

发起微调任务
本节指导您如何在 GenStudio 上快速完成一个模型微调任务。
微调任务的简要流程如下:
注意
本功能仅向企业级客户授权开放。非授权客户无功能入口。如需使用,请联系商务或售后服务。
支持微调的模型
GenStudio 支持对多种预置模型进行微调。
- 智谱 AI:
chatglm3-6b-base - 阿里云:
qwen1.5-7b-chat - 阿里云:
qwen2-7b - Meta:
llama-2-7b-chat
基础模型决定了微调后模型在语言、理解、推理等方面的能力基准线。
要了解各模型的详细介绍,请参考模型列表或访问智算云控制台的模型广场。
准备工作
开始前,请完成以下准备工作:
- 确认基础模型:您将在创建微调任务时选择一个用于微调的基础模型。
- 确认微调方式:微调任务现支持以下方式:
- 全量微调 (Full-parameter Fine-tuning):更新模型的所有参数。此方式消耗更多时间和资源,适合需要让模型学习全新知识或能力的场景。
- LoRA (Low-Rank Adaptation):仅更新权重矩阵的低秩分解部分,是一种成本更低、效率更高的训练方式。
- 准备数据集:准备用于微调的业务数据集,并确保其满足以下要求:
- 格式:
jsonl文件。目前仅支持单个数据集文件。 - 访问性:可通过公开的 URL 地址访问。目前仅支持从第三方来源导入。
- 内容结构:可参考平台提供的示例数据集来准备您的数据。
- 格式:
创建微调任务
访问智算云控制台的创建微调服务页面,即可开始创建任务。
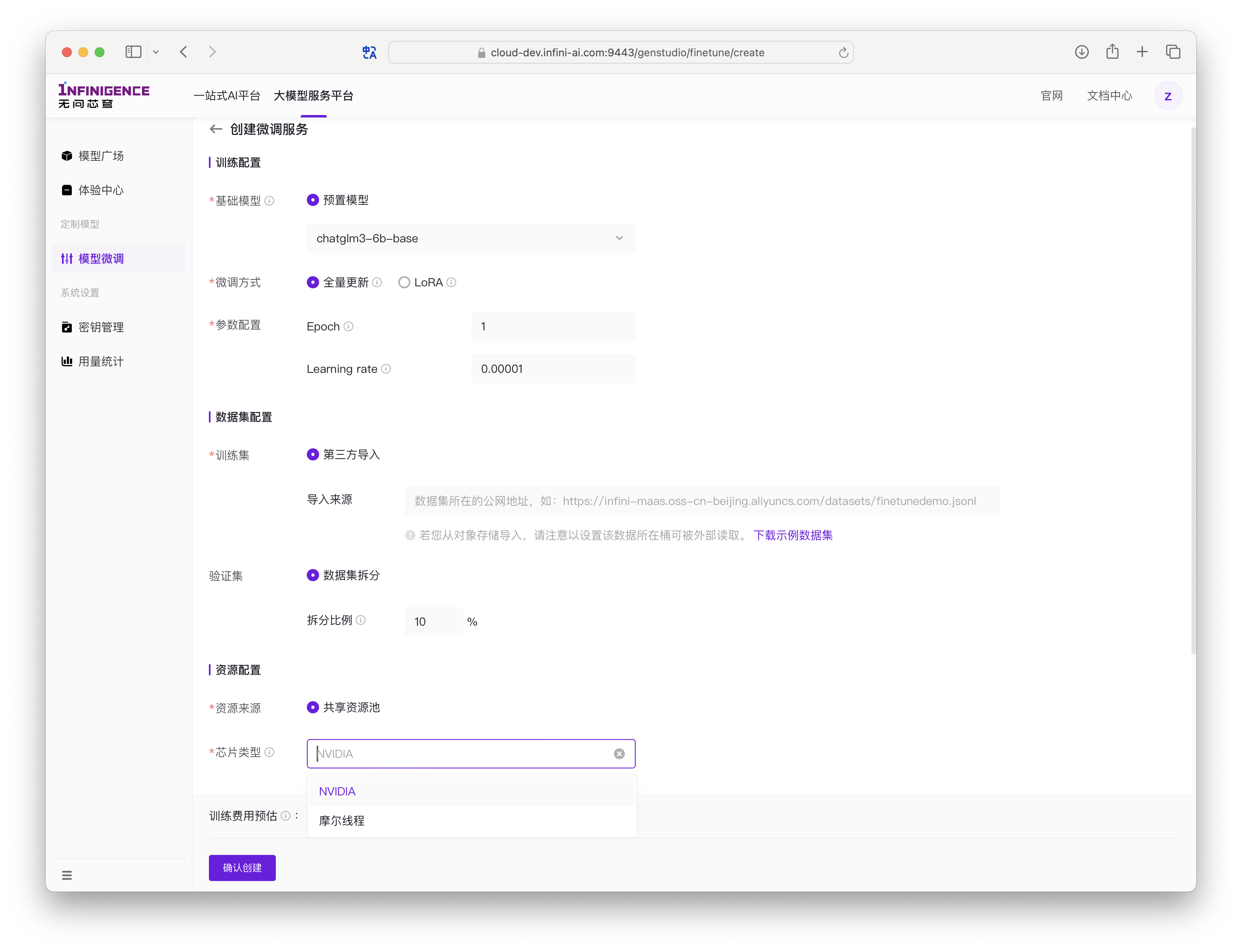
进入创建页面后,请根据页面提示完成以下配置。
训练配置
| 字段 | 描述 |
|---|---|
| 基础模型 | 决定微调后模型的能力基准线。详情参见支持微调的模型。 |
| 微调方式 | 支持全量微调、LoRA。此选项会影响下方可配置的微调参数。 |
平台会提供默认的预置参数,您可根据需求调整。
通用参数:
- Epoch:训练数据集的完整迭代轮次。迭代轮数越多,训练时间越长。请根据数据规模适当调整。
