

微调服务概述
⼤模型服务平台 GenStudio 提供在线模型微调服务,基于预置基础模型执行全量或 LoRA 微调,配置训练/资源/数据集参数,实时查看 Loss 与进度,产出可直接部署的新模型版本,帮助您快速创建适合特定任务的定制化模型。
微调可以带来以下优势:
- 提⾼模型在特定任务上的表现
- 减少推理时的上下⽂⻓度,降低延迟
- 使模型输出更符合特定的要求
GenStudio ⽀持多种主流的微调⽅式,包括全参数微调和参数⾼效微调(LoRA)等,并且适配了多种主流和国产芯⽚,让您⽆需关注复杂的算法和硬件细节,即可享受⼤模型微调服务。
基本操作
智算云控制台的模型微调页面提供了基本的增、删、查等操作。
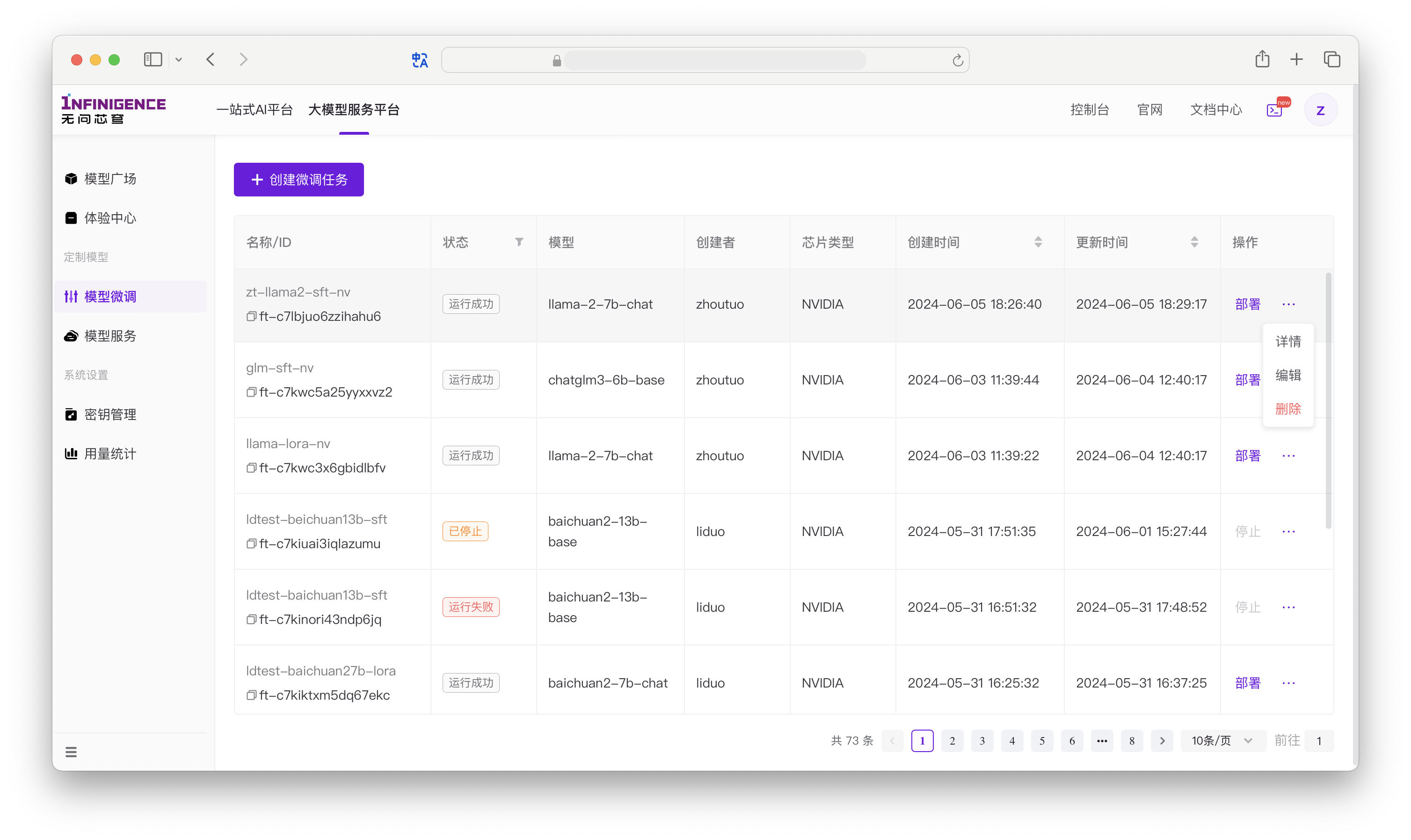
- 创建微调任务:详细步骤参见发起微调任务。
- 停止微调任务:在微调任务列表中右侧操作栏中。停止操作需二次确认。微调任务一旦被终止,无法再重新启动。
- 删除微调任务:在微调任务列表中右侧操作栏中。删除操作需二次确认。
注意
在详情页面可以修改微调任务。当前仅支持编辑任务名称和描述。
服务计费
我们采取透明的计费方式,帮助您根据实际需要合理安排资金预算。
智算云平台的产品计费主要基于实际的 Token 用量,确保您按照实际使用量付费。同时,现阶段提供 Token 限免体验,以收集用户反馈并优化体验。
微调费用计算
微调服务支持对主流模型进行个性化调整,以满足特定的业务需求。计费逻辑基于微调任务的配置详情:
| 微调配置项目 | 单位 | 微调单价(元/k tokens) | 示例用量 | 费用计算公式 |
|---|---|---|---|---|
| 数据集 Tokens 总量 | tokens | - | 100k | - |
| 迭代轮次(Epoch 数量) | epoch | - | 3 | - |
| 模型芯片训练单价 | 元/k tokens | X | - | 100 * 3 * X = 总费用(300X元) |
费用计算示例:
若您使用含有 100k Token 的数据集,进行 3 轮 Epoch 迭代,选择在 A 卡上使用模型 1 进行微调,单价为 X 元/k Token,则微调费用如下计算:
100k Token * 3 Epoch * X元/k Token = 300X 元
注意事项
- 所有费用均以实际使用量为准,我们将提供详细的使用报告供您核对。
- 后续我们计划推出资源包、配额等多元化计费选项,为您提供更多灵活的选择。