

在推理服务中使用自定义镜像
本章节将介绍如何在推理服务中使用自定义镜像。
制作自定义镜像
本教程中以常见的第三方推理框架为例,制作自定义镜像。
假设您需要使用 Xinference 框架,只安装必要的推理引擎,可以直接从 AIStudio 平台镜像中心在线构建自定义镜像。
例如,PyTorch(transformers) 引擎支持几乎所有的最新模型。在上方页面点击构建镜像按钮,选择基于 Dockerfile 构建一个只包含 Transformer 引擎的 Xinference 镜像:
FROM cr.infini-ai.com/infini-ai/ubuntu:22.04-20240429
RUN python3 -m pip install --upgrade pip && \
python3 -m pip install --no-cache-dir "xinference[transformers]" sentence-transformers又例如,使用支持高并发的高性能大模型推理引擎 vLLM,可使用以下 Dockerfile 构建镜像。
FROM cr.infini-ai.com/infini-ai/ubuntu:22.04-20240429
# Install necessary Python packages with no cache to reduce the image size.
RUN python3 -m pip install --no-cache-dir "xinference[vllm]" \
&& python3 -m pip install --no-cache-dir flashinfer -i https://flashinfer.ai/whl/cu121/torch2.4/等待自定义镜像构建完成,即可在 AIStudio 平台使用该镜像创建推理服务等。
准备模型文件
最佳实践是提前准备模型文件,并放置模型文件至共享高性能存储。
您可以使用开发机或免费的 AICoder 读写共享高性能存储。以下示例中直接从外部下载了一个模型文件。
# 创建任意目录
mkdir -vp /mnt/public/models
cd /mnt/public/models
# 从 modelscope 下载模型
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
# 下载完成后,确保模型目录内存在 .safetensors 文件
ls -alht /mnt/public/models/Qwen2.5-0.5B-Instruct注意
如果您选用的预置推理镜像中的框架支持自动下载模型,且模型文件较小,也可以在启动命令中指定框架将模型下载到实例挂载的共享高性能存储或本地存储中。
创建推理服务
访问智算云控制台的推理服务页面,可创建推理服务。
进入创建页面后,请根据页面提示,完成以下配置。
如果使用自定义镜像,请根据当前推理环境,编写服务的「启动命令」。以 Xinference + transformer 引擎为例,启动一个 JINA AI 的向量嵌入模型
jina-embeddings-v2-base-zh: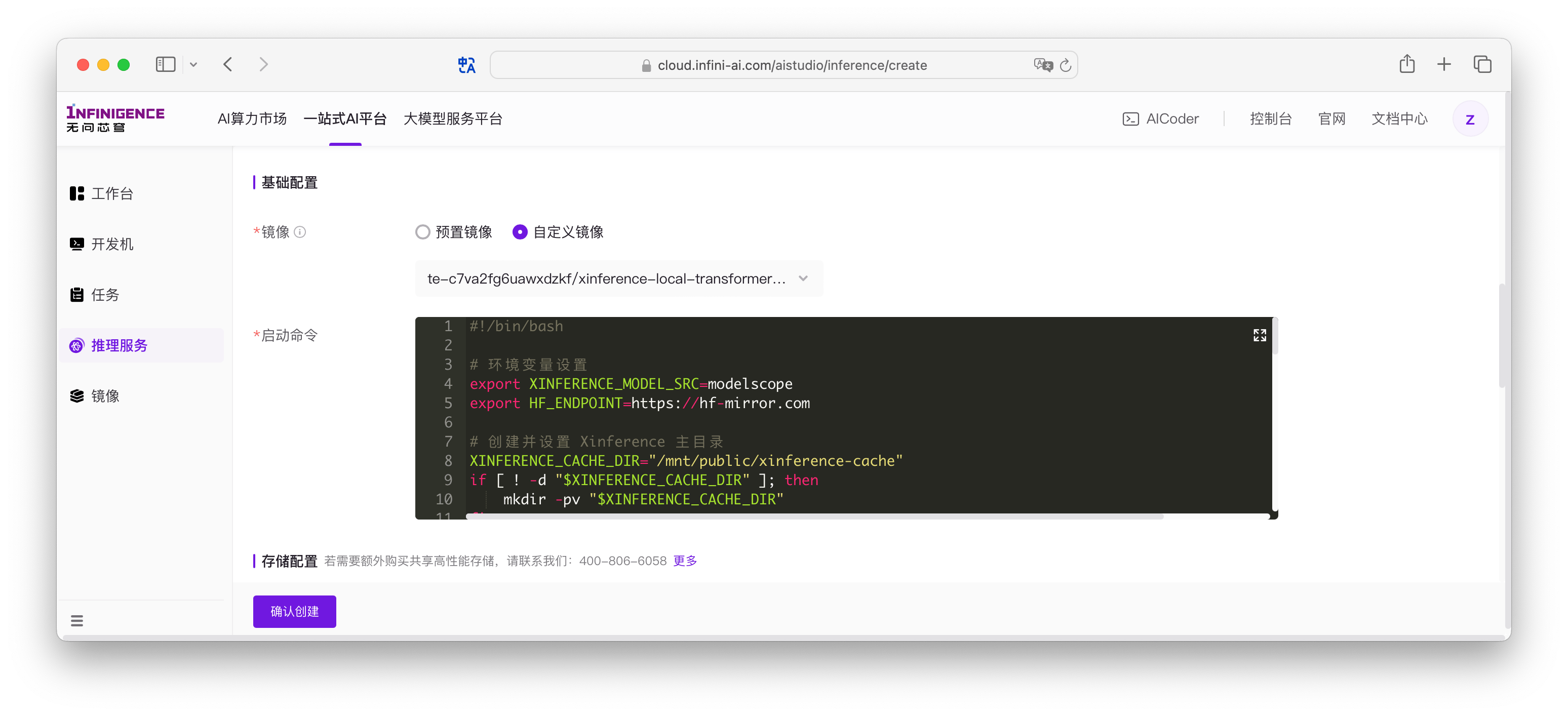
因为 embedding 模型较小,可让 Xinference 在启动模型时直接从 modelscope 下载。完整启动命令如下
shell#!/bin/bash # 环境变量设置 export XINFERENCE_MODEL_SRC=modelscope export HF_ENDPOINT=https://hf-mirror.com # 创建并设置 Xinference 主目录 XINFERENCE_CACHE_DIR="/mnt/public/xinference-cache" if [ ! -d "$XINFERENCE_CACHE_DIR" ]; then mkdir -pv "$XINFERENCE_CACHE_DIR" fi export XINFERENCE_HOME="$XINFERENCE_CACHE_DIR" # 创建日志目录 