

快速创建训练任务
如果您首次使用 AIStudio 任务功能,本文将帮助您快速上手,在平台上完成「训练任务」提交的关键流程。
完成本指南后,您将能够:
本文以创建「训练任务」类型的任务为例。该类型使用租户的包年包月计算资源,不支持按卡时计费。
「训练服务」类型的任务支持按量付费,如需了解详情,请移步以下文档:
前提条件
在使用「包年包月资源」创建「训练任务」类型的任务之前,请确认您所属租户已购买该类型算力资源。
包年包月算力资源
包年包月算力资源是指租户按固定周期(包年/包月)购买算力资源配额的独占使用权,提供多种 GPU 数量、型号配置。您可以前往算力市场浏览可选配置,支持自助下单(也可以联系商务下单)。
租户新购的包年包月算力资源自动进入默认包年包月资源池。您可以前往资源池页面查看。
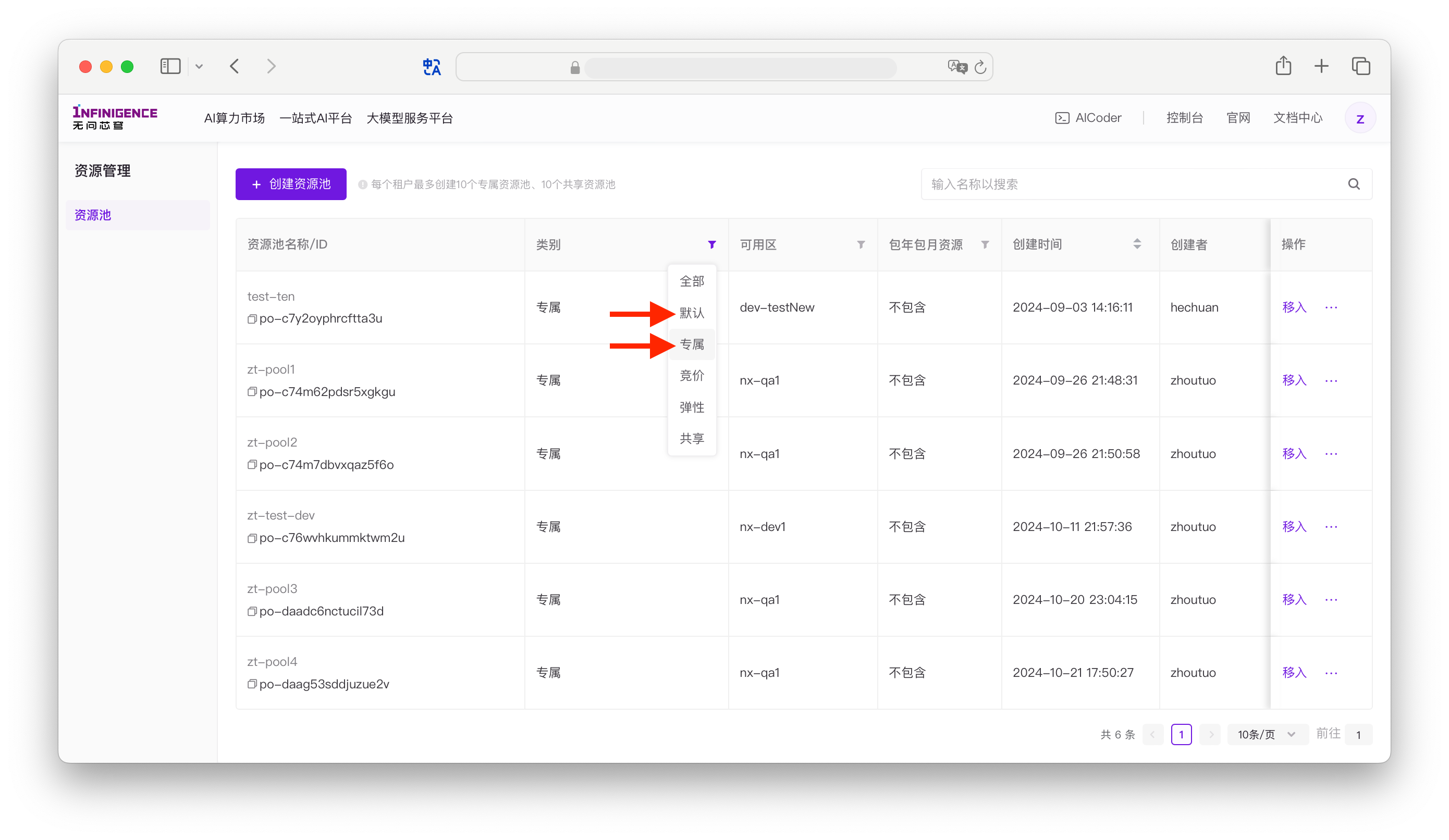
提示
- 租户购买的包年包月算力资源一般属于默认类别。租户可从默认资源池移出资源,加入租户自建的专属资源池,因此专属类别的资源池也会存放包年包月资源。
- AIStudio 基于 K8S 和容器技术提供主要功能,仅提供池化的算力资源,而非裸机或虚拟机。
存储资源
AIStudio 任务可使用以下类型存储资源。
- 系统盘:免费提供 50 GiB 系统盘(挂载在
/下),任务中的所有 Worker 系统盘存储空间均为 50 GiB。系统盘不持久化,任务结束后数据将丢失。 - 共享高性能存储:租户可额外购买共享高性能存储卷,在创建任务时挂载至各 Worker。存储卷在多个 Worker 间共享,支持多点读写,数据持久化保存,不受任务或实例释放的影响。
提示
- 对于单机或多节点训练任务,必须将训练结果(模型权重、Checkpoint、日志等)保存到挂载的共享高性能存储卷中。系统盘中的数据在任务结束后无法找回。
- 支持线上自助购买「广东B」可用区的共享高性能存储。详见管理共享高性能存储。其他可用区共享高性能存储暂不支持线上购买,如需购买,请联系商务。
RDMA 网络
分布式训练任务通常需要高性能的 GPU 间通信。AIStudio 平台支持 InfiniBand (IB) 和 RoCE 两种 RDMA 网络类型(算力规格的训练网配置字段),平台会自动感知当前资源与环境并进行最优配置。
重要
