

在沉浸式翻译中使用无问芯穹的 GenStudio API
沉浸式翻译是一款深受用户喜爱的双语对照网页翻译插件,无论是网页阅读、PDF翻译、电子书翻译还是视频字幕翻译,沉浸式翻译都能轻松搞定。
最近,GenStudio 推出了一系列性能强大、响应迅速的大语言模型,如 GLM-4 和 Qwen2。那么,如何将 GenStudio 与沉浸式翻译结合起来,提升你的翻译体验呢?
选择适用于翻译任务的模型
GenStudio 预置了的多种大语言模型。建议选择指令跟随能力出色的指令模型(Instruct)或聊天模型(Chat)。
例如:
glm-4-9b-chatqwen2.5-72b-instructqwen2.5-7b-instruct
其他 LLM 模型可参考 GenStudio 模型列表。
模型的表现取决于预训练数据中的语种多样性和翻译场景的数据覆盖。Instruct 模型通常强化了包括 Chat 在内的多类指令和指令跟随能力,在处理包含复杂规则的翻译 Prompt 时,Instruct 模型可能更具优势。但并非所有 Instruct 模型在翻译类任务中必然优于 Chat 模型,建议可多做尝试。
配置过程
安装插件:如果你还没有安装沉浸式翻译,请先在浏览器中添加该扩展。
设置接口:点击沉浸式翻译的扩展图标,找到设置选项,然后新增兼容 OpenAI 的自定义兼容接口。
添加 GenStudio 模型 API 信息:
- 自定义翻译服务名称:可以自由发挥,例如
qwen2.5-7b-instruct。 - 自定义 API 接口地址:访问无问芯穹的模型广场,从大语言模型详情页的调用说明中获取。一般选择默认接口即可。
- 默认接口:
https://cloud.infini-ai.com/maas/v1/chat/completions - M×N 推理服务 API 接口地址:
https://cloud.infini-ai.com/maas/qwen2.5-7b-instruct/nvidia/chat/completions
- 默认接口:
- APIKEY:从无问芯穹的 API 密钥管理页面获取。
- 模型名称:选择匹配的模型名称,如列表中不存在该模型,可输入自定义模型名称,如
qwen2.5-7b-instruct。 - 每秒最大请求数:建议设置为 0.2(受限于每分钟 12 次请求,高于 0.2 的值将导致 429 错误)。
- 每次请求最大文本长度:建议配置为 800 - 1000。表示每次请求的最大字符数,太大会导致接口的响应变慢,因此可以尝试调整该选项来优化速度。
- 每次请求最大段落数:建议配置为 3 - 10。表示每次发送给翻译服务的段落数量,段落数量过多可能会导致接口的响应变慢。
- 自定义翻译服务名称:可以自由发挥,例如
测试配置:点击右上角的测试按钮,看看配置是否成功。
以下是配置完成后的截图。
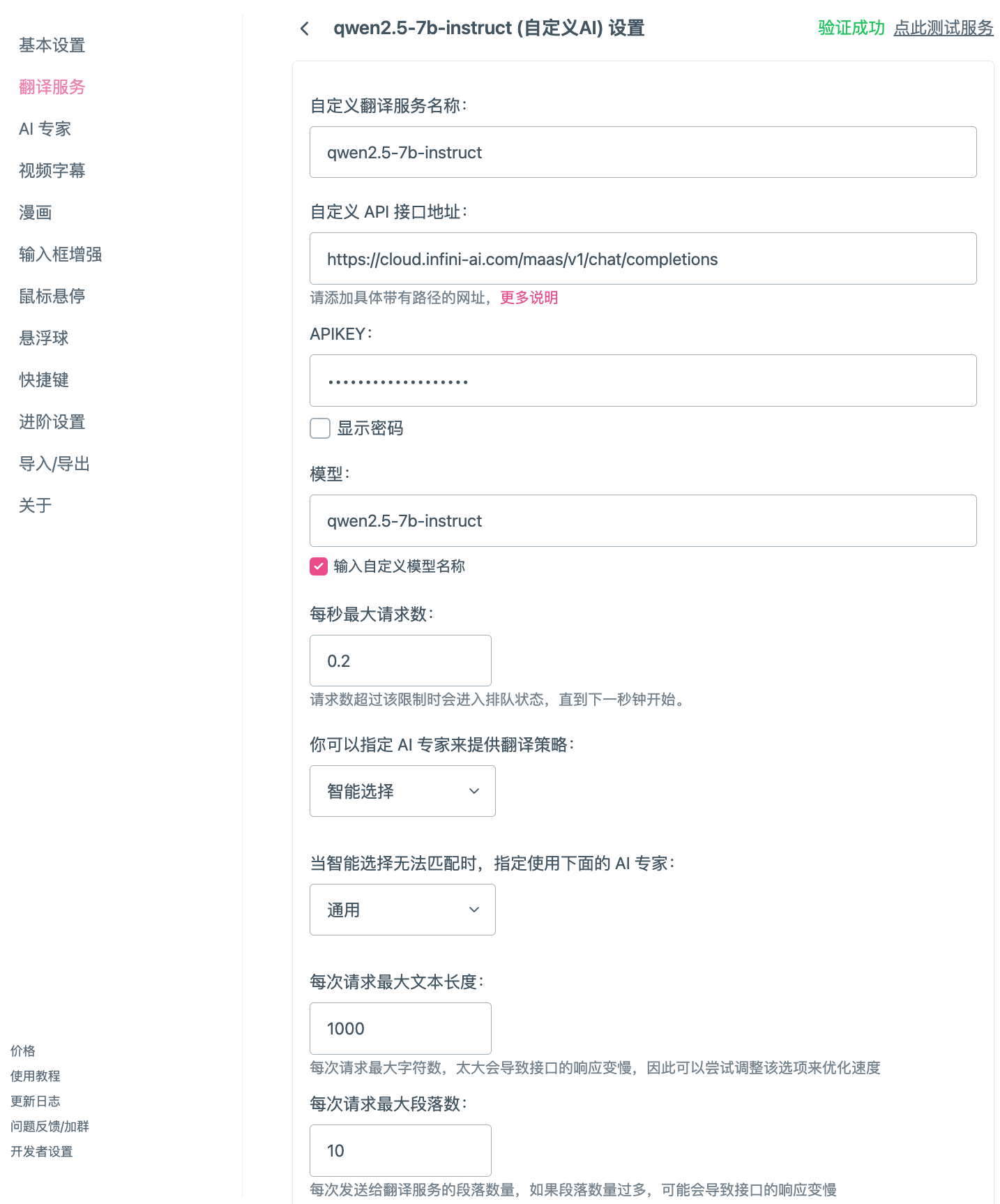
一切都配置完成后,不妨用下面这篇论文来测试一下效果:
完成这些步骤后,你就可以在沉浸式翻译插件中使用 GenStudio 的大语言模型进行翻译了。
GenStudio LLM API 服务限制
使用 GenStudio LLM API 时,受以下 API 频率限制约束:
- 每分钟请求次数 (RPM):12
- 每分钟Token数量 (TPM):12000
- 每天请求次数 (RPD):3000
在配置教程中,我们已根据 GenStudio API 频率限制进行了合理的配置。
提示
如需享受更高的 API 限频,欢迎联系商务或售后服务,洽谈购买相应服务。