- Learning rate (学习率):控制模型在训练过程中更新权重的速度,影响收敛速度。
LoRA 专有参数:
- LoRA Rank:LoRA 权重矩阵的秩。秩越大,可训练参数越多,但可能会降低训练速度并增加显存消耗。
- LoRA Alpha:LoRA 的缩放系数,与
LoRA Rank共同决定最终的缩放效果 (lora_alpha / lora_rank)。 - LoRA Dropout:在训练中随机停用一部分神经元,以防止过拟合。
注意
- 不同模型支持的微调方式可能不同。
- 为确保微调任务顺利运行,请在了解各参数含义及影响后再进行调整。
数据集配置
| 字段 | 描述 |
|---|---|
| 训练集 | 填写业务数据集的 URL 地址。 |
数据集 URL 示例:
- 从魔搭社区导入:
https://www.modelscope.cn/api/v1/datasets/{组织}/{数据集}/repo?Revision=master&FilePath={文件名}.jsonl - 从公网可读的对象存储导入:
https://{BucketName}.{Endpoint}/{ObjectName}.jsonl - 使用平台 Demo 数据集:如果您暂时没有可用的数据集,可使用我们的 Demo 数据集进行体验。
提示
平台无法访问您的私有数据,因此请确保您填写的 URL 具有公共读权限。您可以在所使用的云存储(如阿里云 OSS、腾讯云 COS 等)中为文件配置相应权限。如果您的存储提供商不在主流支持范围内,请联系我们的商务(pre-sales@infini-ai.com)进行验证。
资源配置
| 字段 | 描述 |
|---|---|
| 资源来源 | 默认使用共享资源池。 |
| 芯片类型 | 部分模型支持多种芯片类型。不同芯片的训练单价可能不同,您可按需选择。 |
注意
受限于资源可用性,摩尔线程芯片已暂时下线。如有需求,请联系商务或售后服务。
基本信息
| 字段 | 描述 |
|---|---|
| 名称 | 微调任务的名称。最多 64 个字符,支持中英文、数字、- 和 _。 |
| 描述(可选) | 任务的详细描述,上限 400 字符。 |
