

预置模型列表
大模型服务平台(GenStudio)预置了来源于诸多厂商的主流系列模型。
访问模型广场
模型广场页面集中展示大模型服务平台(GenStudio)预置的模型。您可以通过模型广场顶部与左侧的标签筛选模型。每个预置大模型均以卡片的形式呈现。
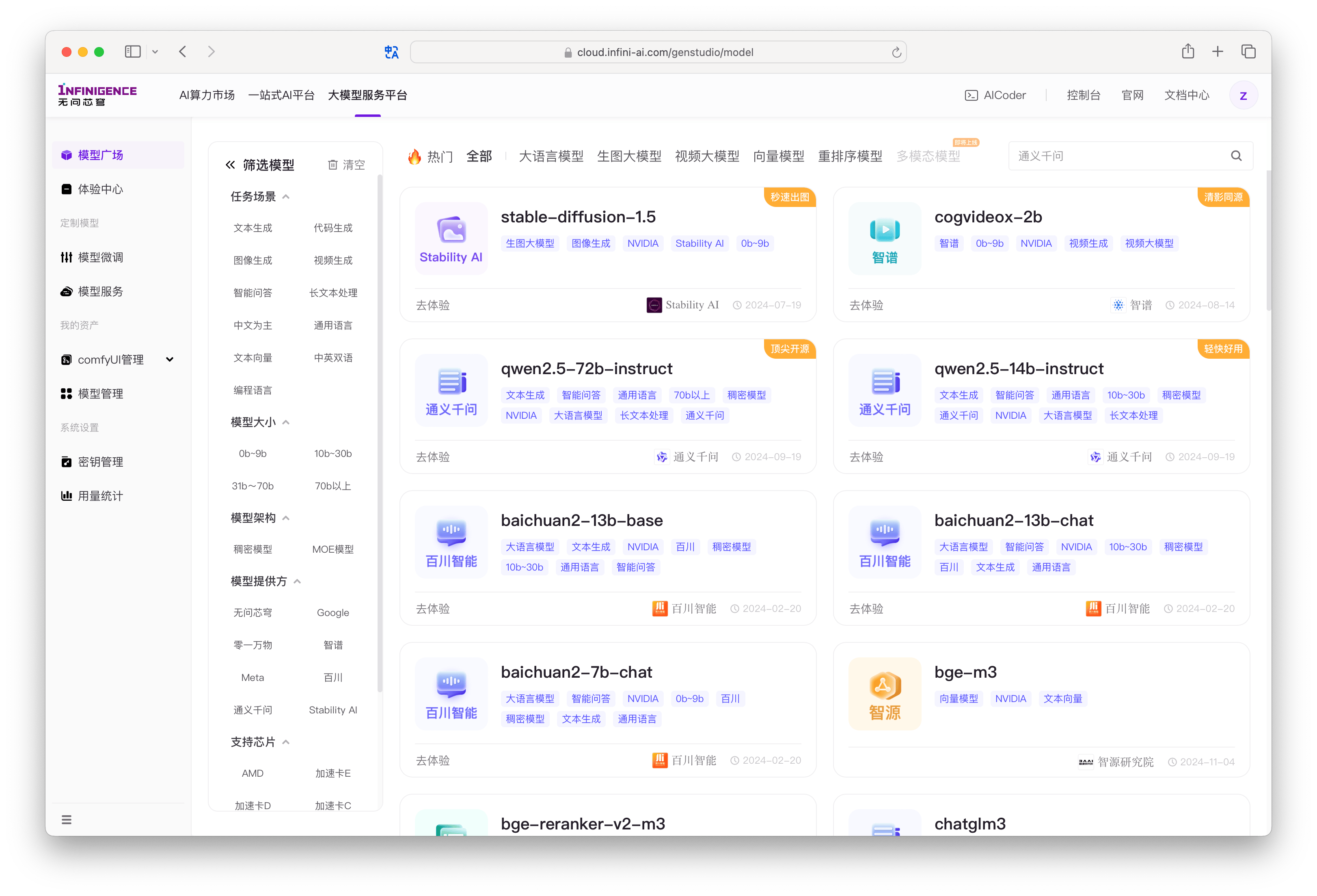
模型名称一般与模型厂商命名保持一致。您可以从模型卡片标签中直接查看模型所属厂商、支持的芯片、适用场景、上下文长度等信息。
模型卡片左下角可能带有以下便捷入口:
- 可体验:可直接进入体验中心,开启互动体验,例如对话、生成图像、生成视频等。大语言模型支持配置 System Prompt 和其他参数。图像和视频模型暂仅支持随机预置提示词,可修改基本参数。
- 可微调:支持 GenStudio 快捷微调服务。详见模型微调
点击模型卡片进入详情页,可查看模型介绍、上下文长度、评测数据等(评测数据来自于模型发布方)。如果该预置模型提供 API 服务,将提供调用说明、调用示例等。
大语言模型
DeepSeek
deepseek-r1-distill-qwen-32b开源
DeepSeek-R1-Distill-Qwen-32B 是基于 DeepSeek-R1 蒸馏而来的模型,在 Qwen2.5-32B 的基础上使用 DeepSeek-R1 生成的样本进行微调。该模型在各种基准测试中表现出色,保持了强大的推理能力。
模型亮点
- 类型:蒸馏语言模型
- 基础模型:Qwen2.5-32B
- 参数规模:328亿
- 张量类型:BF16
- 推荐温度参数:0.5-0.7
aime_2024_pass@1
72.6
aime_2024_cons@64
83.3
math500_pass@1
94.3
gpqa_diamond_pass@1
62.1
livecodebench_pass@1
57.2
codeforces_rating
1691
deepseek-r1开源
DeepSeek-R1 是一个专注于推理能力的大语言模型,通过创新的训练流程实现了与 OpenAI-o1 相当的数学、代码和推理任务表现。该模型采用了冷启动数据和大规模强化学习相结合的方式进行训练。
NOTE
使用建议:1. 为获得预期性能,使用 DeepSeek-R1 系列模型(包括基准测试)时,建议将 temperature 参数设置在 0.5-0.7 之间(推荐 0.6),以防止无限重复或输出不连贯。2. 避免添加系统提示词 (system prompt),所有指令应包含在用户提示词 (user prompt) 中。3. 对于数学问题,建议在提示词中包含类似这样的指令:'请逐步推理,并将最终答案放在\boxed{}中。' 4. 评估模型性能时,建议进行多次测试并取平均值。
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE
模型亮点
mmlu
90.8
mmlu-redux
92.9
mmlu-pro
84.0
drop
92.2
if-eval
83.3
gpqa-diamond
71.5
simpleqa
30.1
frames
82.5
alpacaeval2.0
87.6
arenahard
92.3
livecodebench
65.9
codeforces_percentile
96.3
codeforces_rating
2029
swe_verified
49.2
aider-polyglot
53.3
aime_2024
79.8
math-500
97.3
cnmo_2024
78.8
cluewsc
92.8
c-eval
91.8
c-simpleqa
63.7
NOTE
deepseek-v3开源
DeepSeek-V3 是一个强大的专家混合(MoE)语言模型,总参数量为 671B,每个 Token 激活 37B 参数。该模型采用多头潜在注意力(MLA)和 DeepSeekMoE 架构,实现了高效推理和经济训练。
NOTE
此模型的使用受许可协议的约束。请查看提供的链接了解相关协议。
https://huggingface.co/deepseek-ai/DeepSeek-V3/blob/main/LICENSE-MODEL
模型亮点
bbh
87.5
mmlu
87.1
mmlu-redux
86.2
mmlu-pro
64.4
drop
89.0
arc-easy
98.9
arc-challenge
95.3
hellaswag
88.9
piqa
84.7
winogrande