RDMA 使用限制:创建训练任务时,仅当所有 Worker GPU 数量为 8 卡时方可使用 RDMA 配置。存在任意 Worker GPU 数量小于 8 卡时,禁止使用 RDMA。
RDMA 多节点训练:对于大规模分布式训练,RDMA 是保障节点间高效通信的关键。我们建议仅在完整 8 卡节点上使用 RDMA 进行多节点训练。
RDMA 检测与容错:如果您启用了任务的「容错」功能,平台会在任务启动时自动执行 RDMA 检测。请关注容错日志中的 RDMA 检测输出,及时发现潜在问题。
自定义镜像用户注意:如果您使用自定义镜像,且「容错日志」中 RDMA 检测结果显示异常,请确保镜像已安装 RDMA 依赖。详见 RDMA 网络配置 - 自定义镜像的 RDMA 依赖。如果您使用平台预置镜像和 8 卡规格,通常无需手动配置 RDMA,平台会自动处理。
如需了解 RDMA 网络的详细配置(包括查询训练网类型、自定义镜像依赖、NCCL 环境变量等),请参阅 RDMA 网络配置。
准备训练代码与数据
假设您已经在本地或 AIStudio 开发机中完成代码开发,需要将代码、数据迁移到 AIStudio 任务功能。
为确保分布式训练的稳定与高效,我们建议:
- 预先获取数据集:将代码、数据集下载到共享高性能存储,挂载到任务中,并在训练前或训练中拉取,避免网络延迟或失败的影响。您可以使用 AICoder 或开发机下载模型、数据集,或从本地传输数据。
- 使用屏障(barrier)同步数据加载状态:在分布式训练框架(如 MPI 或 PyTorch Distributed)中,可以使用 barrier 机制来同步各个节点,确保所有节点的数据准备就绪后才开始训练。
以下是一个简单的 PyTorch 示例代码:
import torch.distributed as dist
# 假设 fetch_dataset 函数用于下载或加载数据集
def fetch_dataset(data_path):
# 实现数据集的下载或加载
pass
# 假设 start_training 函数用于启动训练
def start_training():
# 实现训练逻辑
pass
# 在训练脚本中
if __name__ == "__main__":
# 初始化分布式环境
dist.init_process_group(backend='nccl')
# 获取数据集
fetch_dataset(args.data_path)
