

监控自部署模型服务
GenStudio 可提供自部署 LLM 推理业务的用量统计、性能表现、和流量变化等指标。
服务监控
进入模型服务的详情页,切换到服务监控标签页,可查看模型服务各项指标。模型服务级监控指标分为两类:
- 通用推理业务监控:提供每秒请求数、流量等推理业务通用指标。
- LLM 场景业务监控:提供 TTFT(生成首个 Token 的时间)、总 Token 数等 LLM 业务指标。
通用推理业务监控指标
默认每 30 秒获取一次数据。在监控指标图表展示时,平台会根据所选择的时间范围动态调整数据聚合粒度。
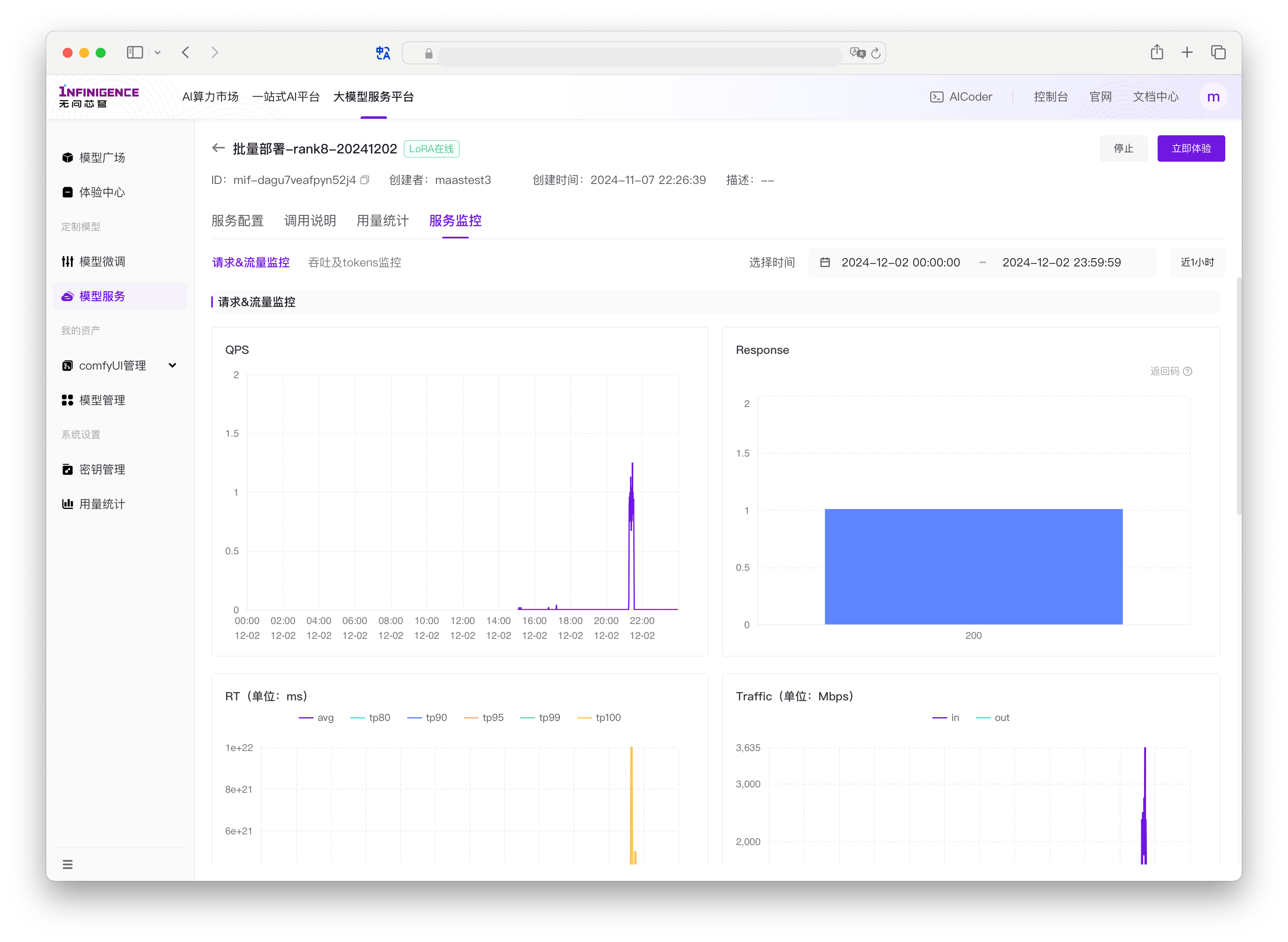
- QPS:每秒的请求数,按请求的 HTTP 返回码分类,在折线图中展示多条折线(所有实例的平均值)
- Response:请求总数,按请求的 HTTP 返回码分类,在直方图中展示各种 HTTP 返回码对应的请求总数量(所有实例的平均值)
- RT:请求的响应时间指标,包括平均响应时间和各个百分位数的响应时间(所有实例的平均值)
- avg:所有请求的平均响应时间(每段时间请求响应总时间/相应总数)
- tp80,tp90,tp95,,tp99,tp100:Top 百分位数,表示在时间范围(单位:ms)内完成响应的请求百分比。tp80 为 40 ms,表示响应速度前 80% 的请求在 40 ms 内完成。
注意
如果服务包含多个实例,tp 取所有实例的平均值。
- Traffic:服务接收和发出的流量大小,单位为字节每秒(所有实例的平均值)