84.9
race-middle
67.1
race-high
51.3
triviaqa
82.9
naturalquestions
40.0
agieval
79.6
humaneval
65.2
mbpp
75.4
livecodebench-base
19.4
cruxeval-i
67.3
cruxeval-o
69.8
gsm8k
89.3
math
61.6
mgsm
79.8
cmath
90.7
cluewsc
82.7
c-eval
90.1
cmmlu
88.8
cmrc
76.3
c3
78.6
ccpm
92.0
mmmlu-non-english
79.4
NOTE
Gemma 2
gemma-2-27b-it开源申请试用
Gemma 是谷歌推出的一系列轻量级、尖端的开源模型,它们基于与 Gemini 模型相同的研究和技术构建。Gemma 是支持文本、输入文本输出的 decoder-only 大语言模型,除了英文本身,也支持包括中文的多种语言,并支持基础版本和指令调优的版本。
模型亮点
gemma-2-27b-it 是 270 亿参数规模的对话模型,基于 RLHF(强化学习与人类反馈)方法进行了训练,使模型在生成质量、编码能力、事实性、指令遵循和多轮对话质量等多方面上获得了显著提升。
mmlu
75.2 (5-shot, top-1)
hellaswag
86.4 (10-shot)
piqa
83.2 (0-shot)
socialiqa
53.7 (0-shot)
boolq
84.8 (0-shot)
winogrande
83.7 (partial score)
arc-e
88.6 (0-shot)
arc-c
71.4 (25-shot)
triviaqa
83.7 (5-shot)
natural questions
34.5 (5-shot)
humaneval
51.8 (pass@1)
mbpp
62.6 (3-shot)
gsm8k
74.0 (5-shot, maj@1)
math
42.3 (4-shot)
agieval
55.1 (3-5-shot)
big-bench
74.9 (3-shot, CoT)
NOTE
LLaMA 3.3
llama-3.3-70b-instruct开源申请试用
Meta 发布的 LLaMA 3.3 多语言大规模语言模型(LLMs)是一个经过预训练和指令微调的生成模型,提供 70B 规模(文本输入/文本输出)。该模型使用超过 15T 的数据进行训练,支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,知识更新截止于 2023 年 12 月。
NOTE
LLaMA3 系列模型需要申请试用。模型使用受 Meta 许可协议的约束。请在下方查看相关的协议内容。
https://huggingface.co/meta-llama/Meta-Llama-3.1-70B/blob/main/LICENSE
模型亮点
LLaMA 3.3 的指令微调文本模型(70B)专为多语言对话场景优化,并在许多常见行业基准测试中表现优于现有的开源和闭源聊天模型。
MMLU
83.6
MMLU (CoT)
86.0
MMLU-Pro (CoT)
68.9
IFEval
92.1
ARC-C
94.8
GPQA
50.5
HumanEval
88.4
MBPP ++ base version
87.6
Multipl-E HumanEval
65.5
Multipl-E MBPP
62.0
GSM-8K (CoT)
95.1
MATH (CoT)
77.0
API-Bank
90.0
BFCL
77.3
Gorilla Benchmark API Bench
29.7
Nexus (0-shot)
56.7
Multilingual MGSM (CoT)
91.1
LLaMA 3.1
llama-3.1-70b-instruct开源申请试用
Meta 发布的 LLaMA 3.1 多语言大规模语言模型(LLMs)包含预训练和指令微调生成模型,提供 8B、70B 和 405B 三种规模(文本输入/文本输出)。该模型使用 15T 的数据进行训练,知识更新截止于 2023 年 12 月。
NOTE
LLaMA3 系列模型需要申请试用。模型使用受 Meta 许可协议的约束。请在下方查看相关的协议内容。
https://huggingface.co/meta-llama/Meta-Llama-3.1-70B/blob/main/LICENSE