# 使用屏障同步所有进程,确保所有节点都已完成数据获取
dist.barrier()
# 开始训练
start_training()在上述代码中,dist.barrier() 确保所有分布式节点在数据获取完成后同步,只有当所有节点都到达此屏障时,训练才会开始。这可以有效防止因部分节点数据未就绪而导致的训练失败或性能问题。类似地,在 MPI 中,您可以使用 MPI.COMM_WORLD.Barrier() 来实现相同的同步效果。
注意
如有非常耗时的操作,强烈建议不要跟训练任务一起进行。建议先使用开发机或 AICoder 预先拉取代码、数据到共享高性能存储。
准备训练环境
AIStudio 任务的镜像有以下来源:
- 平台预置镜像:平台预置了 NGC / PyTorch 等主流镜像。
- 外部(或本地的)镜像:当用户本地或其它外部镜像仓库中有正在使用的镜像,可以参考迁移外部镜像到镜像仓库。详见迁移外部镜像至租户镜像仓库
- 构建镜像:平台镜像中心支持按需构建自定义镜像,支持在现有镜像上安装依赖项、Dockerfile 和保存开发机环境为新的镜像三种构建方式,详见构建自定义镜像。
创建训练任务
在智算云平台任务列表页面点击 创建任务,进入创建任务界面,可创建单机或分布式任务。
请根据页面提示,完成下方所有步骤中的配置。
Step 0 选择任务类型
在任务页面,可创建以下类型的任务:
- 训练任务:使用租户自购的包年包月资源池中 GPU 资源,支持单机和分布式训练。本文以创建「训练任务」为例。
- 数据处理任务:使用租户自购的包年包月资源池中空闲的 CPU 资源,并且优先保障与 GPU 相关任务不受影响。
除以上类型外,平台另提供「训练服务」。该类型任务使用由平台提供的闲置 GPU 资源,采用后付费方式(需预存余额),每个任务按预估时长独立定价,独立结算。该类型任务仅在闲置资源可用时自动运行,且可能会被因资源抢占被中断。关于如何创建「训练服务」类型的任务,请移步以下文档:
Step 1 选择算力资源与规格
首先,在「规格信息」区域选择合适的 GPU 算力资源。
资源池:资源类型为包年包月资源时,平台会列出租户下的所有资源池,在资源池下拉列表中可直接查看池中空闲卡数。
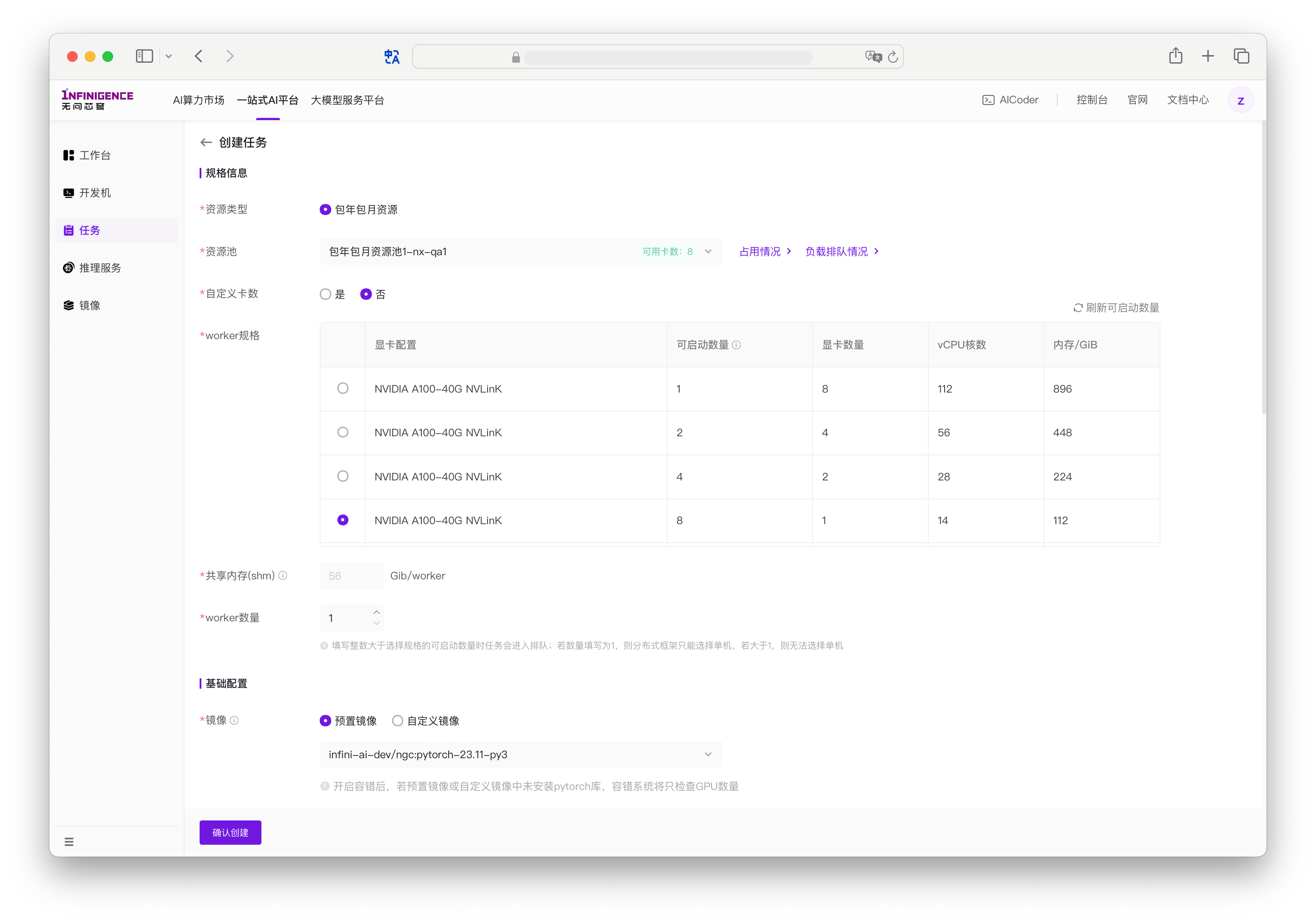
点击占用情况和负载排队情况可查看当前资源占用明细,并提前判断是否可启动多卡实例。
注意
什么是占用情况和负载排队情况?
