

在线体验
大模型服务平台(GenStudio)体验中心为多种前沿模型提供 Web 在线对话体验。
开启在线对话
GenStudio 体验中心支持在线配置 System Prompt、Temperature 等多种参数,并支持同时对比多模型输出效果。
进入体验中心。请确保顶部已切换为大语言模型。
在多模型对比体验模式下,您可直观体验不同模型和不同芯片对于同样的指令的返回差异。您可以在左侧调整各个模型的参数,不同模型支持的参数数量及范围均可能有差异。
警告
选中的模型不共享参数配置,例如 System Prompt、Temperature 等。如有需要,请逐个模型调整。
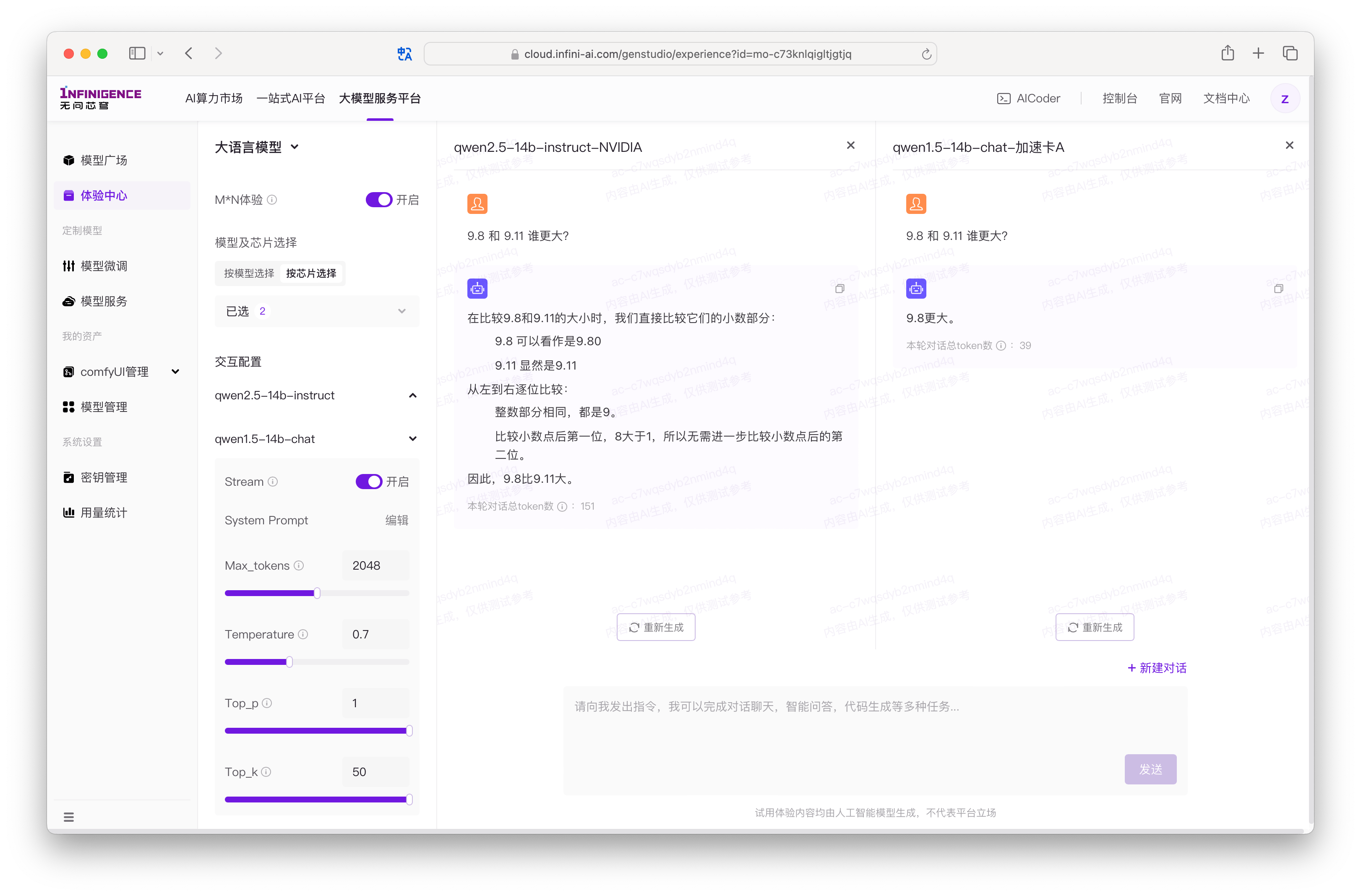
当模型完成或被停止生成后,可根据模型的回答情况,点击重新生成按钮,对之前所生成的最新一轮反馈进行重新生成。对模型已经完成输出生成的内容,平台会统计本轮对话所产生的输入与输出 Token 总和。
提示
当对比中的模型仍正在输出时,您无法进行新对话的发起或者输入下一轮的指令,当所有模型都完成内容返回时,则可以开启下一轮的对话对比。
大语言模型交互参数配置
体验大语言模型时,各个模型拥有独立的配置区域。因模型系列的不同,可能会支持不同的可配置参数。大语言模型主要的参数包括:
- Stream:指模型是否以流式返回回答的内容,默认开启,关闭时,将一次性返回此次生成的所有内容。
- System Prompt:指模型在回答问题时的系统提示,默认为空,您可以根据需要自行调整。
- Max_tokens:指模型输出的最大 Token 数量。模型输入与输出的 Token 数量将共享模型可处理的文本长度。
- Temperature:采样温度,控制输出的随机性。值越高,会使输出更加随机,更具创造性;值越低,会使输出更加集中和确定性。我们推荐您根据应用场景调整 top_p 或 temperature 参数,但不建议同时调整两个参数。
- Top_p:用于控制输出文本的随机性和多样性,取值越大,生成文本越丰富。我们推荐您根据应用场景调整 top_p 或 temperature 参数,但不建议同时调整两个参数。
- Top_k:用于控制输出文本的随机性和多样性(并非所有模型均支持),控制语言模型在生成文本时,从前 k 个 tokens 随机选择。1 适用于返回有明确答案的问题,例如 "5 乘以 7 等于多少?"