模型亮点
LLaMA 3.1 的指令微调文本模型(8B、70B、405B)专为多语言对话场景优化,并在许多常见行业基准测试中表现优于现有的开源和闭源聊天模型。
MMLU
83.6
MMLU (CoT)
86.0
MMLU-Pro (CoT)
66.4
IFEval
87.5
ARC-C
94.8
GPQA
41.7
HumanEval
80.5
MBPP ++ base version
86.0
Multipl-E HumanEval
65.5
Multipl-E MBPP
62.0
GSM-8K (CoT)
95.1
MATH (CoT)
68.0
API-Bank
90.0
BFCL
84.8
Gorilla Benchmark API Bench
29.7
Nexus (0-shot)
56.7
Multilingual MGSM (CoT)
86.9
LLaMA 3
llama-3-8b-instruct开源申请试用
Llama3 系列是由 Meta 开发的 Llama 系列全新的第三代版本,包含一系列预训练和指令调优的文本生成式模型。Llama3 基于优化后的 Transformer 架构,预训练过程中使用了超过 15T tokens 的数据,调优后的模型使用 SFT 和 RLHF,以更好地贴合人类对可用性和安全性的偏好。
模型亮点
Llama3-8b-Instruct 是此系列里 80 亿参数的指令调优的模型,针对对话场景用例进行了优化,并在常见的行业基准测试中超越了许多可用的开源聊天模型。Llama3-8b-Instruct 模型的数据的知识截止日期为 2023 年 3 月。
mmlu
68.4(5-shot)
gpqa
34.2(0-shot)
humaneval
62.2(0-shot)
gsm8k
79.6(8-shot,cot)
math
30(4-shot,cot)
llama-3-infini-8b-instruct闭源申请试用
Llama3-Infini-8B-Instruct 是无问芯穹推出的 Llama3-8b-Instruct 中文增强版本,旨在更好地服务中文语言环境的需求。
模型亮点
为了更好地服务中文语言环境的需求,我们首先对原有的 Llama3-8b-base 模型进行了继续训练,数据精选自多种高质量中文资源,包括百科全书、书籍、互联网通用语料,以及代码、数学和逻辑推理等领域,确保模型训练的全面性和深度。值得一提的是,为了增强模型的指令跟随能力,我们特别加入了大量的对话和指令类型数据。继续训练完成后,我们进一步使用了高质量对话数据进行特定的微调,最终形成了一款专门针对中文优化的对话模型。
mmlu
68.4(5-shot)
gpqa
34.2(0-shot)
humaneval
62.2(0-shot)
gsm8k
79.6(8-shot,cot)
math
30(4-shot,cot)
Yi 1.5
yi-1.5-34b-chat开源
Yi-1.5 是 Yi 的升级版本。 它使用 500B Tokens 的高质量语料库在 Yi 上持续进行预训练,并在 3M 个多样化的微调样本上进行微调。
模型亮点
与 Yi 相比,Yi-1.5 在编程、数学、推理和指令执行能力方面表现更为出色,同时仍然保持了在语言理解、常识推理和阅读理解方面的卓越能力。
mmlu
76.8
gsm8k
90.2
math
50.1
humaneval
75.2
mbpp
74.6
mt-bench
8.5
alignbench
7.2
arenahard
42.6
alpacaeval2.0
36.6
GLM 4
glm-4-9b-chat开源
GLM-4-9B-Chat 是智谱 AI 推出的最新一代预训练模型 GLM-4-9B 的人类偏好对齐版本。
NOTE
此模型的使用受智谱 AI 许可协议的约束。请在下方查看相关的协议内容。
https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/file/view/master?fileName=LICENSE&status=0
模型亮点
在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B-Chat 表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。
alignbench
7.01
mt-bench
8.35
ifeval
69.0
mmlu
72.4
c-eval
75.6
gsm8k
79.6
math
