

无问芯穹一站式 AI 平台(AIStudio)入门指导
欢迎使用一站式 AI 平台 AIStudio!
本文面向初次使用 「包年包月资源」 的客户,介绍如何使用一站式 AI 平台,体验开发、训练和推理功能。
注意
- 关于包年包月资源的详细价格信息,请点击 AIStudio 价格。
- 如果您使用「弹性资源」创建开发机,请移步 AIStudio 按量付费型开发机快速入门。
平台账号
获取智算云平台的登录账号和资源,体验 AIStudio 的开发、训练和推理功能。
如果已获取平台账号,可点击下方链接,直达 AIStudio 的 Web 控制台。
如果您已自行注册账号,可联系商务人员,为您的账号分配资源。
联系电话 400-806-6058
诚邀您持续关注我们:

首次登录
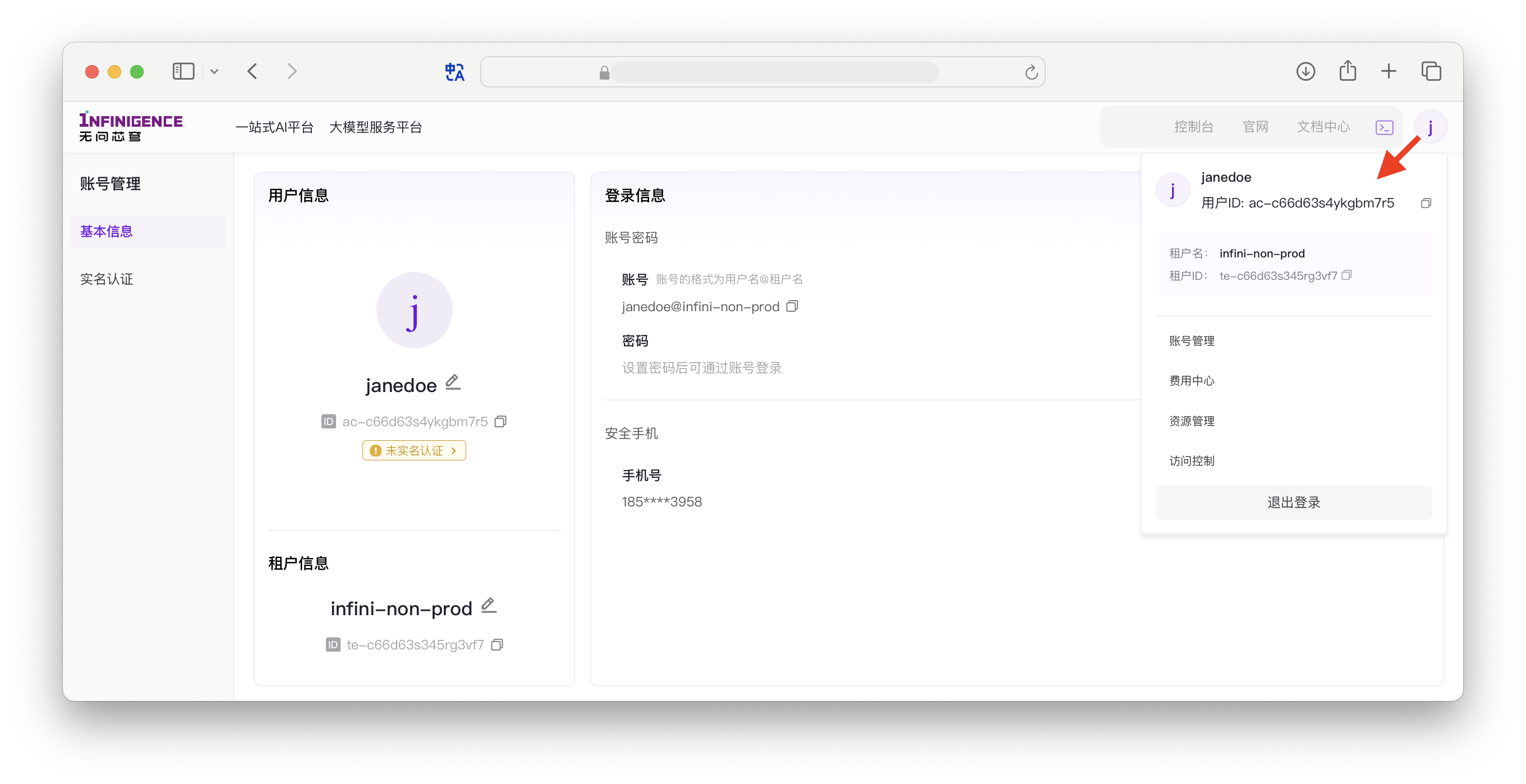
您可以通过智算云控制台查看当前账号的信息。如需排障,可能需要您提供租户 ID。
资源
无问芯穹 AIStudio 提供两类有额度限制的资源类型:- 计算资源
- 存储资源
下面分别对两类资源进行介绍,并介绍如何查看相应的资源配额。
算力资源
无问芯穹商务人员会提前与您联系,确定分配给您账号的算力资源。AIStudio 提供从入门级 GPU,到专业级高性能 GPU 算力的多种选项,包括:
- NVIDIA A100 40G 显存
- NVIDIA A100 80G 显存
- NVIDIA H100 80G 显存
- NVIDIA 入门级 GPU 24G 显存
运行容器时需要指定「负载规格」(CPU、GPU、内存)、选择「镜像」(可以理解为预装的操作系统和应用程序)、挂载「共享高性能存储」。
注意
- AIStudio 基于 K8S 和容器技术提供主要功能,仅提供池化的算力资源,而非裸机或虚拟机。
