架:选择单机。
任务可视化:TensorBoard 可视化功能,建议启用。在任务运行过程中,AIStudio 可读取 TensorBoard 日志并进行可视化展示。
日志存储路径:开启任务可视化后,需要提供日志的访问路径。本示例中,TensorBoard 日志将自动写入 YAML 配置文件
output_dir下的runs目录:# 在本教程中的日志路径示例 /mnt/public/llama-3-70b-hf-no-robot-lora/runs容错:建议开启自动重启功能以应对训练过程中的异常。详见配置训练任务的容错功能。
启动命令: 可填写任务的环境变量及入口命令等。
bashwhoami pwd cd ~ ACCELERATE_USE_FSDP=1 FSDP_CPU_RAM_EFFICIENT_LOADING=1 torchrun --nproc_per_node=${GPUS_PER_NODE:-8} /mnt/zhichengyiyun/training/run_fsdp_qlora.py --config /mnt/zhichengyiyun/training/llama_3_70b_fsdp_qlora.yaml文件存储: 可选择挂载租户的共享高性能存储。
名称:1~64 个字符,支持中英文数字以及- _,允许重复,名称不唯一。
完成配置后,点击确认创建,任务进入创建流程。创建成功后,您可以在列表中查看任务的状态。
提示
不使用训练任务?您也可以在智算云平台的开发机上运行以上命令。
使用 PyTorch FSDP、LoRA 和 SDPA 微调 LLM
要将脚本和配置文件从 Q-Lora 修改为 LoRA,可进行以下更改:
修改 Python 脚本
移除与量化相关的设置,并调整模型加载方式:
# 移除或注释掉与 BitsAndBytesConfig 相关的部分
# quantization_config = BitsAndBytesConfig(
# load_in_4bit=True,
# bnb_4bit_use_double_quant=True,
# bnb_4bit_quant_type="nf4",
# bnb_4bit_compute_dtype=torch_dtype,
# bnb_4bit_quant_storage=quant_storage_dtype,
# )
# 更新模型加载行以移除 quantization_config
model = AutoModelForCausalLM.from_pretrained(
script_args.model_id,
# quantization_config=quantization_config, # 移除此参数
attn_implementation="sdpa", # 使用 sdpa,或 "flash_attention_2"
torch_dtype=torch.float16, # 如果硬件支持,则改为 float16,否则使用 float32
use_cache=False if training_args.gradient_checkpointing else True,
)确保 PEFT(LoRA)配置适用于非量化的 LoRA:
peft_config = LoraConfig(
lora_alpha=8,
lora_dropout=0.05,
r=16,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
)修改后的完整 LoRA 微调脚本:
import logging
from dataclasses import dataclass, field
import os
import random
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, TrainingArguments
from trl.commands.cli_utils import TrlParser
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
set_seed,
)
from trl import setup_chat_format
from peft import LoraConfig
from trl import SFTTrainer
LLAMA_3_CHAT_TEMPLATE = (