50.6
humaneval
71.8
natualcodebench
32.2
ChatGLM 3
chatglm3-6b-base开源可以微调
ChatGLM3-6b-base 是由智谱开发的 ChatGLM 系列最新一代的 60 亿参数规模的开源的基础模型。
NOTE
模型使用受智谱 AI 许可协议的约束。请在下方查看相关的协议内容。
模型亮点
ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略,更适合于复杂场景的微调后使用。
gsm8k
72.3
math
25.7
bbh
66.1
mmlu
61.4
c-eval
69
cmmlu
67.5
mbpp
52.4
agieval
53.7
avarage_longbench
50.2
summary_longbench
26.2
single_doc_qa_longbench
45.8
multi_doc_qa_longbench
46.1
code_longbench
56.2
few_shot_longbench
61.2
synthetic_longbench
65
NOTE
chatglm3闭源
ChatGLM3 是智谱 AI 与清华 KEG 实验室发布的闭源模型,经过海量中英标识符的预训练与人类偏好对齐训练,相比一代模型在 MMLU、C-Eval、GSM8K 分别取得了 16%、36%、280% 的提升,并登顶中文任务榜单 C-Eval。适用于对知识量、推理能力、创造力要求较高的场景,比如广告文案、小说写作、知识类写作、代码生成等。
NOTE
此模型为闭源模型,无官方评测数据。以下提供 ChatGLM3-6B-Base 的评测数据,仅供参考。
gsm8k
72.3
math
25.7
bbh
66.1
mmlu
61.4
c-eval
69
cmmlu
67.5
mbpp
52.4
agieval
53.7
NOTE
Megrez
megrez-3b-instruct开源
Megrez-3B-Instruct 是由无问芯穹完全自主训练的大语言模型。Megrez-3B-Instruct 旨在通过软硬协同理念,打造一款极速推理、小巧精悍、极易上手的端侧智能解决方案。
模型亮点
- 高精度:Megrez-3B-Instruct 虽然参数规模只有 3B,但通过数据质量的本质提升,成功弥合了模型性能代差,将上一代 14B 模型的能力高度压缩至 3B 大小,在主流榜单上取得了优秀的性能表现。
- 高速度:模型小≠速度快。Megrez-3B-Instruct 通过软硬协同优化,确保了各结构参数与主流硬件高度适配,最大推理速度领先同精度模型 300%。
- 简单易用:模型设计之初我们进行了激烈的讨论:应该在结构设计上留出更多软硬协同的空间(如 ReLU、稀疏化、更精简的结构等),还是使用经典结构便于直接用起来?我们选择了后者,即采用最原始的 LLaMA2 结构,开发者无需任何修改便可将模型部署于各种平台,最小化二次开发复杂度。
- 丰富应用:我们提供了完整的 WebSearch 方案,相比 search_with_lepton,我们对模型进行了针对性训练,使模型可以自动决策搜索调用时机,并提供更好的总结效果。用户可以基于该功能构建属于自己的 Kimi 或 Perplexity,克服小模型常见的幻觉问题和知识储备不足的局限。
c-eval
81.4
cmmlu
74.5
mmlu
70.6
mmlu-pro
48.2
human-eval
62.2
mbpp
77.4
gsm8k
64.8
math
26.5
mt-bench
8.76
align-bench
6.91
Qwen 2.5
qwen2.5-7b-instruct开源
Qwen2.5 是 Qwen 大型语言模型系列的最新成果。Qwen2.5 发布了从 0.5 到 720 亿参数不等的基础语言模型及指令调优语言模型。Qwen2.5 相比 Qwen2 带来了以下改进:
- 显著增加知识量,在编程与数学领域的能力得到极大提升。
- 在遵循指令、生成长文本、理解结构化数据 (例如,表格) 以及生成结构化输出特别是 JSON 方面有显著提升。对系统提示的多样性更具韧性,增强了聊天机器人中的角色扮演实现和条件设定。
- 支持长上下文处理。
- 支持超过 29 种语言的多语言功能,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
NOTE
此模型的使用受许可协议的约束。请在下方查看相关的协议内容。