- 您只能按 AIStudio 预定义的负载规格使用算力,按 GPU 数量分为 1、2、4、8 卡。例如: 您的租户的算力资源为 NVIDIA A100 80G 显存 * 8,则表示该租户获得了使用 8 个 NVIDIA A100 的配额,可创建 8 个包含 1 个 GPU 的开发机。
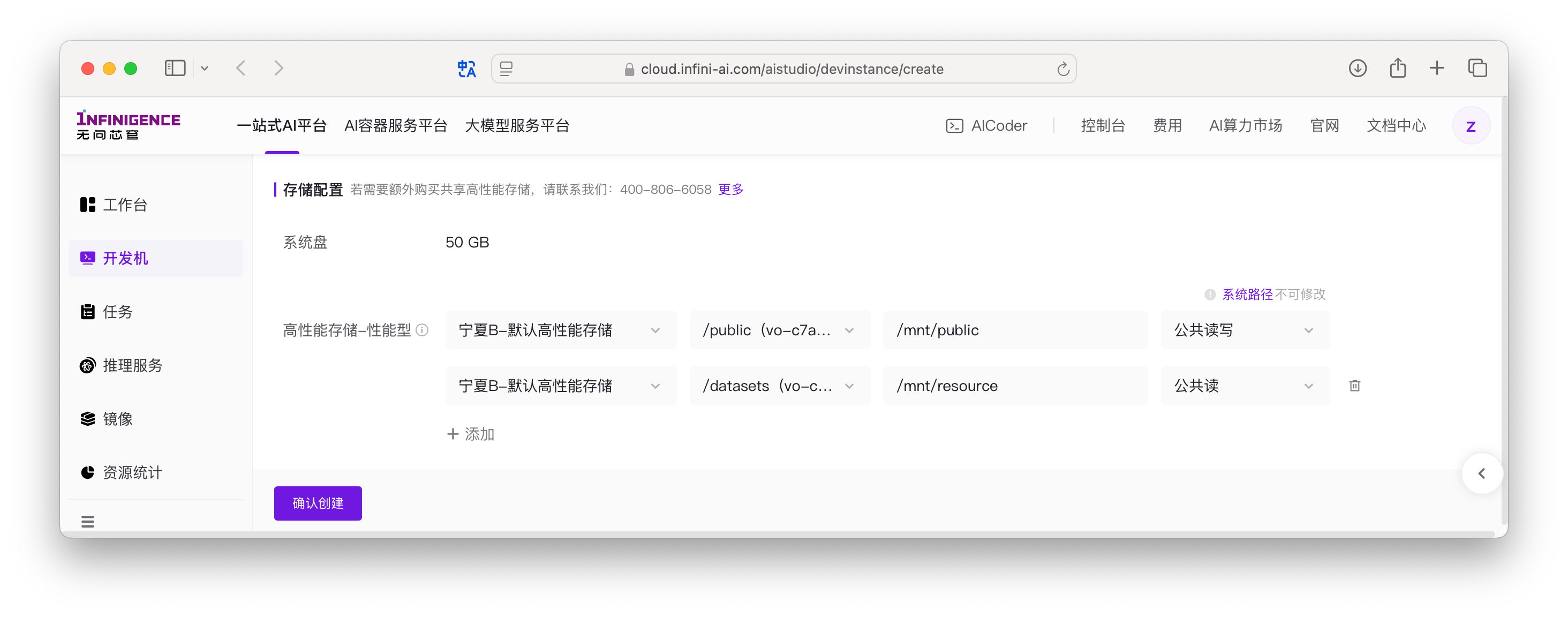
存储资源
AIStudio 提供共享高性能存储功能,性能可达每单位 30k IOPS,上限 1 亿文件(以 10TB 为单位)。采用多副本机制,确保数据安全可靠。
您无需手动管理共享高性能文件存储。在创建开发机、任务、推理服务时,平台会默认将存储以建议挂载点的方式挂载至算力容器内。
注意
智算云平台暂不提供可用存储资源的全局视图,您可以在容器内使用 df -h 查看存储配额。
了解 AIStudio
AIStudio 是无问芯穹推出的企业级机器学习开发平台,提供一站式开发、训练、推理服务,旨在为开发者提供出色的开发体验。
AIStudio 包含以下功能:
- 开发机:为开发者提供的在线编译、调试代码和模型开发的模块,可在开发机内部启动 Docker 容器。
- 任务:预置了 PyTorchDDP、MPI 多种分布式训练框架,用户无需关心底层机器调度和运维,上传代码和填写适量的参数即可快速发起分布式训练任务。
- 推理服务:可选择基于平台或自定义的推理服务镜像,配置合适的资源,将模型部署为推理服务。
- 镜像:平台预置了 CUDA、Pytorch、DeepSpeed、NGC、Ubuntu 等基础镜像,支持基于预置镜像、开发机、Dockerfile 构建自定义镜像。
动手体验开发机
开发机是您在智算云平台上的专属工作台。它基于容器技术,但提供了一个持久化的 Linux 环境,操作体验与您熟悉的基础设施(物理机或虚拟机)几乎一致。
在这里,您可以延续「先登录服务器,再手动输入命令」的经典开发模式:
- 持久化系统盘:即使关机或重启,您安装的软件、环境变量(如
