

在 AIStudio 开发机中安装 CosyVoice
CosyVoice 2.0 是一个多语言文本转语音模型,支持中文、英语、日语、韩语及多种中国方言。相比 1.0 版本,具有更高的准确性、稳定性和更快的语音生成能力。
安装 CosyVoice
以下安装步骤已为 AIStudio 开发机优化。
获取系统级 CUDA 环境
CosyVoice 的 requirements.txt 文件中依赖了 deepspeed。 Deepspeed 要求使用 nvcc,用于编译 C++/CUDA/HIP 扩展。因此,必须先安装系统级 CUDA 环境,否则后续安装 deepspeed 时会报错。
为求快捷,本教程将使用提前准备的用 Dockerfile 构建的镜像,其中 CUDA 版本为 12.2,cuDNN 版本为 9.X。
您可以用以下方式构建一个符合要求的 CUDA 环境镜像。
- 所需的 Dockerfile 请参见获取系统级 CUDA/cuDNN 环境中的「使用 Dockerfile 构建镜像」,建议使用可安装 CUDA 12.2.2 和 cuDNN 8.9.7 的 Dockerfile。
- 使用 Dockerfile 构建自定义镜像的步骤可参见构建自定义镜像。
提示
如果您不清楚什么是系统级 CUDA,请查看教程 NVIDIA CUDA Toolkit 与 PyTorch 安装中的 CUDA 的区别。
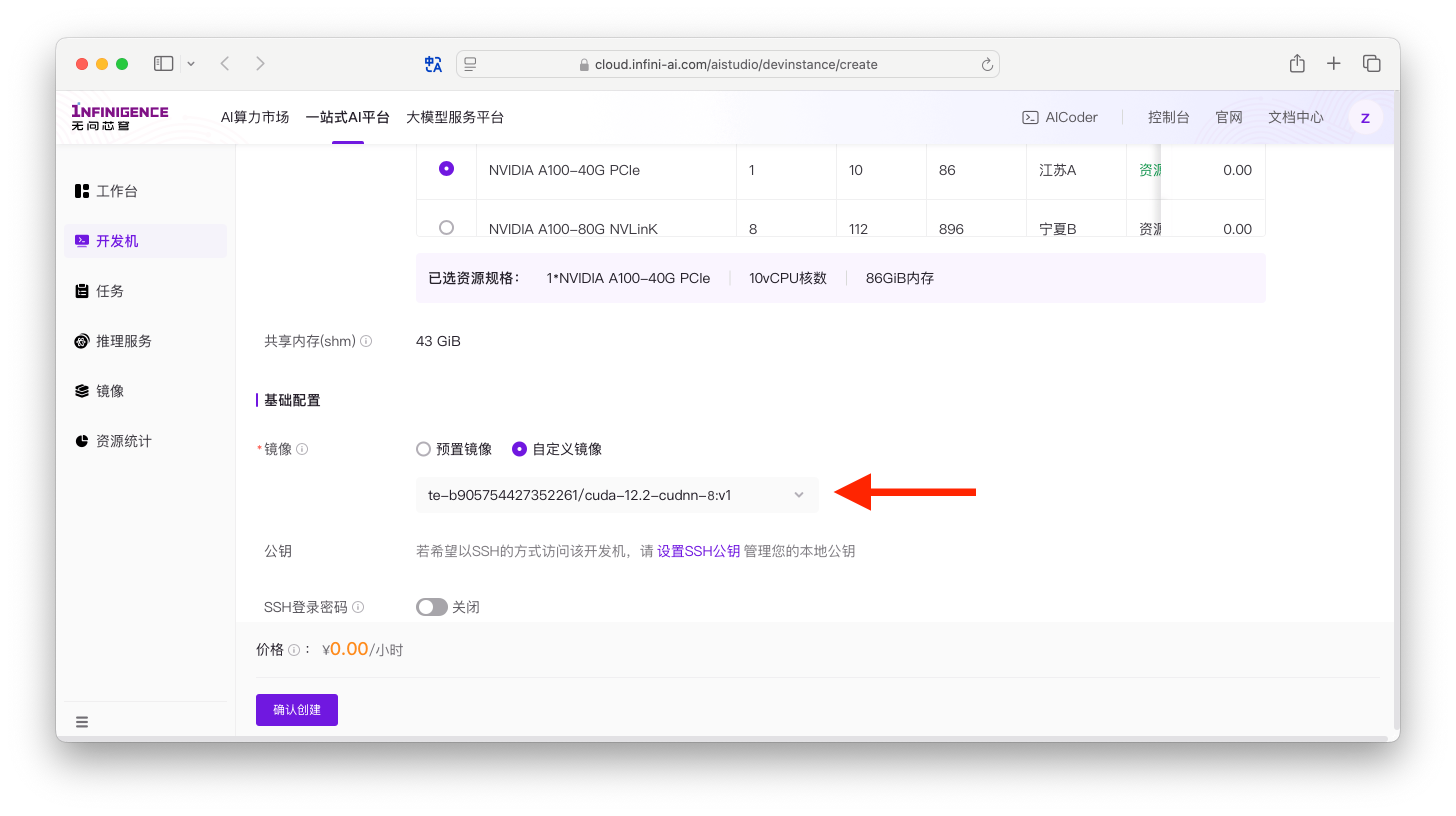
创建 AIStudio 开发机
点击下方链接,直接访问智算云控制台的创建开发机页面。
进入创建页面后,请根据页面提示,完成开发机相应配置。在选择镜像时,请务必选择您创建的自定义 CUDA 环境镜像。
克隆 Cosyvoice 代码仓库
由于 Cozyvoice 仓库含有 submodule,因此需要使用 GitHub 学术加速服务,分两步下载。
拉取 Cosyvoice 主仓库。
language-shellgit clone https://ghfast.top/https://github.com/FunAudioLLM/CosyVoice.git进入仓库主目录,修改 git submodule 的地址,添加学术加速服务的域名前缀。
language-shell# 进入仓库主目录 cd CosyVoice # 在 github.com 前添加学术加速服务的域名前缀 sed -i 's|https://github.com|https://ghfast.top/https://github.com|g' .gitmodules拉取仓库的 submodule。
language-shellgit submodule update --init --recursive
安装 Conda 环境和 pynini
根据 CosyVoice 的 README,使用 Conda 安装 pynini, 这是因为 Conda 提供预编译的二进制文件,方便管理平台相关的依赖,避免复杂的编译过程。
镜像中已预置了 Miniconda,但是需要先将 conda 添加到环境变量:
language-shellsource /usr/local/miniconda3/etc/profile.d/conda.sh && conda init执行完毕后关闭 Shell 会话。
新建 Shell 会话,创建 conda 环境
cosyvoice,并在环境中安装 pynini。language-shell# 创建 conda create -n cosyvoice python=3.10 # 激活 conda activate cosyvoice # 安装 conda install -y -c conda-forge pynini==2.1.5
加速安装 Pytorch
CosyVoice 的 requirements.txt 文件中依赖了 Pytorch 2.3.1 版本。如果您直接按照官方 README 安装方式安装依赖项,Pytorch 下载过程将会非常耗时。
建议使用以下方式加速下载 Pytorch 相关依赖。
python -m pip install torch==2.3.1 torchaudio==2.3.1 -f https://mirrors.aliyun.com/pytorch-wheels/cu121/信息
详见教程使用国内镜像加速安装 PyTorch。
安装 Python 依赖
镜像中已内置国内 pip 源,因此直接指定 requirements 文件即可,无需遵照 Cosyvoice README 中的方式指定 aliyun 镜像。
# 确保在 CosyVoice 目录下
python -m pip install -r requirements.txt体验 CosyVoice 2
在本次体验中,将使用 CosyVoice2 模型 iic/CosyVoice2-0.5B。