在 AI/ML 工作负载中,GPU 资源的分配通常具有特定的需求。例如:某些工作负载要求在一组节点上运行,每节点必须提供 8 个空闲 GPU,而非在多个节点上分散的 GPU 资源。智算云平台的占用情况视图提供资源池各个节点 GPU 占用的实时视图,而工作负载优先级调度功能支持允许查看当前工作负载排队等待资源的情况,超级管理员通过拖拽高优先级负载至优先调度队列,可确保关键任务优先获得 GPU 资源。详见查看资源使用与排队情况。
自定义卡数:是否使用自定义卡数模式。自定义卡数模式下,可自行填写总 GPU 数量。
否(默认):任务中所有 Worker 需要采用统一算力配置。如果您的代码要求所有 Worker GPU 数量相等,建议选择「否」。
注意
默认情况下,所有 Worker 必须使用相同的预定义算力规格(1、2、4 或 8 卡)。非自定义卡数模式下,只能按 AIStudio 预定义的规格使用算力,且每个 Worker 的规格必须相同。
是:如果可允许 Worker 之间存在卡数差异(需修改训练代码),可选择「是」。填写数量时,如果自定义卡数 > 8,则创建多个完整 8 卡 Worker 和一个非 8 卡 Worker。如果为自定义卡数小于 8 卡,则创建单个 Worker。详见自定义卡数模式。
Worker 规格:选择单个 Worker 的算力配置。
在默认情况下(非自定义卡数模式),只能按 AIStudio 预定义 1、2、4、8 卡四种「算力规格」使用算力,且每个 Worker 的规格必须相同。「可启动数量」指此规格当前能够启动的最大 Worker 数量。例如,
NVIDIA A100-80G NVLinK8 卡规格的可启动数量为 0,表示当前已无法提供挂载 8 卡 A100-80G 的 Worker。在自定义卡数模型下,选择当前使用的 GPU 规格。「可启动数量」指自定义卡数模式下能够启动的最大显卡数量。
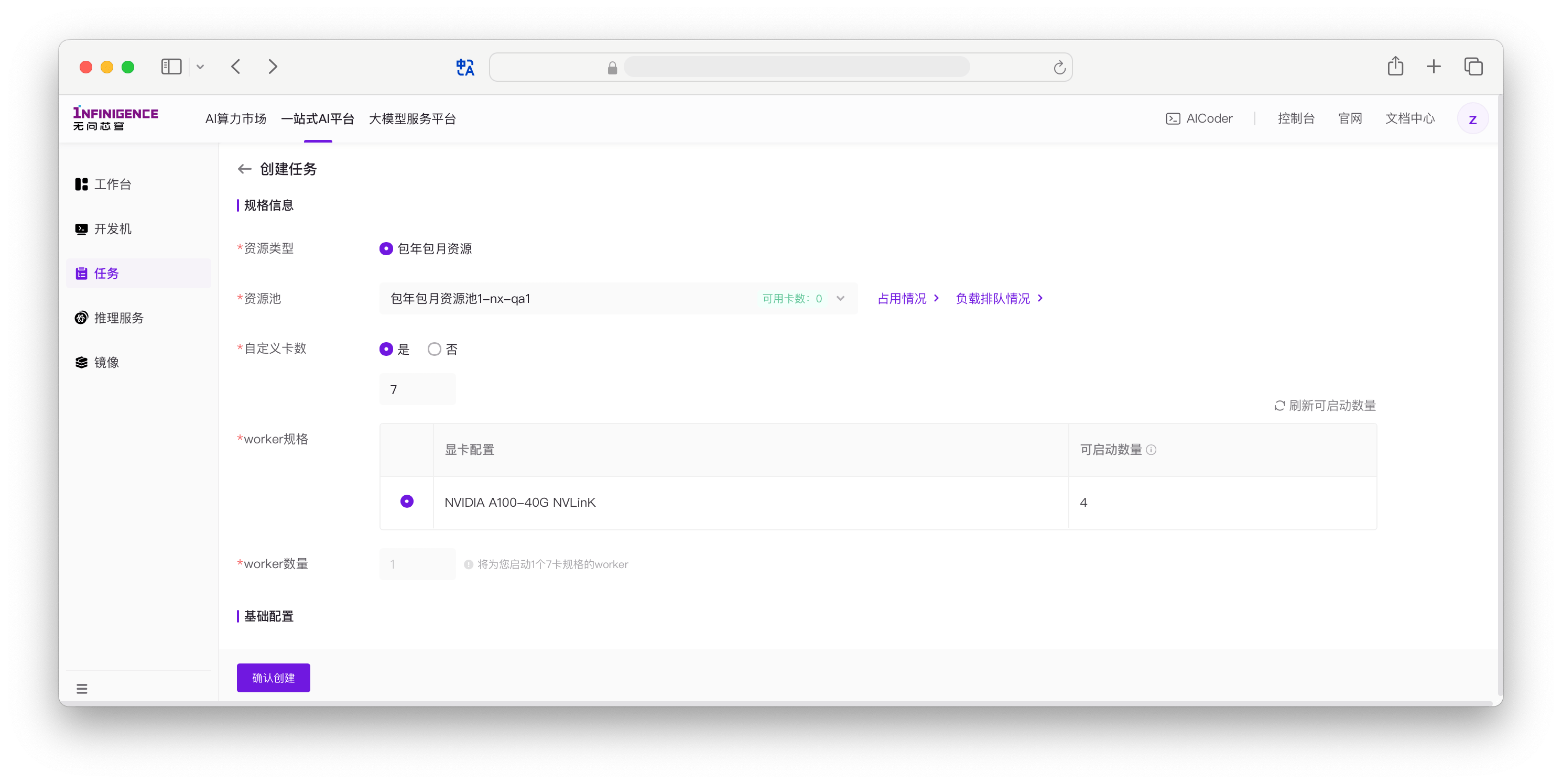
注意
单个 GPU 规格的 可启动数量 可能小于该规格全部剩余卡数。可启动数量的计算方式为:剩余完整 8 卡节点的卡数 + 剩余非 8 卡节点中的最大空闲卡数。
共享内存:任务 Worker 的
/dev/shm分区大小。当前为固定值,每个 Worker 的共享内存为「Worker 规格」内存的一半。自定义卡数模式下不展示该字段。Worker 数量:任务中的 Worker 数量。
- 在默认情况下(非自定义卡数模式),可自行填写 Worker 数量。可根据 Worker 规格表中的可启动数量填写合适的数字。如果 Worker 数量大于可启动数量,则任务创建后将进入排队状态。
- 在自定义卡数模型下,选择当前使用的 GPU 规格。每个 GPU 规格展示「可启动数量」指自定义卡数模式下能够启动的最大显卡数量。
RDMA 配置: 如果所选规格的「训练网配置」为 RoCE 或 IB 且 GPU 数量为 8 卡,可看到该附加配置项。RDMA 配置在规格为 8 卡时自动开启,GPU 数量小于 8 卡时无法开启 RDMA。详见 RDMA 网络配置。
警告
- 前提条件:所选「算力规格」必须硬件支持 RDMA(训练网配置为 RoCE 或 IB)。
- 开关状态:如果「RDMA 配置」开关被关闭,则不会启用 RDMA 通信。
- 规格限制:GPU 数量小于 8 卡时禁止使用 RDMA 配置。
Step 2 配置训练任务
接下来,配置训练任务的其他参数。

镜像:在 Worker 中执行训练代码的环境,镜像中包含 OS 和预装软件。可在预置镜像、自定义镜像中筛选。详见镜像中心。
分布式框架:选择训练代码中使用的分布式框架。平台会为特定分布式训练任务注入环境变量。
单机:如无分布式训练需求,可选择单机。
Pytorch-DDP:以 torchrun 方式运行(详见 发起 Pytorch DDP 训练任务)。平台会自动给每个 Worker 添加如下环境变量:
MASTER_ADDR={worker-0的podname}:DDP 分布式通信的 master IP 地址或者 master 的名称,由系统负责解析。对应 torchrun 的--master_addr。MASTER_PORT=29500:在 master addr上开启的端口号,默认设置为 29500。对应 torchrun 的--master_port。WORLD_SIZE={Pod数量}:启动的 Pod 数量,也就是任务的节点数量(与 pytorch-operator 保持一致,方便从 kubeflow 迁移过来的用户。对应 torchrun 的--nnodes。RANK={Pod ID}:RANK 表示每个 Pod 的 ID,从 0 开始编号,到 n-1。对应 torchrun 的--node_rank。
MPI:以 MPI+hostfile 的形式启动任务,平台会自动分配必要的环境变量,并且已配置了 SSH 免密,保障 launcher 可以下发任务到 Worker 上:
OMPI_MCA_orte_default_hostfile=/etc/mpi/hostfile:OpenMPI 的默认 hostfile 路径,用 openmpi 启动任务时无需再指定 hostfileMPICH_HOSTFILE=/etc/mpi/hostfile: MPICH 的默认 hostfile 路径,用 MPICH 启动任务时无需再指定 hostfile
Ray:以最小的配置成本启动一个完全托管的 Ray 集群,并在 GPU 加速的容器环境中运行分布式任务。平台会自动完成 Ray Head 节点的初始化、Worker 节点的调度、资源挂载、以及 Dashboard 的访问配置,使您无需再手动执行 ray start、管理节点地址或维护物理集群的网络环境。详见发起 Ray 分布式训练。
任务可视化: 如果启用 TensorBoard 可视化,表示允许平台读取您的任务输出 TensorBoard 日志。启用后,请在网页上提供训练代码中写入日志的路径。在任务运行过程中,AIStudio 可从该路径下读取 TensorBoard 日志并进行可视化展示。详见 启用任务功能内置的 TensorBoard 服务。
注意
- 启用任务可视化要求您的 Python 训练脚本中集成 Tensorboard,使用 SummaryWriter 记录日志。
- 日志路径可引用页面上定义的环境变量(引用示例:
/path/to/logs/${VAR_DIR}/),可用于避免任务多次执行、任务克隆、代码复用等场景下的日志路径重复与冲突问题。 - 建议将日志写入共享高性能存储,否则任务停止后将丢失日志。
- 任务运行期间可修改日志存储路径,平台会重启 TensorBoard 服务以读取新路径。
容错:平台提供模块化容错能力,包括环境检测、自动重启和 Hang 检测三个可独立配置的子功能,帮助保护训练作业免受硬件故障和异常情况的影响。各子功能可根据需要灵活组合使用。详见配置训练任务的容错功能。
- 环境检测:在关键时刻自动检查硬件和软件环境健康状况(GPU、RDMA、存储等),支持任务运行前、任务失败、任务 Hang 三个检测时机。
- 自动重启:任务失败或挂起时自动重启,可配置最大重启次数(1-10 次)和触发条件。
- Hang 检测:监控任务进度识别挂起状态,为其他功能提供"任务 Hang"触发条件。
提示
- 使用容错功能需确保训练脚本支持检查点恢复。平台可自动重启任务,但无法恢复内存中的训练状态。
- 自动重启默认最多重启 1 次,可配置为 1-10 次。超过最大重启次数后,任务将失败并结束。
- 开启环境检测的"任务运行前"检测时机,可在任务启动时及早发现硬件问题,但会增加 2-4 分钟启动时间。
进程栈采集:在任务 Hang 时自动采集进程栈数据,或在任务运行中手动触发采集,为分布式训练调试提供详细的执行状态信息。此功能需先开启 Hang 检测才能使用自动采集。详见使用进程栈采集功能。