~/.bashrc)和代码文件都会完整保留,就像使用一台长期运行的虚拟机。 - Root 权限:您拥有容器内的完整 Root 权限,可以使用
apt安装软件、配置git或管理用户环境。 - 高性能环境:预置了 NVIDIA 驱动、Python 等 AI 开发工具,直接调用数据中心级别的 GPU 算力。
创建您的工作台
点击下方链接,快速创建一个开发机。
在配置时,为了获得最佳的交互体验,建议关注以下设置:
- SSH 登录密码:建议启用,以便后续使用本地终端(Terminal)或 VS Code 远程连接。
- 镜像:选择您熟悉的操作系统环境(如 Ubuntu)。
- 存储:平台已默认配备了 100GiB 的持久化系统盘,您也可以根据需要挂载共享高性能存储。
连接与使用
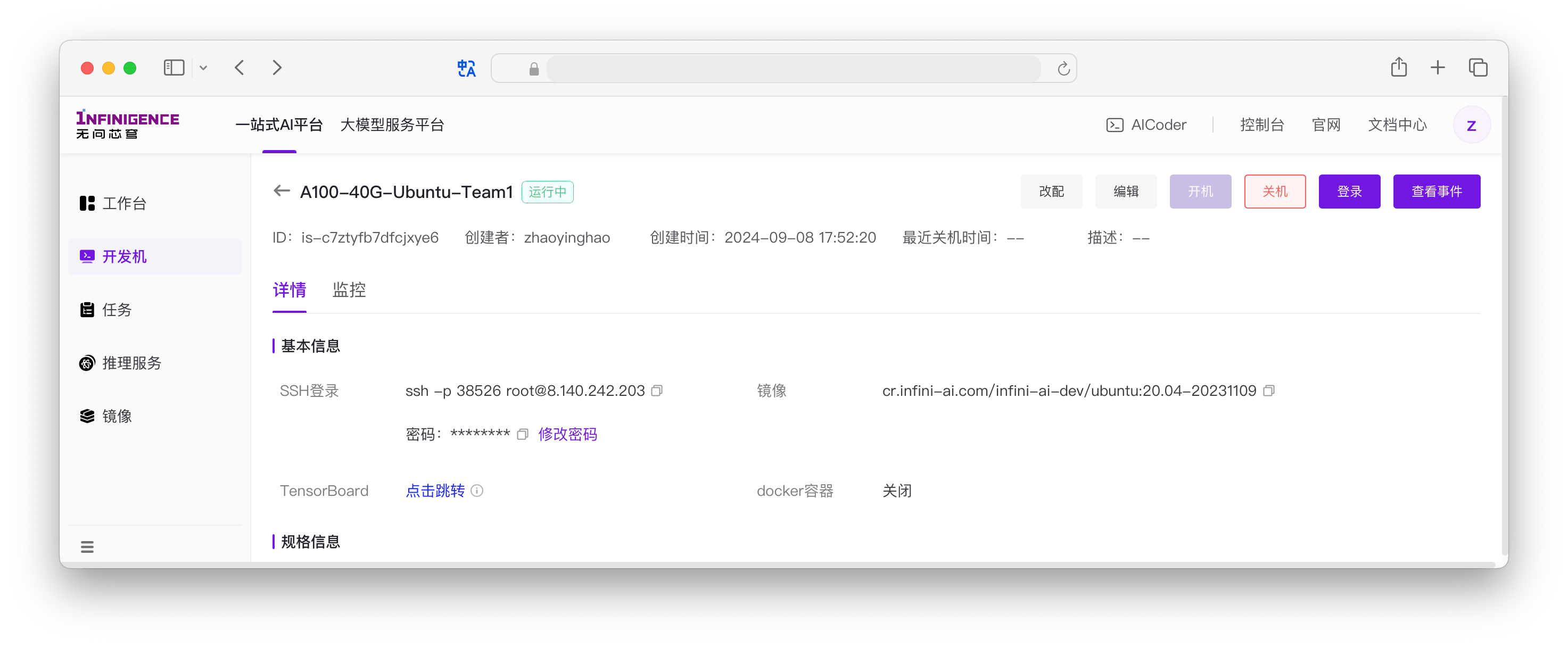
开发机启动后(状态为 运行中),您可以通过以下两种方式登录,开始您的开发工作。
Web Terminal:即开即用
无需安装任何客户端,直接在浏览器中打开类似 Shell 的界面。适合快速查看状态或执行简单命令。
在开发机列表中,点击右侧的 登录 按钮即可访问。
SSH 远程连接:生产力首选
通过 SSH,您可以将开发机无缝集成到您的本地开发流中。无论是使用 VS Code 的 Remote-SSH 插件,还是直接使用终端命令,体验都与连接一台远程物理机无异。
提示
开发机 vs 虚拟机:虽然操作体验高度一致,但开发机本质上是运行在 Kubernetes 上的容器。
- 轻量化:容器去除了 Systemd 等重型组件以提升启动速度。因此
systemctl命令不可用,建议直接运行程序或使用tmux管理后台会话。 - 资源隔离:能享受到容器化的灵活性(如一键更换镜像、环境重置),同时系统通过
MIZAR_CPUSET等机制确保您的 CPU/GPU 资源独占性。
开发机常见问题
如何传输数据?