信息
强烈建议使用 VSCode Remote SSH 方式连接到开发机,可以更便于体验音频播放。
配置环境变量
export PYTHONPATH=third_party/Matcha-TTS下载预训练模型
下载 CosyVoice2 0.5B 模型 iic/CosyVoice2-0.5B。
在命令行界面直接执行 python 进入解释器,依次执行下列代码:
from modelscope import snapshot_download
# 下载主模型
snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')
# 下载 ttsfrd(下一个可选步骤中需要使用;不用可不下载该模型)
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')安装 ttsfrd(可选安装)
官方称 ttsfrd 可比 WeTextProcessing 提供更好的文本规范化性能。
cd pretrained_models/CosyVoice-ttsfrd/
unzip resource.zip -d .
python -m pip install ttsfrd_dependency-0.1-py3-none-any.whl
python -m pip install ttsfrd-0.4.2-cp310-cp310-linux_x86_64.whl体验合成语音示例
现在您已经完成了基础安装,可以开始使用 CosyVoice2 模型进行语音合成了。
在命令行界面直接执行 python 进入解释器,执行下列代码导入依赖。
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio创建 cosyvoice 实例。
cosyvoice = CosyVoice2('pretrained_models/CosyVoice2-0.5B', load_jit=False, load_trt=False, fp16=False)CosyVoice 仓库中预置了提供音色输入的音频文件 zero_shot_prompt.wav,预置音色文件的文本转写内容为 “希望你以后能够做的比我还好呦。”,也需要作为输入提供给模型。
以下使用仓库 README 中的实例生成音频文件。
# NOTE if you want to reproduce the results on https://funaudiollm.github.io/cosyvoice2, please add text_frontend=False during inference
# zero_shot usage
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)zero_shot_0.wav 为生成的目标文件。如果使用 VSCode 连接开发机,可以直接点击播放文件。
进阶体验
体验仿紫薇音色
为了完整体验 CosyVoice2 的音色复刻能力,我们准备了一个仿紫薇音色文件 ziwei-voice。文本转写内容为 "你不提御花园,我还会手下留情。你提起御花园。好,我就再赏你几针。"
以下使用仿紫薇音色生成音频文件。
prompt_speech_16k = load_wav('ziwei-voice.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('我们是一家专注于为 AI 2.0时代提供完整解决方案的科技公司。我们的愿景是"释放无穷算力,让AGI触手可及",致力于成为大模型落地过程中的"M×N"中间层,为中国乃至全球人工智能产业的发展注入新的动力。', '你不提御花园,我还会手下留情。你提起御花园。好,我就再赏你几针。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)zero_shot_0.wav 为生成的目标文件。如果使用 VSCode 连接开发机,可以直接点击播放文件。
使用 Web 界面
可以参考 CosyVoice 官方仓库 运行 Web Demo。
需要配合使用 SSH 端口转发实现在本地访问 Web 页面。
故障排查
如果遇到 modelscope 相关报错,请关注以下 issue:
- https://github.com/FunAudioLLM/CosyVoice/issues/28
- https://github.com/modelscope/modelscope/issues/894
modelscope 可以维持 1.15 版本,删除推理时生成的缓存文件 (~/.cache/modelscope/ast_indexer),重启服务即可解决。
警告
本教程截止至 2025 年 1 月 10 日。CosyVoice 的最新使用方式与依赖项以 CosyVoice 官方仓库为准。