LOG_DIR="${XINFERENCE_CACHE_DIR}/logs" mkdir -p "$LOG_DIR" LOCAL_LOG="${LOG_DIR}/xinference-local.log" # 定义日志前缀函数 add_prefix() { while IFS= read -r line; do echo "[$(date '+%Y-%m-%d %H:%M:%S')] $line" done } echo "正在启动 Xinference 服务..." # 将xinference-local作为主进程运行,而不是放在后台 xinference-local --host 0.0.0.0 --port 9997 2>&1 | tee "$LOCAL_LOG" | add_prefix & # 等待服务可用 echo "等待服务就绪..." max_attempts=60 attempt=0 while ! curl -s http://127.0.0.1:9997 > /dev/null; do attempt=$((attempt + 1)) if [ $attempt -eq $max_attempts ]; then echo "服务启动超时,请检查日志: $LOCAL_LOG" exit 1 fi echo "等待服务启动... (${attempt}/${max_attempts})" sleep 1 done echo "服务已就绪,正在加载模型..." xinference launch --model-name jina-embeddings-v2-base-zh --model-type embedding --model-engine transformers echo "模型已加载,服务继续运行中..." echo "可以通过 'tail -f ${LOCAL_LOG}' 查看服务日志" echo "按 Ctrl+C 停止服务" # 等待后台服务 wait虽然可以直接在启动命令窗口中编写启动服务的代码,但更推荐将启动命令封装成脚本,放置在共享高性能存储,从启动命令中引用。
提示
请特别注意容器的生命周期管理,在启动命令中需要有一个前台运行的主进程。如果全部服务均被放入后台,当容器的启动命令执行完毕,平台会认为容器的主进程已经结束,导致容器陷入销毁与创建的循环。
推理服务依赖的模型和代码可放置在共享高性能存储中。创建推理服务时,可保持平台默认创建的挂载点。

- 系统盘: 推理服务实例的
/目录的存储大小,固定 50GiB。 - 高性能存储:挂载租户的共享高性能存储(例如,您可以将模型文件放在共享高性能存储中)。详见共享高性能存储。
- 系统盘: 推理服务实例的
配置推理服务是否支持从公网访问访问,监听端口以及内网访问端口。
警告
- 请务必根据推理服务要求配置监听端口。本示例中 Xinference 运行在 9997 端口,因此监听端口应修改为 9997。
- 如需要提供 UI 访问服务,请保留
80调用端口。本示例中 Xinference 提供 UI 界面,因此调用端口保留了 80。
推理服务支持自动扩缩容与定时扩缩容。首次部署服务时,建议保持扩缩容为关闭状态,先完成服务部署流程。
注意
后续根据实际情况选择手动扩缩容、定时扩缩容或自动扩缩容。使用方法详见扩缩容。
最后填写推理服务的名称与描述。
- 名称: 推理服务名称,最多 64 个字符,支持中英文数字以及- _。
- 描述: 可为服务添加添加自定义描述,上限 400 字符。
- 标签: 可新建和绑定自定义标签。资源标签是一组键值对(Key-Value)。您可以通过标签从不同维度对一站式 AI 平台内的资源进行分类与聚合管理,用于按标签筛选等场景。详见标签管理。
根据模型参数量,所需部署时间可能有差异。推理服务进入部署中状态后,将会执行一系列耗时的子操作。如果进度长期停留在部署中状态,建议查看详细部署进度。
常见问题
请移步推理服务常见问题。
参考资料
我们整理常见开源推理框架在 AIStudio 平台的安装教程。您可以在 AIStudio 开发机中安装环境后,保存开发机为镜像。或者根据以下教程中的提示,自行制作 Dockerfile,用于在平台中构建自定义镜像。