如果需要传输本地数据到开发机的根目录下,可使用
scp或sftp命令。详见上传和下载文件到开发机。如果需要图形界面,可参考教程 如何使用 FileZilla 管理开发机内的文件。
如果读写开发机挂载的高性能文件存储(
/mnt/路径下的目录),且数据传输耗时较长,更推荐使用 AICoder 上传和下载文件。AICoder 为我们免费提供的小规格 CPU 实例资源,可用于完成数据准备等操作,避免占用 GPU 资源。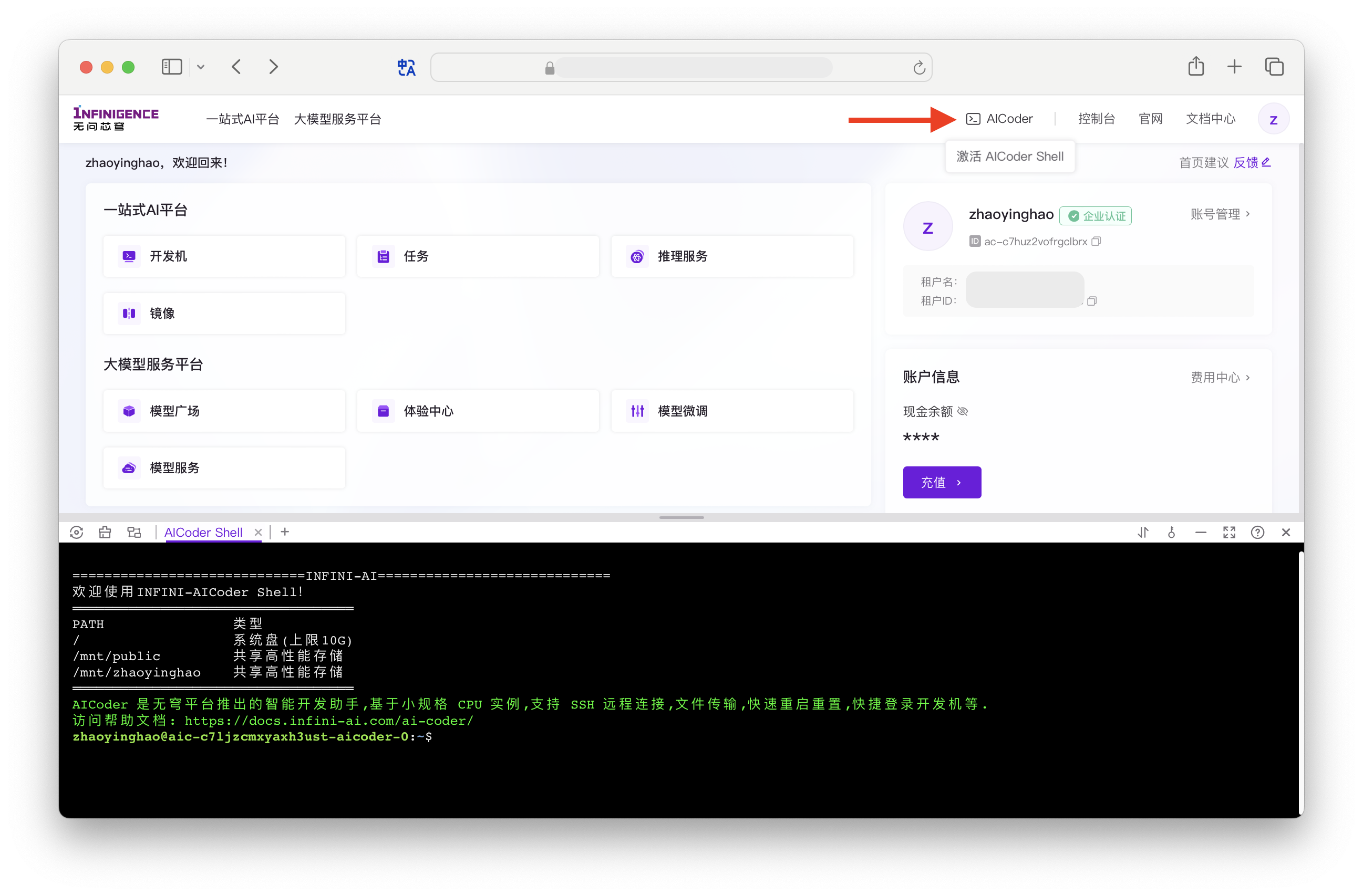
如何从公网访问开发机内的服务?
开发机内服务往往只监听了内网地址,无法直接从公网访问。如遇到演示、测试等临时性场景,可能需要从公网访问开发机内服务。我们可以利用 SSH 端口转发功能,将云服务器内网端口映射到本地电脑,从而实现访问。
详细操作步骤,可参考教程 如何从公网访问开发机内的服务。
可以使用哪些镜像?