"{% for message in messages %}"
"{% if message['role'] == 'system' %}"
"{{ message['content'] }}"
"{% elif message['role'] == 'user' %}"
"{{ '\n\nHuman: ' + message['content'] + eos_token }}"
"{% elif message['role'] == 'assistant' %}"
"{{ '\n\nAssistant: ' + message['content'] + eos_token }}"
"{% endif %}"
"{% endfor %}"
"{% if add_generation_prompt %}"
"{{ '\n\nAssistant: ' }}"
"{% endif %}"
)
@dataclass
class ScriptArguments:
dataset_path: str = field(
default=None,
metadata={
"help": "Path to the dataset"
},
)
model_id: str = field(
default=None, metadata={"help": "Model ID to use for SFT training"}
)
max_seq_length: int = field(
default=512, metadata={"help": "The maximum sequence length for SFT Trainer"}
)
def training_function(script_args, training_args):
################
# Dataset
################
train_dataset = load_dataset(
"json",
data_files=os.path.join(script_args.dataset_path, "train_dataset.json"),
split="train",
)
test_dataset = load_dataset(
"json",
data_files=os.path.join(script_args.dataset_path, "test_dataset.json"),
split="train",
)
################
# Model & Tokenizer
################
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(script_args.model_id, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.chat_template = LLAMA_3_CHAT_TEMPLATE
# template dataset
def template_dataset(examples):
return{"text": tokenizer.apply_chat_template(examples["messages"], tokenize=False)}
train_dataset = train_dataset.map(template_dataset, remove_columns=["messages"])
test_dataset = test_dataset.map(template_dataset, remove_columns=["messages"])
# print random sample
with training_args.main_process_first(
desc="Log a few random samples from the processed training set"
):
for index in random.sample(range(len(train_dataset)), 2):
print(train_dataset[index]["text"])
# Model
torch_dtype = torch.float16 # Change to float16 if hardware supports, or float32