提交后,任务将开始执行。根据模型大小和数据量,所需时间可能不同。
查看微调任务进度与详情
在“模型微调”页面,您可以查看所有已创建的微调任务。点击任务名称或详情按钮,即可进入任务详情页。
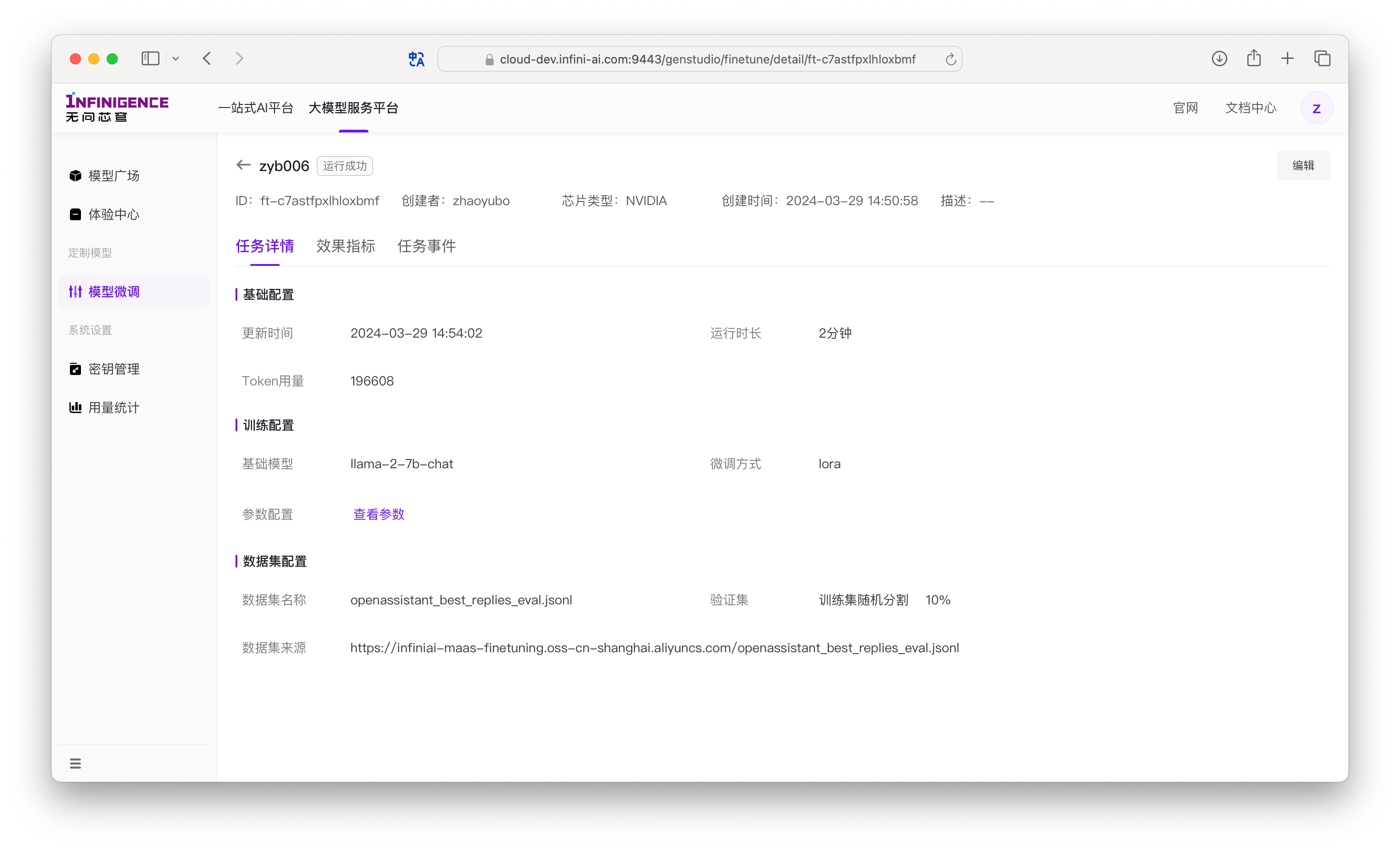
详情页包含三个标签页:任务详情、效果指标和任务事件。
任务详情页
此页面展示了任务的配置和实时统计信息。
- 基本信息:
- 运行时长:任务从获取资源并启动后,累计运行的时间。
- 剩余时长预估:根据当前进度预估的剩余完成时间。
- Token 用量:已累计训练的 Token 总量。计算公式为:
已完成的 Epoch 数 * 数据集 Token 数。
- 训练配置:
- 您在创建任务时选择的基础模型、微调方式和超参数。可点击查看参数回顾所有配置。
- 数据集配置:
- 您提供的数据集 URL。
- 验证集:显示您设置的从训练集中随机划分的验证集比例。若比例为 0,则表示没有使用验证集。
效果指标页
此页面内嵌了 TensorBoard,用于可视化展示训练过程中的各项指标(如 Loss)随迭代进度的变化趋势。
任务事件页
此页面按时间顺序列出了任务生命周期中的关键事件,帮助您了解任务的详细进度和状态。常见事件包括:
- 创建完成:您已成功提交微调任务。
- 排队中:任务正在等待调度系统分配计算资源。
- 部署中:资源已分配,正在准备运行环境。
- 数据处理中:任务已启动,正在对数据集进行预处理。
- 运行中:任务正在进行正常的模型训练。
- 模型生成中:所有迭代已完成,正在生成最终的模型文件。
- 模型已保存:生成的模型已成功保存。
- 训练成功:任务已成功完成所有指定的迭代轮次。
- 停止中 / 训练终止:您手动停止任务时的中间状态和最终状态。
- 训练失败:因数据集格式错误、资源不足等原因导致任务中断。
- 任务更新:您编辑了任务的名称或描述。
微调最佳实践
为了获得更好的微调效果,我们建议您:
- 选择高质量数据集:数据集的质量直接影响微调效果。
- 确保数据格式正确:参考平台提供的示例,确保您的
jsonl文件格式无误。 - 保证足够的样本量:建议至少包含 100 个样本,过少的样本难以达到理想效果。