点击下方链接,直接访问智算云控制台的镜像中心。平台预置了 CUDA、Pytorch、DeepSpeed、NGC、Ubuntu 等基础镜像,支持基于预置镜像、开发机、Dockerfile 构建自定义镜像。
如何使用 root 身份登录?
开发机默认登录用户为
root身份。警告
执行任何文件操作前,请核实当前用户身份,避免文件权限混乱。
从开发机到任务与推理服务:先理解启动命令
开发机的操作体验对齐了物理机/虚拟机,让您能轻松上手。但是,当您准备将模型从开发机迁移到「训练任务」或「推理服务」时,您需要适应一套完全不同的运行逻辑。
训练任务和推理服务的运行机制与开发机截然不同。许多在开发机(或物理机)上通过“SSH 登录后交互运行”验证通过的代码,直接复制到这两个模块中往往会运行失败。
如果不提前理解这种差异,您在填写「启动命令」时可能会感到困惑,或者遭遇“任务启动即退出”、“服务无法连接”等问题。为了帮助您顺利跨过这个门槛,请务必理解以下三个核心观念的转变:
从登录后操作转变为启动即运行
在物理机或虚拟机环境,常见的操作流程是:SSH 登录,进入目录,查看文件,然后手动输入命令运行。机器启动后,通常是一个安静等待指令的空环境。
在智算云平台上,推理服务和训练任务的容器是为单一任务而生的。您在表单中填写的「启动命令」,直接定义了容器的运行目标。如果没有一个持续运行的前台进程,容器启动后会立即认为任务完成并退出。
常见错误: 误以为容器启动后会等待登录,因此填写了非阻塞的短命令(例如 ls -l、echo "start" 或 nvidia-smi)。这导致容器执行完命令后立即销毁,无法登录。
建议策略: 如果您需要像虚拟机一样使用(先启动,再 SSH 登录操作),请在启动命令中填写 sleep infinity。这个命令会使容器保持“睡眠”运行状态,方便您 SSH 登录进去调试。
理解进程与容器的生命周期绑定
在物理机或虚拟机环境,脚本运行结束后,终端和 Shell 依然存在,您可以继续运行下一个命令。
在智算云平台上,容器的存活状态完全依赖于启动命令启动的进程。对于训练任务,命令结束(无论成功还是报错),容器就会销毁。对于推理服务,命令必须是一个阻塞式的长运行进程,否则服务会中断。
常见错误: 习惯性地使用了 nohup 或 & 后台运行代码。这导致前台进程立即退出,触发容器销毁机制,或者陷入反复重启。