https://github.com/QwenLM/Qwen2.5?tab=readme-ov-file#license-agreement
模型亮点
指令调优的 7B Qwen2.5 模型特点如下:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 架构:带有 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏置的 transformers
- 参数数量:76.1 亿
- 非嵌入参数数量:65.3 亿
- 层数:28
- 注意力头数 (GQA):查询为 28,键值为 4
mmlu-pro
56.3
mmlu-redux
75.4
gpqa
36.4
math
75.5
gsm8k
91.6
humaneval
84.8
mbpp
79.2
multipl-e
70.4
livecodebench
28.7
livebench-0831
35.9
ifeval-strict-prompt
71.2
arena-hard
52.0
alignbench-v1.1
7.33
mtbench
8.75
NOTE
qwen2.5-14b-instruct开源
Qwen2.5 是 Qwen 大型语言模型系列的最新成果。Qwen2.5 发布了从 0.5 到 720 亿参数不等的基础语言模型及指令调优语言模型。Qwen2.5 相比 Qwen2 带来了以下改进:
- 显著增加知识量,在编程与数学领域的能力得到极大提升。
- 在遵循指令、生成长文本、理解结构化数据 (例如,表格) 以及生成结构化输出特别是 JSON 方面有显著提升。对系统提示的多样性更具韧性,增强了聊天机器人中的角色扮演实现和条件设定。
- 支持长上下文处理。
- 支持超过 29 种语言的多语言功能,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
NOTE
此模型的使用受许可协议的约束。请在下方查看相关的协议内容。
https://github.com/QwenLM/Qwen2.5?tab=readme-ov-file#license-agreement
模型亮点
指令调优的 14B Qwen2.5 模型特点如下:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 架构:带有 RoPE、SwiGLU、RMSNorm 及 Attention QKV 偏置的 transformers
- 参数数量:147 亿
- 非嵌入参数数量:131 亿
- 层数:48 层
- 注意力头数 (GQA):查询 (Q) 为 40,键值 (KV) 为 8
mmlu-pro
63.7
mmlu-redux
80.0
gpqa
45.5
math
80.0
gsm8k
94.8
humaneval
83.5
mbpp
82.0
multipl-e
72.8
livecodebench
42.6
livebench-0831
44.4
ifeval-strict-prompt
81.0
arena-hard
68.3
alignbench-v1.1
7.94
mtbench
8.88
NOTE
qwen2.5-32b-instruct开源
Qwen2.5 是 Qwen 大型语言模型系列的最新成果。Qwen2.5 发布了从 0.5 到 720 亿参数不等的基础语言模型及指令调优语言模型。Qwen2.5 相比 Qwen2 带来了以下改进:
- 显著增加知识量,在编程与数学领域的能力得到极大提升。
- 在遵循指令、生成长文本、理解结构化数据 (例如,表格) 以及生成结构化输出特别是 JSON 方面有显著提升。对系统提示的多样性更具韧性,增强了聊天机器人中的角色扮演实现和条件设定。
- 支持长上下文处理。
- 支持超过 29 种语言的多语言功能,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
模型亮点
指令调优的 32B Qwen2.5 模型特点如下:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 架构:采用 RoPE、SwiGLU、RMSNorm 及 Attention QKV 偏置的 transformers
- 参数数量:325 亿
- 非嵌入参数数量:310 亿
- 层数:64 层
- 注意力头数 (GQA):查询 (Q) 为 40,键值 (KV) 为 8
mmlu-pro
69.0
mmlu-redux