如果希望体验更完整的参数配置,建议使用 GenStudio API 文档中的调试面板。
📋 大模型服务平台 API 参考文档
获取 API 调用信息
大模型服务平台(GenStudio)提供了专用的多模型芯片(M×N)推理 API 端点。使用方法参考 GenStudio M×N 推理服务 API 使用教程。
在模型广场点击模型卡片后,切换到调用说明标签页面,可一键复制当前模型的调用示例。
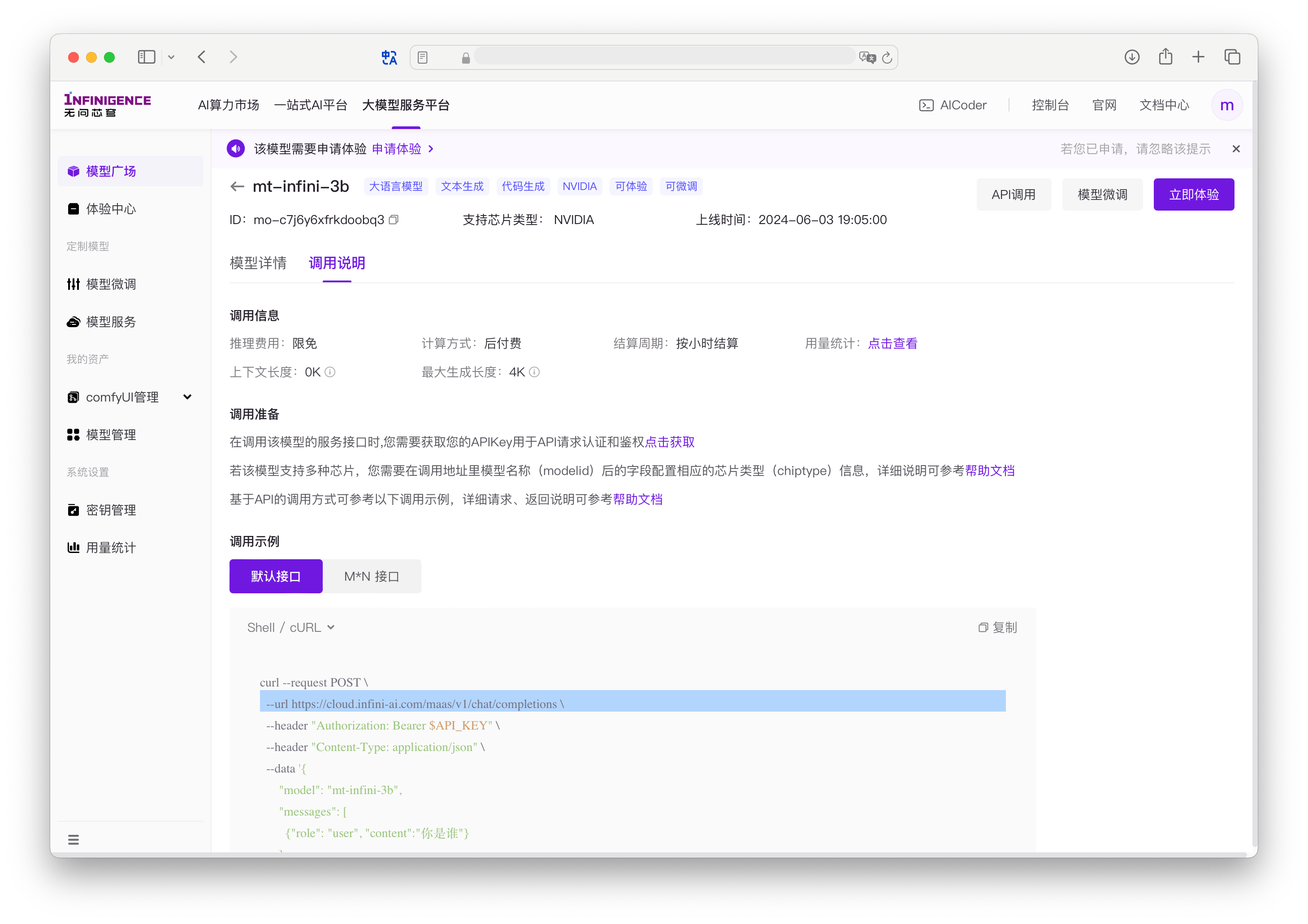
查看模型调用详情
进入模型详情页后,切换至调用详情页签,即可查看当前模型的专属用量数据。
此页面复用了用量统计页面中大语言模型页签的功能布局,展示当前模型的服务调用总次数、失败数、Token 消耗(输入/输出)等关键指标。详细字段说明请参考 API 用量统计。