建议策略: 始终确保启动命令是前台运行的阻塞式进程。对于推理服务,避免使用后台运行符 &。如果您需要顺序运行多个命令(例如安装依赖后启动训练),请使用 && 连接它们,例如:pip install -r requirements.txt && python train.py。
理解本地路径与挂载映射的区别
在物理机或虚拟机环境,代码位置通常是固定且在文件系统中可以直接看到的(例如 /home/user/project)。
在智算云平台上,代码存在于存储系统中,只有在容器启动的那一刻,才会根据表单配置挂载到指定的容器路径。您需要根据表单配置(容器内访问路径)判断代码在容器内的实际位置,确认在运行脚本前是否需要先切换目录。
常见错误: 直接使用本地开发时的相对路径,或将数据写入非挂载目录(例如代码依赖 ./data 等相对路径,却未在启动命令中先 cd 切换到挂载目录;或者将模型保存到了 /root 等临时路径)。这导致找不到挂载的数据,或数据在容器销毁后丢失。
建议策略: 填写启动命令前,仔细检查“存储挂载”设置,确认您的代码和数据被挂载到了哪个容器内路径。在启动命令中显式地切换工作目录,例如 cd /mnt/my-code,并确保将输出结果写入挂载的持久化存储路径中。
动手体验推理服务
一站式 AI 平台(AIStudio)的推理服务专为生产环境设计。相比于在开发机中手动运行 API Server,使用推理服务模块部署模型具有显著的企业级优势:
- 开箱即用高可用:内置负载均衡器,自动分发流量,单点故障不影响整体服务。
- 极致弹性:支持自动扩缩容,根据 QPS 或 GPU 利用率毫秒级调整实例数量,从容应对流量波峰波谷。
- 大模型友好:原生支持 vLLM/SGLang 等高性能框架及多机多卡分布式推理,无需复杂的集群网络配置。
推理服务:核心运行机制
推理服务旨在提供 7x24 小时 的稳定在线服务,其运行逻辑围绕“高可用”构建:
- 进程即生命:启动命令必须是阻塞式的前台进程。一旦命令执行结束(或被放入后台),容器就会被平台判定为异常并自动重启。请勿使用
nohup或&。 - 优雅停机:在自动扩缩容过程中,频繁的实例销毁是常态。您的服务需要正确响应