- 合理调整训练参数:
- 若数据集较小,可适当减小学习率(Learning rate)并增大迭代轮次(Epoch)。
- 若数据集较大,可适当增大学习率并减小迭代轮次。
- 选择合适的微调方式:
- 对于相对简单的任务,优先选择 LoRA,以获得更快的训练速度和更少的资源消耗。
- 对于复杂度高的任务,可选择全量微调,效果可能更好,但时间和算力成本也更高。
- 合理设置验证集比例:验证集过小可能无法准确评估模型表现,过大则会减少训练样本数量。
部署微调模型
微调任务成功后,会生成一个定制化的 LoRA 模型。您可以将此模型一键部署为在线服务,平台会为其提供 API 调用和 Web UI 交互界面。
常见问题
为什么我无法使用微调功能?
请确认您的租户是否已完成企业认证。
若您非超级管理员,可能需要额外的权限。使用微调功能要求当前用户账号至少拥有大模型平台开发者角色,或已关联包含此权限的自定义策略。如遇权限不足,请联系您租户的超级管理员。详情请参见用户账号与权限策略。
为什么我上传的数据集无法使用?
请检查数据集是否满足以下要求:
- 文件为
jsonl格式,每行是一个 JSON 对象。 - 文件可通过公网 URL 直接访问,无需额外鉴权。若使用对象存储(如 OSS),请为文件开启公共读权限。
如仍有疑问,请联系我们获得进一步的技术支持。
常⻅问题
为什么无法使用微调功能?
请检查租户是否已完成企业认证。
如果您当前使用账号并非超级管理员,您可能会遇到权限不足的提示。使用微调功能要求当前用户账号至少有大模型平台开发者权限,或已用户已关联的自定义策略允许该功能。如遇到权限不足问题,请联系租户的超级管理员。详见用户账号与权限策略。
为什么我上传的数据集⽆法使⽤?
请检查数据集是否符合以下要求:
- 为jsonl格式⽂件,每⾏为⼀个 JSON 对象,表⽰⼀个训练样本。您可参考 GenStudio 提供的数据集⽰例,了解数据集的格式要求。
- 数据集⽂件可通过公⽹ URL 直接访问,不需要单独的鉴权。如使⽤ OSS 等对象存储,需要给⽂件开启公共读权限。
如仍有疑问,请联系我们获得进⼀步技术⽀持。