83.9
gpqa
49.5
math
83.1
gsm8k
95.9
humaneval
88.4
mbpp
84.0
multipl-e
75.4
livecodebench
51.2
livebench-0831
50.7
ifeval-strict-prompt
79.5
arena-hard
74.5
alignbench-v1.1
7.93
mtbench
9.20
NOTE
qwq-32b-preview开源可以微调
QwQ-32B-Preview 是由 Qwen 团队开发的一款实验性研究模型,专注于提升 AI 的推理能力。
模型亮点
32.5B 因果语言模型的规格如下:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 架构:采用 RoPE、SwiGLU、RMSNorm 及 Attention QKV 偏置的 transformers
- 参数数量:325 亿
- 非嵌入参数数量:310 亿
- 层数:64 层
- 注意力头数 (GQA):查询 (Q) 为 40,键值 (KV) 为 8
qwen2.5-72b-instruct开源
Qwen2.5 是 Qwen 大型语言模型系列的最新成果。Qwen2.5 发布了从 0.5 到 720 亿参数不等的基础语言模型及指令调优语言模型。Qwen2.5 相比 Qwen2 带来了以下改进:
- 显著增加知识量,在编程与数学领域的能力得到极大提升。
- 在遵循指令、生成长文本、理解结构化数据 (例如,表格) 以及生成结构化输出特别是 JSON 方面有显著提升。对系统提示的多样性更具韧性,增强了聊天机器人中的角色扮演实现和条件设定。
- 支持长上下文处理。
- 支持超过 29 种语言的多语言功能,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
模型亮点
指令调优的 720 亿参数 Qwen2.5 模型特点如下:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 架构:采用 RoPE、SwiGLU、RMSNorm 及 Attention QKV 偏置的 transformers
- 参数数量:727 亿
- 非嵌入参数数量:700 亿
- 层数:80 层
- 注意力头数 (GQA):查询 (Q) 为 64,键值 (KV) 为 8
mmlu-pro
71.1
mmlu-redux
86.8
gpqa
49.0
math
83.1
gsm8k
95.8
humaneval
86.6
mbpp
88.2
multipl-e
75.1
livecodebench
55.5
livebench-0831
52.3
ifeval-strict-prompt
84.1
arena-hard
81.2
alignbench-v1.1
8.16
mtbench
9.35
NOTE
Qwen 2
qwen2-7b-instruct开源
Qwen2 是 Qwen 团队推出的新一代大型语言模型系列。它基于 Transformer 架构,并采用 SwiGLU 激活函数、注意力 QKV 偏置(attention QKV bias)、群组查询注意力(group query attention)、滑动窗口注意力(mixture of sliding window attention)与全注意力的混合等技术。此外,Qwen 团队还改进了适应多种自然语言和代码的分词器。
NOTE
此模型的使用受许可协议的约束。请在下方查看相关的协议内容。
https://modelscope.cn/models/qwen/Qwen2-7B-Instruct/file/view/master?fileName=LICENSE&status=0
mmlu
70.5
gpqa
25.3
humaneval
79.9
mbpp
67.2
gsm8k
82.3
math
49.6
c-eval
77.2
qwen2-7b开源仅微调可以微调
Qwen2 是 Qwen 团队推出的新一代大型语言模型系列。它基于 Transformer 架构,并采用 SwiGLU 激活函数、注意力 QKV 偏置(attention QKV bias)、群组查询注意力(group query attention)、滑动窗口注意力(mixture of sliding window attention)与全注意力的混合等技术。此外,Qwen 团队还改进了适应多种自然语言和代码的分词器。
NOTE