注意
- 进程栈采集数据保留 30 天,包含报告(Markdown 表格形式的整任务函数调用统计)、进程栈(原始栈跟踪)和 NCCL 状态三类信息。
- 进程栈除 Python 调用外,在支持的情况下还可包含 C++ 动态库等原生代码相关帧。对任务性能影响通常很小,仅在 Hang 检测触发或手动采集时执行。
训练变慢检测:默认开启。开启后,可自动分析训练日志,发现训练变慢后在容错日志中输出告警。仅支持 Megatron-LM 和 LLaMA-Factory 框架变慢检测,若其他框架当前则不会进行检测。详见训练变慢检测。
启动命令: 可填写任务的环境变量及入口命令等,建议将训练过程封装在 bash 脚本中。参考:
环境变量: 平台支持在任务外部管理环境变量。以
API_KEY=123;API_HOST=127.0.0.1;VAR_DIR=exp_run_01格式输入多个环境变量后,平台自动解析出相应 Key 和 Value。在任务运行时,环境变量将自动输入至 Pod 中。您可以将环境变量设置为仅创建人可见,适用于存储 API 密钥、访问令牌等敏感信息。启用后:
- 创建人:可在任务详情页和改配时查看变量值
- 其他用户(包括租户超级管理员):无法在网页端查看变量值
- 一键重跑:有权限重跑的用户可直接复用原始环境变量,无需重新输入
- 改配重跑:非创建人必须重新设置「仅创建人可见」变量的值
注意
- 任务的网页端环境变量功能仅为方便用户从网页管理环境变量,无法覆盖任务启动命令和任务代码内设置的环境变量。
- 环境变量覆盖关系: 训练代码 > 任务启动命令 > 任务外部的环境变量。
- 登录任务 Worker 时的环境与任务代码执行环境不一致。如果在任务代码中设置了环境变量,无法在登录 Worker 时获取到该环境变量。可在任务 Worker 日志中打印环境变量。
- 作为最佳实践,请避免在网页、启动命令、训练代码等多处设置环境变量,避免环境变量混乱。
提示
特殊预留环境变量
AIStudio 平台支持通过
ATLAS_BOOTCHECK_ITEMS环境变量自定义启动检测项,以优化任务启动时间。您可以在「环境变量」字段中配置需要执行的检测项(如ATLAS_BOOTCHECK_ITEMS=gpu,allreduce,rdma),从最快的 5-10 秒到完整检测的 2-4 分钟不等。详细配置方法和各检测项说明请参考 训练容错 - 自定义启动检测项。
Step 3 配置存储
系统盘: 指任务 Worker 的
/目录的存储大小,固定 50GiB。公共数据:若所选算力规格位于支持的可用区(如广东B、宁夏B、北京D),可勾选「挂载公共数据」。勾选后,容器内
/infini-data/路径下将以只读方式挂载常用的开源模型和数据集。高性能存储: 挂载租户的共享高性能存储卷。如果任务需要访问共享高性能存储,必须在创建任务时创建挂载点。详见共享高性能存储。
- 文件系统名称:选择租户在当前可用区的文件系统(租户在一个可用区一般仅一个文件系统)。
- 存储卷:选择需要挂载的共享存储卷。
- 挂载路径:指定该存储卷在实例内部的挂载路径。
共享高性能存储配置项如下(表中为配置示例):
文件系统名称 存储卷名称与 ID 挂载点(容器内访问路径) 挂载权限 广东B-默认高性能存储 /public (vo-c7kcjqv2tjs5llry)/mnt/public公共读写 例如,在 AICoder 中将
/public (vo-c7kcjqv2tjs5llry)存储卷挂载为容器内/mnt/public目录,并在其中写入了训练代码、模型、数据集。在创建任务时,如需任务的 Worker 访问该数据,应同样挂载该存储卷(如代码要求路径一致,在任务中的挂载路径应同样指定为/mnt/public)。
Step 4 填写基本信息