quant_storage_dtype = torch.float16 # Similarly, change dtype as needed
model = AutoModelForCausalLM.from_pretrained(
script_args.model_id,
attn_implementation="sdpa", # use sdpa, alternatively use "flash_attention_2"
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
################
# PEFT
################
peft_config = LoraConfig(
lora_alpha=8,
lora_dropout=0.05,
r=16,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
)
################
# Training
################
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
dataset_text_field="text",
eval_dataset=test_dataset,
peft_config=peft_config,
max_seq_length=script_args.max_seq_length,
tokenizer=tokenizer,
packing=True,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
},
)
if trainer.accelerator.is_main_process:
trainer.model.print_trainable_parameters()
##########################
# Train model
##########################
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
trainer.train(resume_from_checkpoint=checkpoint)
##########################
# SAVE MODEL FOR SAGEMAKER
##########################
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model()
if __name__ == "__main__":
parser = TrlParser((ScriptArguments, TrainingArguments))
script_args, training_args = parser.parse_args_and_config()
# set use reentrant to False
if training_args.gradient_checkpointing:
training_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
# set seed
set_seed(training_args.seed)
# launch training
training_function(script_args, training_args)修改 YAML 配置
移除与量化相关的设置,并调整模型加载方式:
# script parameters
model_id: "/mnt/public/models/Meta-Llama-3-70B" # Hugging Face model id
dataset_path: "/mnt/public/no_robots" # path to dataset
max_seq_len: 3072 # max sequence length for model and packing of the dataset
# training parameters
output_dir: "./llama-3-70b-hf-no-robot-lora" # Temporary output directory for model checkpoints