此模型的使用受许可协议的约束。请在下方查看相关的协议内容。
https://modelscope.cn/models/qwen/Qwen2-7B/file/view/master?fileName=LICENSE&status=0
mmlu
70.3
gpqa
31.8
humaneval
51.2
mbpp
65.9
gsm8k
79.9
math
44.2
c-eval
83.2
cmmlu
83.9
qwen2-72b-instruct开源
Qwen2 是 Qwen 团队推出的新一代大型语言模型系列。它基于 Transformer 架构,并采用 SwiGLU 激活函数、注意力 QKV 偏置(attention QKV bias)、群组查询注意力(group query attention)、滑动窗口注意力(mixture of sliding window attention)与全注意力的混合等技术。此外,Qwen 团队还改进了适应多种自然语言和代码的分词器。
NOTE
此模型的使用受许可协议的约束。请在下方查看相关的协议内容。
https://modelscope.cn/models/qwen/Qwen2-72B-Instruct/file/view/master?fileName=LICENSE&status=0
mmlu
82.3
gpqa
42.4
humaneval
86.0
mbpp
52.2
gsm8k
91.1
math
59.7
c-eval
83.8
Qwen 1.5
qwen1.5-7b-chat开源可以微调
Qwen1.5 系列是 Qwen2 的 Beta 版本,是一个基于 Transformer 的仅解码语言模型,在海量数据上进行预训练。与之前发布的 Qwen 系列版本相比,Qwen1.5 系列 base 与 chat 模型均能支持多种语言,在整体聊天和基础能力上都得到了提升。
模型亮点
Qwen1.5-7b-chat 是其中专用于 chat 场景的 70 亿参数的主流大小模型。
mmlu
61
c-eval
74.1
gsm8k
62.5
math
20.3
humaneval
36
mbpp
37.4
bbh
40.2
cmmlu
73.1
qwen1.5-14b-chat开源可以微调
Qwen1.5 系列是 Qwen2 的 Beta 版本,是一个基于 Transformer 的仅解码语言模型,在海量数据上进行预训练。与之前发布的 Qwen 系列版本相比,Qwen1.5 系列 base 与 chat 模型均能支持多种语言,在整体聊天和基础能力上都得到了提升
模型亮点
Qwen1.5-14b-chat 是其中专用于 chat 场景的 140 亿参数的主流大小模型。
mmlu
67.6
c-eval
78.7
gsm8k
70.1
math
29.2
humaneval
37.8
mbpp
44
bbh
53.7
cmmlu
77.6
qwen1.5-32b-chat开源
Qwen1.5 系列是 Qwen2 的 Beta 版本,是一个基于 Transformer 的仅解码语言模型,在海量数据上进行预训练。与之前发布的 Qwen 系列版本相比,Qwen1.5 系列 base 与 chat 模型均能支持多种语言,在整体聊天和基础能力上都得到了提升
模型亮点
Qwen1.5-32b-chat 是其中专用于 chat 场景的 320 亿参数的大模型,较于 14b 模型在智能体场景更强,较于 72b 模型推理成本更低。
mmlu
73.4
c-eval
83.5
gsm8k
77.4
math
36.1
humaneval
73.2
mbpp
49.4
bbh
66.8
cmmlu
82.3
qwen1.5-72b-chat开源
Qwen1.5 系列是 Qwen2 的 Beta 版本,是一个基于 Transformer 的仅解码语言模型,在海量数据上进行预训练。与之前发布的 Qwen 系列版本相比,Qwen1.5 系列 base 与 chat 模型均能支持多种语言,在整体聊天和基础能力上都得到了提升
模型亮点
Qwen1.5-72b-chat 是其中专用于 chat 场景的 720 亿参数的大模型。
mmlu
77.5
c-eval
84.1
gsm8k
79.5
math
34.1
humaneval
41.5
mbpp
53.4
bbh
65.5
cmmlu
83.5
生图模型
Stable Diffusion
stable-diffusion-1.5开源申请试用