- 名称:1~64 个字符,支持中英文数字以及- _,允许重复,名称不唯一。
- 描述: 添加描述或者备注,长度 1~400 个字符,可留空。
- 标签:可新建和绑定自定义标签。资源标签是一组键值对(Key-Value)。您可以通过标签从不同维度对一站式 AI 平台内的资源进行分类与聚合管理,用于按标签筛选等场景。详见标签管理。
完成表单配置后,点击确认创建,任务进入创建流程。创建成功后,您可以在列表中查看任务的状态。
如果资源不足,任务会进入排队队列;资源足够时,进入部署中状态。
自定义卡数模式
默认情况下,资源池中的算力一般按单个 GPU 型号的数量分为 1、2、4、8 卡四种「算力规格」,配备不同的 CPU 核数与内存。需要先选择一种算力规格,并配置 Worker 数量,总 GPU 数量为「算力规格」卡数 × Worker 数量。但是如果 GPU 资源紧张,可能难以保证有足够的同规格 Worker 满足分布式训练要求。
如果开启自定义卡数,则允许 Worker 之间存在卡数差异。请在 Worker 规格列表选定规格,每种 GPU 规格均已列出可启动数量。自定义卡数的值必须小于可启动数量。您可能需要调用训练代码,适应 Worker 之间的 GPU 数量差异。
如果为自定义卡数为 1 - 8 卡,则创建单个 Worker。如果自定义卡数 > 8,则创建多个 8 卡 Worker 和一个非 8 卡 Worker。
注意
- 单个规格的 可启动数量 可能小于该规格全部剩余卡数。可启动数量的计算方式为:剩余完整 8 卡节点的卡数 + 剩余非 8 卡节点中的最大空闲卡数。
- 最佳实践是根据检查资源占用情况确保当前资源池的剩余资源足够满足任务启动需求。
批量任务管理
在实际科研和生产场景中,经常需要同时创建和管理大量相似的任务,这些任务往往仅在启动命令等少量参数上有所不同。针对这一需求,平台推出了「任务组」批量任务管理功能,支持任务的批量创建、批量删除、批量重跑、批量停止,以及同时查看多个任务的监控数据等操作。
通过批量任务管理,用户无需重复填写相同配置信息或逐一操作每个任务,大幅提升了多任务场景下的操作效率和体验。无论是大规模实验、参数调优,还是日常任务维护,批量管理都能帮助用户高效完成任务操作,节省时间和精力,极大提升科研和生产力。
注意
批量创建任务功能仅支持「训练任务」类型的任务。
批量创建任务
批量创建任务(任务组)功能,帮助用户一次性高效提交多个相似任务,无需重复填写相同配置信息,大幅提升操作效率。用户只需填写一次通用配置,然后为每个任务分别填写启动命令和名称,即可一键创建多个任务。其余流程与单个任务创建基本一致,适用于需要同时运行多组实验或大批量任务的场景。
操作流程:
在智算云平台任务列表页面点击 创建任务,选择「任务组」,进入创建任务组界面,可批量创建单机或分布式任务。
先填写任务组的通用配置(如资源池、镜像等),配置与创建单个训练任务一致。
点击下一步进入任务配置,分别填写每个任务的启动命令、名称(可选描述)。如果启动命令相同或类似,可在填写第一个任务的启动命令后,开启自动填充和自动编号,点击添加任务,系统会自动复制和填充剩余任务的启动命令,并自动编号。
确认后批量提交,系统会依次创建所有任务。
合并任务为任务组
合并任务为任务组功能,支持用户将已创建的多个相似训练任务归类整理,统一纳入一个任务组进行管理。这样不仅便于批量查看、监控和后续操作,也方便对实验进行分组和归档。合并时可自定义任务组名称和描述,合并后的任务组不会影响原有任务的运行状态。
注意
合并任务为任务组功能仅支持「训练任务」类型的任务。
操作流程:
在智算云平台任务列表页面,使用复选框选择需要合并的训练任务。
点击底部合并任务按钮,进入合并任务组界面。
填写任务组名称,描述后提交。
删除任务组
删除任务组功能,支持用户将已创建的任务组删除。删除后,任务组不再可见,但任务本身不会被删除。
查看部署进度