SIGTERM信号,处理完当前正在推理的请求后再退出,确保业务零中断(Zero Downtime)。 - 无状态设计:任何持久化数据都不应写入容器系统盘(重启即丢失)。模型文件应读取自共享存储,业务日志应推送到标准输出或外部日志服务。
提示
如何编写既能前台运行又能优雅退出的启动脚本?请参考最佳实践:优化推理服务启动命令。
极速体验与标准流程
为了帮助您快速上手,我们提供了两种体验方式:
- 极速体验(推荐):直接参考 极速部署教程。该教程无需手动准备模型,通过脚本自动下载,5 分钟即可拉起服务。
- 标准流程:按照下文的步骤,体验“下载模型 -> 部署服务 -> 验证服务”的完整生产闭环。有助于建立正确的使用思维。
下载模型文件
在生产部署中,我们通常需要先将模型文件存储在持久化的共享高性能存储中。
为方便体验,您可以使用 AICoder 提前下载开源模型:
git lfs install
mkdir -p /mnt/pubic/models/
git clone https://www.modelscope.cn/qwen/Qwen2-7B-Instruct.git /mnt/pubic/models/Qwen2-7B-Instruct/创建推理服务
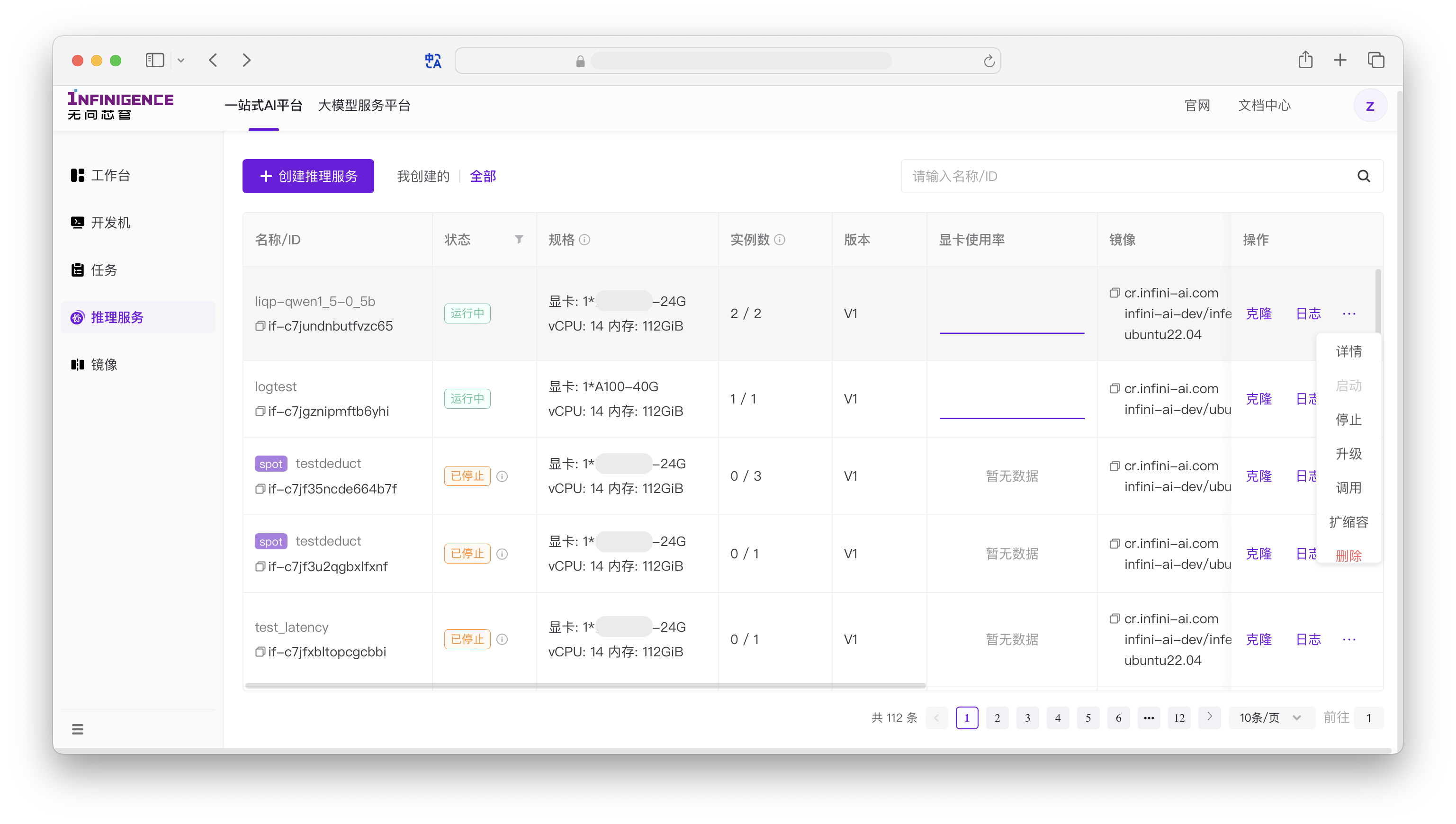
访问智算云控制台的推理服务页面,可创建推理服务。
详细操作可参考教程 推理服务标准部署流程。
针对主流推理框架,也可参考以下指南:
注意
如果您选择了手动下载模型(标准流程),在配置启动命令时,请确保加载的模型路径指向 /mnt/pubic/models/Qwen2-7B-Instruct/。
测试推理服务
在推理服务部署完成后,可直接进入详情页,获取推理服务的内网 IP 地址。
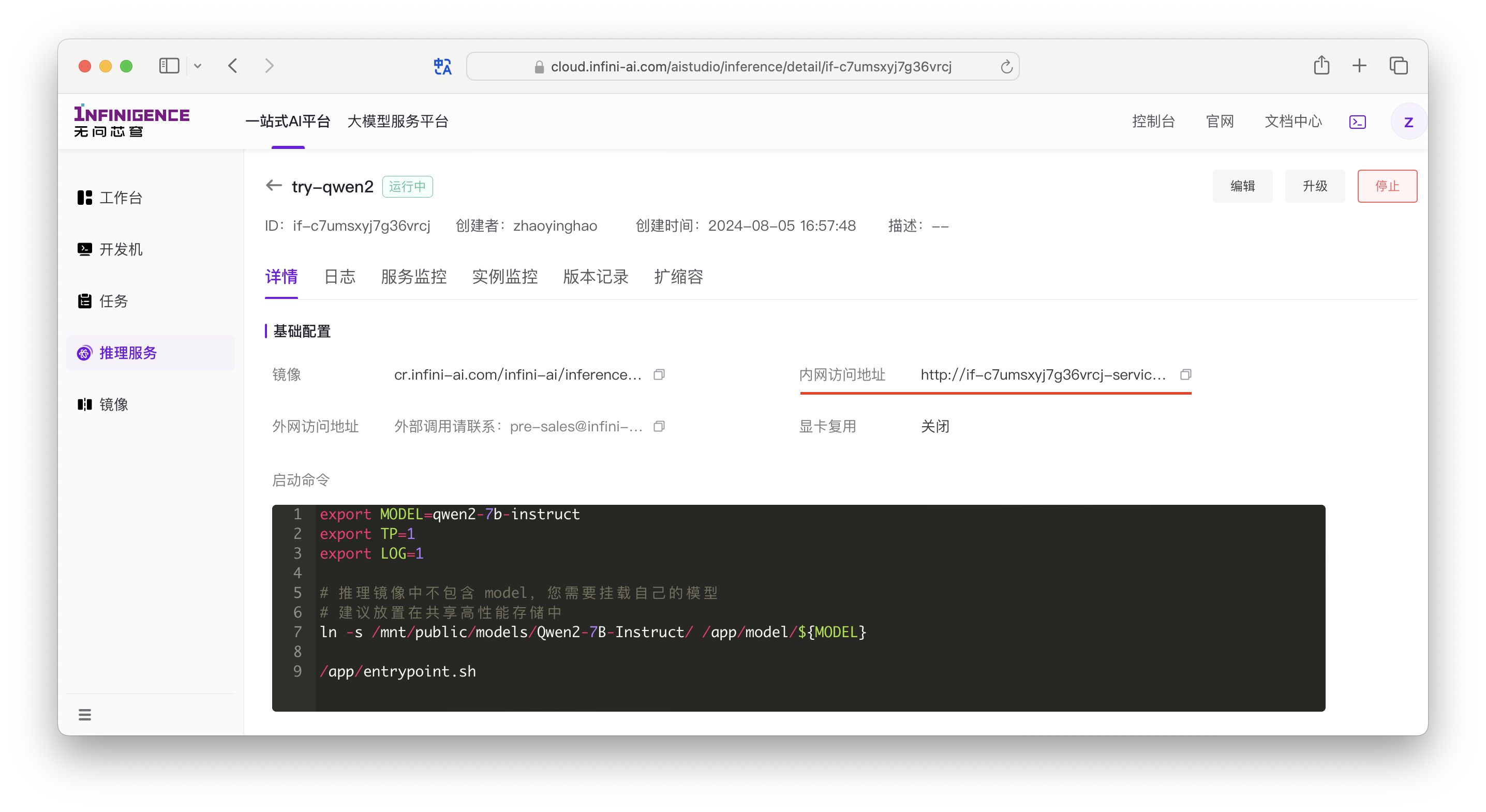
如上图,推理服务的内网服务地址为: http://if-c7umsxyj7g36vrcj-service:80
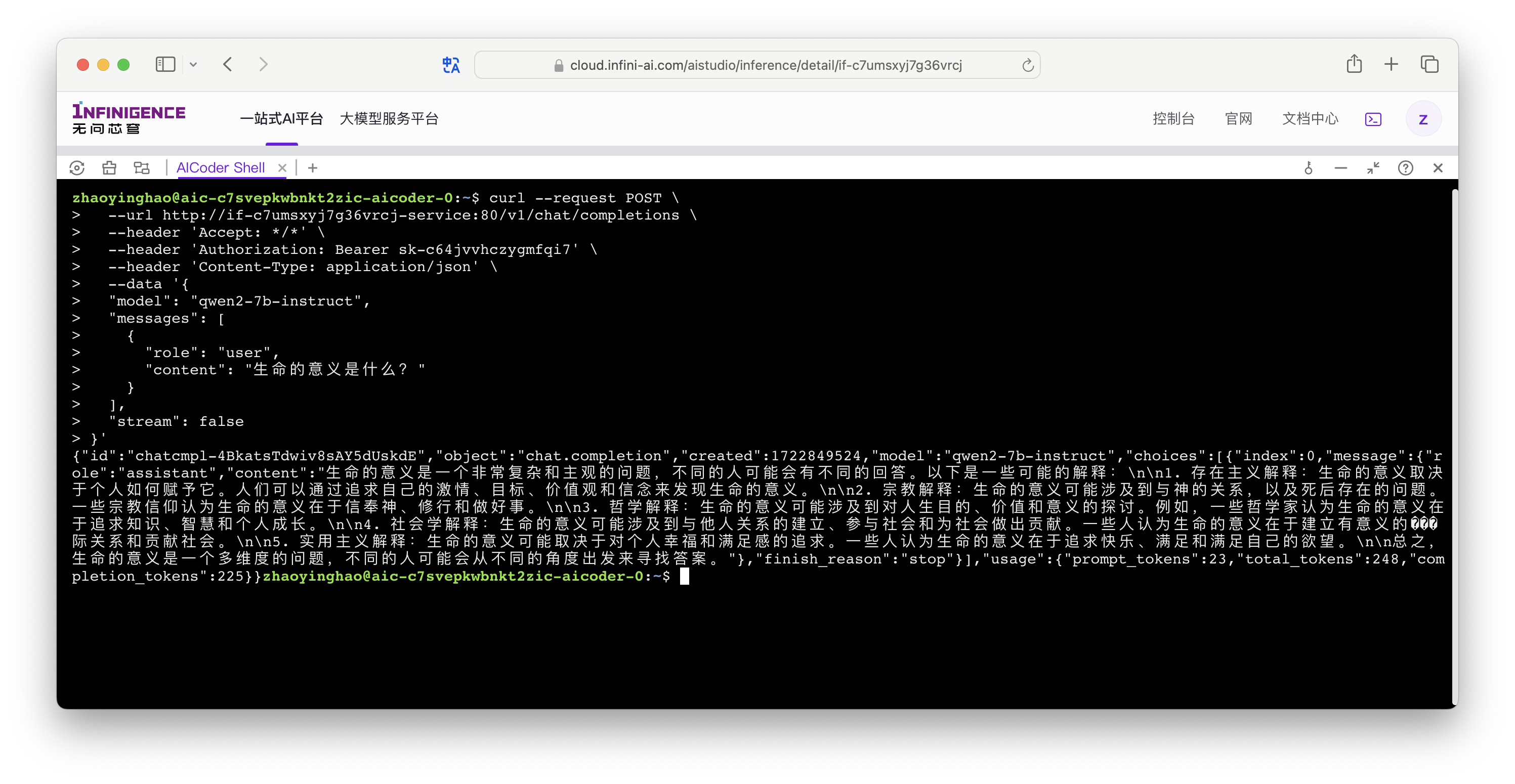
点击智算云平台右上角,打开 AICoder Shell,向该服务的 API 端点 /v1/chat/completions 发送测试请求:
体验训练任务功能
一站式 AI 平台(AIStudio)的训练任务功能可支持单机训练任务和多机多卡的分布式训练任务。