Stable Diffusion 是一种扩散式文本到图像生成模型,该模型使用 CLIP ViT-L/14 作为固定预训练文本编码器,能够根据任何文本输入生成照片级逼真的图像。
NOTE
使用此模型需遵循 Stability AI 许可协议。请查看相关的协议内容。
https://huggingface.co/spaces/CompVis/stable-diffusion-license
模型亮点
- 基于 v1.2 的权重初始化:v1.5 检查点基于 v1.2 权重初始化,并在 595k 步上进行了微调。
- 高分辨率支持:在 512x512 分辨率下进行训练,提升了图像细节和质量。
- 改进的无分类指导采样:通过 10% 的文本条件丢弃优化了无分类指导采样。
视频生成模型
CogVideoX
cogvideox-2b开源申请试用
CogVideoX 是由智谱开发并开源的最新的视频生成模型系列,与智谱清影为同源模型。该模型暂时仅支持输入英文提示词,可生成 720 * 480 的 6 秒视频,在人物高清特写,电影镜头等场景上都有不俗的表现。
NOTE
模型使用受智谱 AI 许可协议的约束。请在下方查看相关的协议内容。
https://www.modelscope.cn/models/ZhipuAI/CogVideoX-2b/file/view/master?fileName=LICENSE&status=1
模型亮点
- 与“清影”同源:CogVideoX-2b 与智谱 AI 之前推出的 AI 视频生成功能「清影」技术同源,继承了「清影」的高效指令遵循能力和内容连贯性 。
- 视频生成:提示词上限为 226 个 token,可通过控制镜头语言、景别角度、光影效果、主体、场景等因素,生成多样化的视频内容。
- 技术创新:自研高效的 3D VAE,配合3D RoPE 位置编码模块,更有利于在时间维度上捕捉帧间关系,建立起视频中的长程依赖。
模型总表
| Model ID | 模型厂商 | 模型类型 |
|---|---|---|
| bge-m3 | BAAI | 其他 |
| bge-reranker-v2-m3 | BAAI | 其他 |
| chatglm3-6b-base | 智谱 AI | 大语言模型 |
| chatglm3 | 智谱 AI | 大语言模型 |
| cogvideox-2b | 智谱 AI | 视频模型 |
| deepseek-r1-distill-qwen-32b | 深度求索 | 大语言模型 |
| deepseek-r1 | DeepSeek AI | 其他 |
| deepseek-v3 | DeepSeek AI | 其他 |
| gemma-2-27b-it | 大语言模型 | |
| glm-4-9b-chat | 智谱 AI | 大语言模型 |
| megrez-3b-instruct | 无问芯穹 | 大语言模型 |
| jina-embeddings-v2-base-code | Jina AI | 其他 |
| jina-embeddings-v2-base-zh | Jina AI | 其他 |
| llama-3-8b-instruct | Meta | 大语言模型 |
| llama-3-infini-8b-instruct | Meta | 大语言模型 |
| llama-3.1-70b-instruct | Meta | 大语言模型 |
| llama-3.3-70b-instruct | Meta | 大语言模型 |
| qwen2.5-7b-instruct | 阿里云 | 大语言模型 |
| qwen2.5-14b-instruct | 阿里云 | 大语言模型 |
| qwen2.5-32b-instruct | 阿里云 | 大语言模型 |
| qwq-32b-preview | 阿里云 | 大语言模型 |
| qwen2.5-72b-instruct | 阿里云 | 大语言模型 |
| qwen1.5-7b-chat | 阿里云 | 大语言模型 |
| qwen1.5-14b-chat | 阿里云 | 大语言模型 |
| qwen1.5-32b-chat | 阿里云 | 大语言模型 |
| qwen1.5-72b-chat | 阿里云 | 大语言模型 |
| qwen2-7b-instruct | 阿里云 | 大语言模型 |
| qwen2-72b-instruct | 阿里云 | 大语言模型 |
| stable-diffusion-1.5 | Runway ML | 图像模型 |
| yi-1.5-34b-chat | 零一万物 | 大语言模型 |