大语言模型场景指标
模型服务监控提供了由 vLLM Metrics 直接采集的 LLM 业务指标。
- e2e_request_latency:vLLM 的端到端总延迟(所有实例的平均值)
- avg:所有请求的平均响应时间(每段时间请求响应总时间/相应总数)
- tp80,tp90,tp95,,tp99,tp100:Top 百分位数,表示在时间范围(单位:ms)内完成响应的请求百分比。tp80 为 40 ms,表示响应速度前 80% 的请求在 40 ms 内完成。
注意
如果服务包含多个实例,tp 取所有实例的平均值。
- Avg_Throughput:vLLM 的 prefill(输入)与 generation(输出)阶段的平均吞吐量(所有实例的平均值,单位 Tokens 每秒)
- TTFT:vLLM 的生成第一个词所需时间(单位:ms)(所有实例的平均值)
- Total_tokens:vLLM 处理请求的总 Token 数,按 prefill(输入)和 generation(输出)分别展示。
用量统计
进入模型服务的详情页,切换到用量统计标签页,可以查看当前自部署模型服务的调用统计信息,和模型训练的 Token 消耗量。
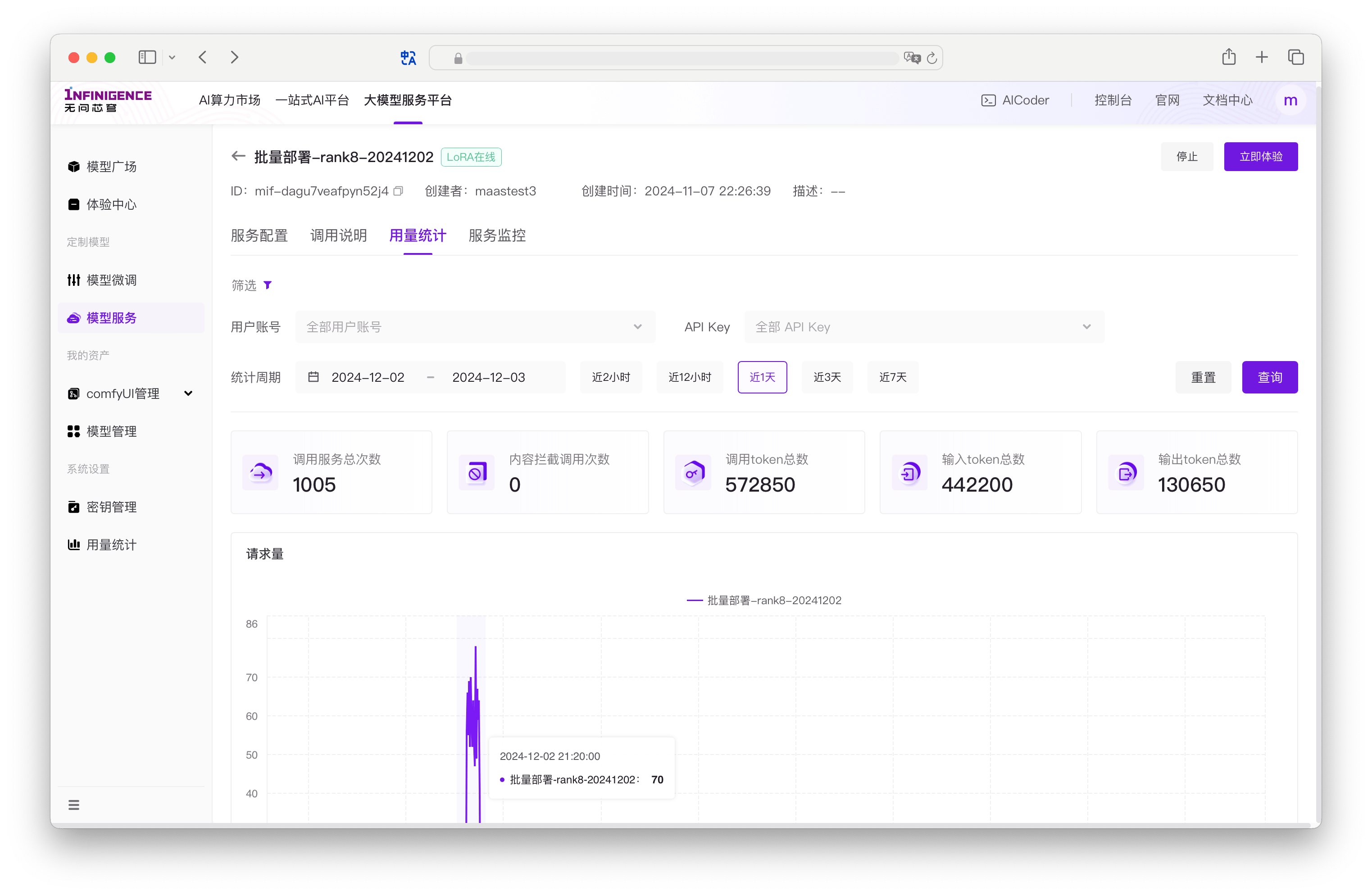
关于用量统计的详细说明,请移步用量统计
提示
用量统计标签页的数据可见范围由当前登录用户身份决定。
- 仅管理员可查看当前租户下所有用户的使用数据,可筛选用户账号。
- 非管理员用户仅可查看当前账号调用该模型的用量统计信息。