注意
如果仅有单机多卡的训练需求,仅使用一站式 AI 平台(AIStudio)的开发机也可满足需求。
训练任务:核心运行机制
与开发机不同,训练任务是一次性的。任务启动后,您无法像登录开发机一样实时干预,因此“可观测性”和“结果反馈”至关重要:
- 容器即生即灭:任务命令执行结束(无论成功失败),容器立即销毁。不要将数据保存在容器系统盘中,务必写入挂载的共享存储。
- 退出码决定状态:平台仅依据启动命令的退出码判断任务状态(
0为成功,非0为失败)。脚本中请勿屏蔽错误(例如避免使用command || true),否则失败的任务也会被标记为“成功”。 - 日志即视窗:容器的标准输出(stdout/stderr)会被平台自动采集展示。请直接将日志打印到屏幕,而不是仅写入容器内的不可见文件。
提示
遇到“任务秒退”或“显示成功但无产出”等疑难杂症?请查阅 训练任务启动命令指南 了解如何正确处理退出码与保留现场排障。
单机训练任务
我们提供了详细的实践教程,手把手教您如何在智算云平台上快速实现 Hugging Face 技术主管 Philipp Schmid 的 FSDP / LoRA / Q-Lora 微调教程。
使用 PyTorch FSDP 实现 Lora 及 Q-Lora 微调 Llama 3 70B 模型
阅读该教程后,您将基本了解无问芯穹智算云平台任务功能的基本操作:
- 如何构建训练任务使用的自定义镜像
- 如何通过 AICoder 下载和准备数据
- 如何在任务界面上提交训练任务
- 如何在任务界面上查看训练过程数据
分布式训练任务
在支持多机多卡分布式任务时,AIStudio 的任务功能具有以下优势:
- 预置了对 Pytorch DDP 和 MPI 的支持。
- 提供 IB 或 RoCE 训练网(详询商务)。
- 无需手动配置分布式环境,平台自动感知当前资源与环境,进行最优配置。
- 提供了简单、易用的自动容错的能力,保障训练任务长期稳定运行。
针对主流分布式框架,我们提供了详细的配置指南:
如果需要创建多机多卡的分布式训练任务,可参考官方文档:发起任务。
后续步骤
恭喜您,成功体验了智算云平台 AIStudio 开发机、任务和推理服务功能。
接下来,您可以继续阅读以下文档,了解无问芯穹 AIStudio 的更多功能特性。