任务进入部署中状态后,将会执行一系列子操作。仅在所有 Worker 均完成一个子状态的情况下,任务才会进入下一个子状态。
如果任务长时间停留在部署中状态,建议在任务列表的状态栏中点击 ... 图标,在打开的弹窗中查看的详细进度。

如果在任何子状态发生错误,平台会自动重试。如果进度长时间停留在错误状态且无法恢复,建议停止任务,并重新发起。如果问题持续存在,请联系售后服务。
重跑训练任务
如果任务训练代码有误,或者需要修改配置后重新发起训练,可以点击任务列表中的重跑按钮,无需重复创建任务。
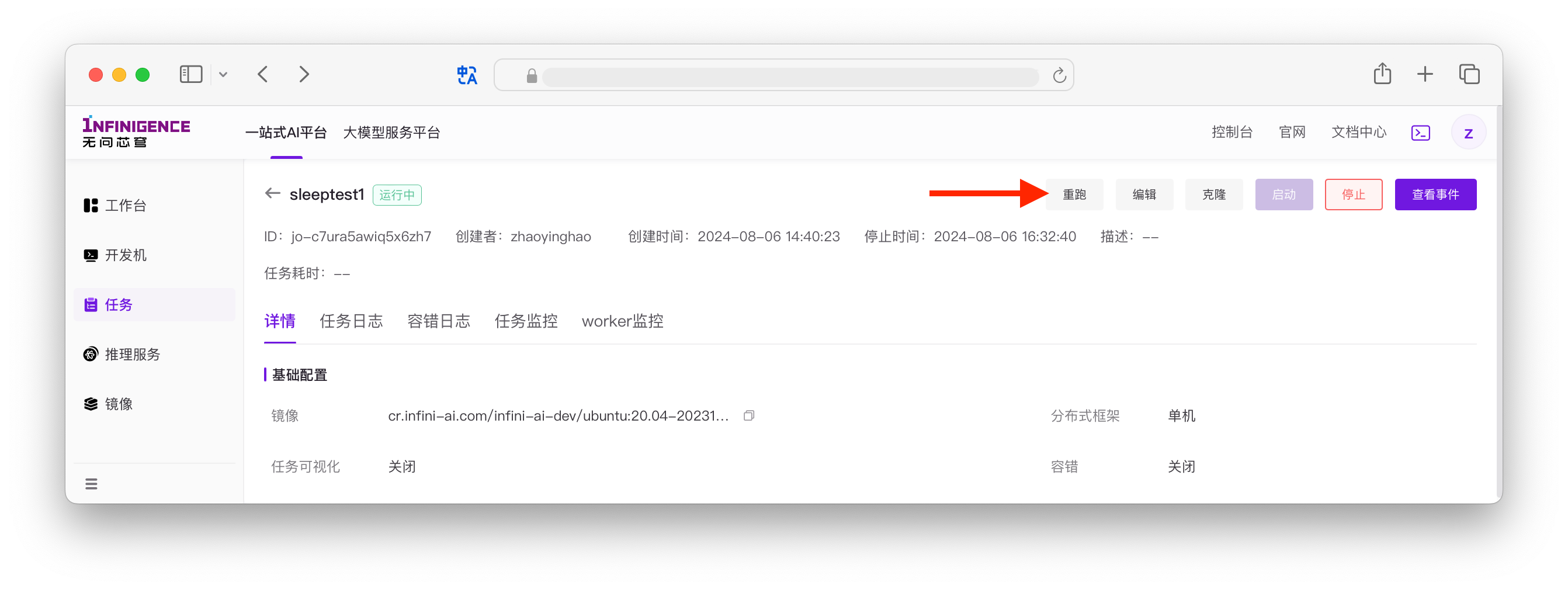
如果选择改配重跑,可修改任务启动命令、Worker 规格、Worker 数量、镜像等。
提交重跑任务后,任务进入清理中状态,随后开始重新部署。
警告
不支持修改任务的资源类型、资源池、名称和描述。
获取训练结果
训练任务结束后,容器本地的文件系统会被销毁。因此,必须将训练结果(如模型权重、Checkpoints、日志等)保存到挂载的共享高性能存储中。
确认存储位置
在编写训练代码或设置启动命令时,请确保输出路径指向挂载的共享存储目录。
例如,如果您将共享存储挂载到了 /mnt/public,建议将结果保存到类似 /mnt/public/my-project/checkpoints/ 的路径下。
警告
请勿将重要结果仅保存在 /tmp、/root 或 /workspace 等容器本地路径,这些数据在任务结束(成功或失败)后将无法找回。
查看与下载结果
任务运行中或结束后,您可以通过以下方式访问存储在共享存储中的文件:
方式一 使用 AICoder(推荐)
AICoder 是平台提供的免费 CPU 实例,挂载了同可用区的共享存储。
- 在顶部导航栏打开 AICoder,选择与训练任务相同的可用区。
- 在终端中进入共享存储挂载目录(如
/mnt/public),即可查看、管理训练结果。 - AICoder 内置了 File Browser,支持通过网页直接浏览和下载文件。请勿依赖网页端传输大文件。如果需要将大量数据或模型权重下载到本地机器,推荐使用
rsync工具,支持断点续传,稳定高效。更多传输方式(如 SCP, SFTP, VS Code 等)请参考数据传输指南。
方式二:使用开发机
您可以创建一个开发机,并挂载相同的共享存储卷。登录开发机后,即可像操作本地文件一样处理训练结果。开发机支持通过 如 SCP, SFTP 等方式将数据或模型权重下载到本地机器。参考开发机传输文件指南。
注意
部分可用区可能存在网络限制,开发机无法连接公网。
常见问题
有些任务明明出错了,为什么显示的事件和状态为任务成功呢?
平台对任务状态识别与 worker 的主进程退出码有关系:
- 当有一个 worker 的主进程退出码为非 0(如 -1),任务的状态就会被标记为任务失败。
- 正常情况下,worker 主进程正常结束的退出码是 0,此时就认为容器成功执行而退出,任务状态就是成功。
也就是说,如果您的启动命令最后一条命令总是会成功,则可能会导致平台任务状态识别障碍。例如:
启动命令最后一行为
echo之类的命令。启动命令中最后使用管道命令和
tee将日志写入文件(tee总是会执行成功)。shellbash profiling_gpt_70b.sh 2>&1 | tee /mnt/public/algm/tanzheyue/outputs/logs/profiling-70b-${HOSTNAME}.log
如遇到以上情况,请参考改进 2 使用 set -o pipefail 捕获管道中的错误。
任务列表和任务详情页的「任务耗时」是如何计算的?
- 在 2025 年 8 月 18 日之前创建的任务,任务耗时包括三个状态的总时长:「排队中」、「部署中」、「运行中」。
- 在 2025 年 8 月 18 日及之后创建、重启的任务,不再计入「排队中」、「部署中」耗时,仅记录任务最近一次处于「运行中」的耗时。