report_to: "tensorboard" # report metrics to tensorboard
learning_rate: 0.0002 # learning rate 2e-4
lr_scheduler_type: "constant" # learning rate scheduler
num_train_epochs: 1 # number of training epochs
per_device_train_batch_size: 1 # batch size per device during training
per_device_eval_batch_size: 1 # batch size for evaluation
gradient_accumulation_steps: 2 # number of steps before performing a backward/update pass
optim: adamw_torch # use torch adamw optimizer
logging_steps: 10 # log every 10 steps
save_strategy: epoch # save checkpoint every epoch
evaluation_strategy: epoch # evaluate every epoch
max_grad_norm: 0.3 # max gradient norm
warmup_ratio: 0.03 # warmup ratio
bf16: true # use bfloat16 precision if hardware supports
tf32: true # use tf32 precision if hardware supports
gradient_checkpointing: true # use gradient checkpointing to save memory
# FSDP parameters: https://huggingface.co/docs/transformers/main/en/fsdp
fsdp: "full_shard auto_wrap" # Add offload if not enough GPU memory
fsdp_config:
backward_prefetch: "backward_pre"
forward_prefetch: "false"
use_orig_params: "false"查看训练过程数据
在智算云平台的任务列表页面,找到需要查看的任务。
TensorBoard 日志
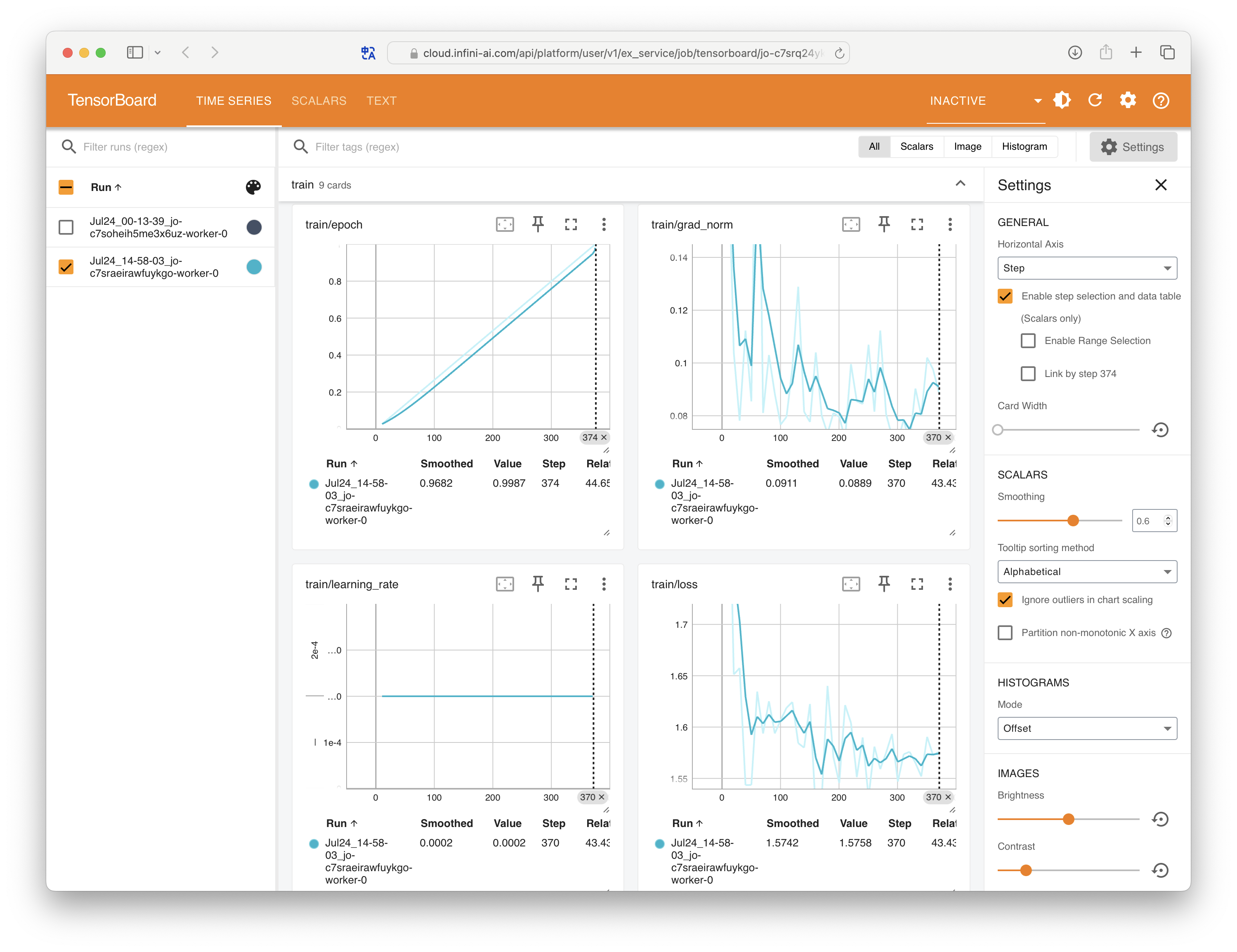
我们在提交训练任务时已经启用了任务可视化。在训练运行过程中,可通过任务详情页的 跳转 TensorBoard 按钮打开 TensorBoard 界面。
注意
TensorBoard 界面仅在训练运行过程中可用。如需持久化保存,可写入共享高性能存储。
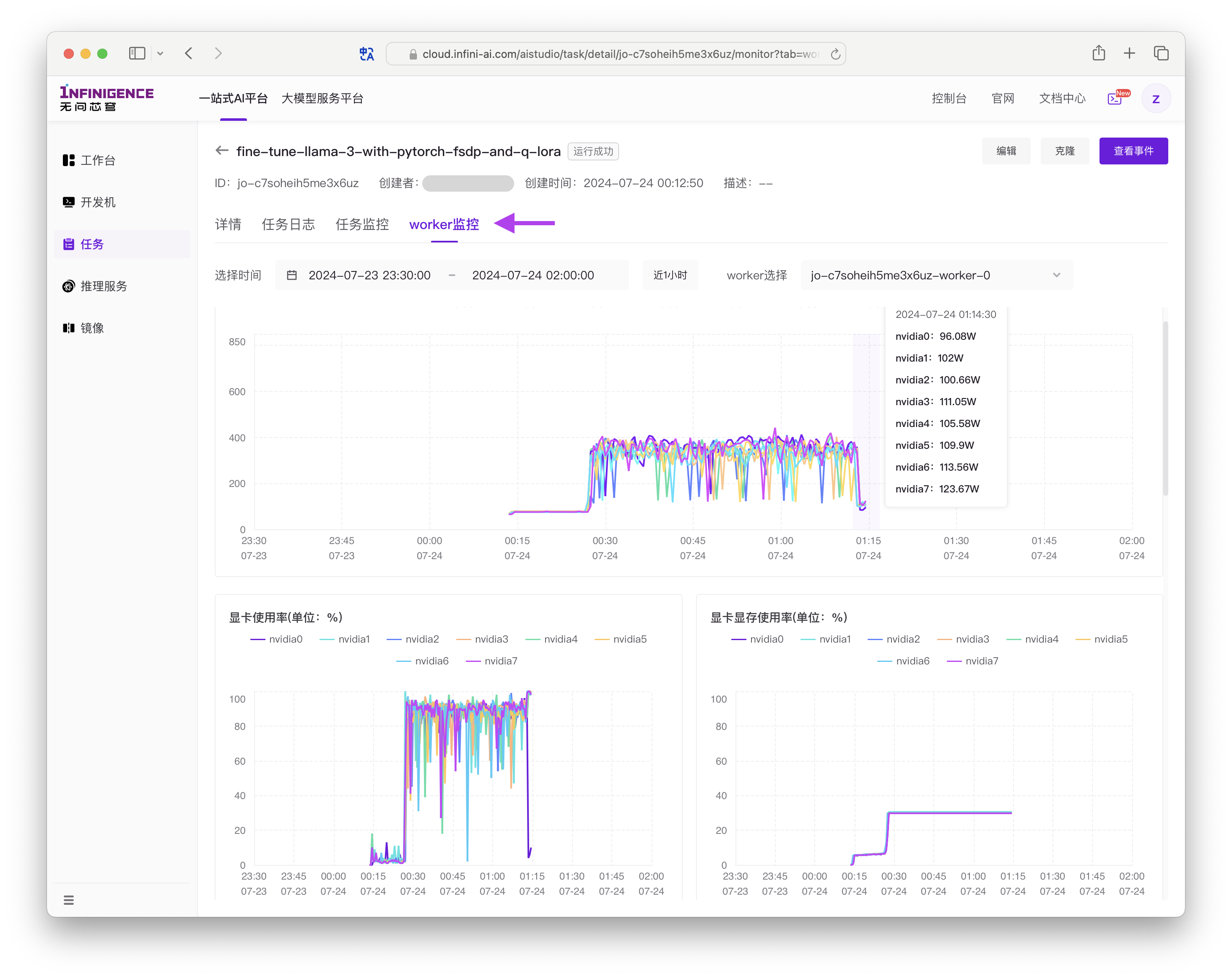
资源用量
在任务详情页切换不同标签页,可查看训练代码输出的日志、资源用量数据等。
预期显存用量
- FSDP + LoRA 需要约 8x80GB GPUs
- FSDP + Q-Lora 需要约 2x40GB GPUs
- 使用 FSDP 进行完全微调需要约 16x80GB GPUs
- FSDP + Q-Lora + CPU 卸载需要 4x24GB GPUs,每个 GPU 22 GB,CPU RAM 127 GB,序列长度 3072,批量大小为 1。
在 A100 x 8 上的任务中,使用 Flash Attention 训练 Llama 3 70B 模型 1 个 epoch,数据集为 10k 个样本:
- Q-LoRA 需时 30 分钟。
- LoRA 需时 1 小时。
参考资料
- 本教程基于 Hugging Face 技术主管 Philipp Schmid Efficiently fine-tune Llama 3 with PyTorch FSDP and Q-Lora
- Hugging Face Accelerate 两个后端的故事:FSDP 与 DeepSpeed
- 使用 PyTorch FSDP(完全分片数据并行)技术加速大模型训练