

启用任务功能内置的 TensorBoard 服务
本指南将帮助您了解如何在平台「任务」功能中使用内置的 TensorBoard 功能来监控模型训练过程。
阅读本文后,您将能够:
- 配置训练脚本的 TensorBoard 日志目录
- 在平台提交任务时正确填写日志路径
- 使用平台内置的 TensorBoard 服务监控训练
概述
平台「任务」功能内置 TensorBoard 服务,支持实时监控训练指标。使用流程如下:
- 配置训练脚本:指定日志写入目录,训练过程中生成事件文件
- 提交任务:在控制台「任务可视化」中填写日志目录的上级目录(包含所有实验子目录的根目录)
- 查看可视化:平台自动启动 TensorBoard 服务,扫描该目录下所有实验并提供 Web 界面
重要
日志必须写入共享高性能存储
平台的 TensorBoard 服务只能读取挂载的共享存储路径(如 /mnt/shared/)。如果日志写入容器本地目录(如 /tmp/),平台将无法发现这些文件。
提示
如果只需查看当前实验,也可以在「任务可视化」中填写具体的实验子目录。但填写上级目录可以同时查看和对比多个实验的训练曲线。
TensorBoard 核心概念
在开始配置之前,理解 TensorBoard 如何组织实验数据至关重要。
Runs 与目录的关系
TensorBoard 使用文件系统的目录结构来识别实验。每个包含 events.out.tfevents.* 文件的目录被识别为一个 run(实验运行)。
- Run:一次实验执行,对应文件系统中的一个目录
- Tag:run 内部的指标名称,例如
Loss/train、Accuracy/train
注意
writer.add_scalar("exp1/loss", ...) 创建的是一个名为 exp1/loss 的 tag,而不是新的 run。要创建多个 runs,必须使用不同的目录。
--logdir 参数的作用
注意
任务运行期间,平台会自动使用您填写的「日志存储路径」启动 TensorBoard 服务,无需手动操作。平台默认启用 --reload_multifile=true,即使长时间训练产生多个事件文件,也能显示完整历史数据。
以下内容适用于任务结束后,您需要自行启动 TensorBoard 查看持久化日志的场景。详见使用开发机运行 TensorBoard 服务。
TensorBoard 的 --logdir 参数决定了扫描哪些目录来发现 runs。该参数接受任意层级的目录路径:
| 传入路径 | 扫描行为 | 适用场景 |
|---|---|---|
父目录(base_dir) | 递归扫描所有子目录,发现全部 runs | 对比多个实验 |
具体 run 目录(log_dir) | 只加载该目录的数据 | 查看单个实验 |
在平台场景中,日志存储路径应填写 base_dir(父目录),使 TensorBoard 能够发现所有 runs。
目录结构示例
以下表格展示了目录结构与 TensorBoard 显示行为的关系:
| 结构类型 | 目录示例 | TensorBoard 行为 |
|---|---|---|
| 推荐 | runs/exp1/、runs/exp2/ 各含事件文件 | 显示多个可对比的 runs |
| 避免 | runs/ 直接包含事件文件 | 只显示一个 run,无法区分实验 |
推荐多 run 目录结构
以下代码为每个实验创建独立的子目录:
base_dir = "/mnt/shared/tensorboard/runs"
# 实验 1: MNIST 分类
run_name = "mnist_exp1"
writer = SummaryWriter(f"{base_dir}/{run_name}")
# 实验 2: MNIST 不同超参数
run_name = "mnist_exp2"
writer = SummaryWriter(f"{base_dir}/{run_name}")
# 实验 3: LLM 微调
run_name = "llm_finetune"
writer = SummaryWriter(f"{base_dir}/{run_name}")结果目录结构:
/mnt/shared/tensorboard/runs/
├── mnist_exp1/
│ └── events.out.tfevents.*
├── mnist_exp2/
│ └── events.out.tfevents.*
└── llm_finetune/
└── events.out.tfevents.*TensorBoard 左侧面板将显示三个 runs:mnist_exp1、mnist_exp2、llm_finetune,可以勾选对比。
避免单 run 目录结构
以下代码直接写入父目录,没有创建子目录:
base_dir = "/mnt/shared/tensorboard/runs"
# 错误:没有指定 run_name,直接写入 base_dir
writer = SummaryWriter(base_dir)结果目录结构:
/mnt/shared/tensorboard/runs/
└── events.out.tfevents.*所有日志写入同一目录时,TensorBoard 只显示一个 run,无法区分不同实验。
Step 0 创建训练脚本
请在您自己的训练脚本中指定 TensorBoard 日志目录(logdir)。训练过程中,模型的日志(如损失、准确率等)将写入该目录。
以下是一个使用 PyTorch 的简单 Python 训练脚本示例,展示如何配置 TensorBoard 日志目录:
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
# 推荐:使用 3 层目录结构(父目录/实验名/时间戳)
# base_dir 是父目录(根目录),需要提供给平台作为「日志存储路径」
base_dir = "/mnt/shared/tensorboard/runs"
# 方式一(推荐):实验名 + 时间戳,便于组织多类型实验
experiment_name = "my_experiment"
timestamp = datetime.now().strftime("%Y%m%d-%H%M%S")
log_dir = os.path.join(base_dir, experiment_name, timestamp)
# 最终路径:/mnt/shared/tensorboard/runs/my_experiment/20231215-143022/
# 方式二:使用环境变量(适合平台任务克隆/重跑场景)
# experiment_name = "my_experiment"
# run_id = os.getenv('RUN_ID', 'default_run')
# log_dir = os.path.join(base_dir, experiment_name, run_id)
writer = SummaryWriter(log_dir=log_dir)
# 示例模型
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 16)
self.fc2 = nn.Linear(16, 1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.sigmoid(self.fc2(x))
return x
model = SimpleNet()
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 模拟数据
x_train = torch.rand(1000, 10)
y_train = torch.randint(0, 2, (1000, 1)).float()
# 训练循环
epochs = 5
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
# 记录日志到 TensorBoard
writer.add_scalar('Loss/train', loss.item(), epoch)
writer.add_scalar('Accuracy/train', (outputs.round() == y_train).float().mean().item(), epoch)
# 关闭 writer
writer.close()以下是关键点:
- 日志目录(
log_dir):必须指向共享高性能存储路径(如/mnt/shared/tensorboard/runs/...),否则平台无法读取日志。使用时间戳或环境变量确保每次实验生成唯一子目录,详见使用环境变量动态设置 run 名称。 - SummaryWriter:使用 PyTorch 的
SummaryWriter来记录日志到 TensorBoard。您可以记录标量(如损失、准确率)、计算图等。 - 关闭 writer:训练完成后调用
writer.close()以确保日志正确写入。
多任务场景:共享父目录,各用子目录
在同一可用区内,多个训练任务可以挂载相同的共享高性能存储。这意味着不同任务(例如 MNIST 分类和 LLM 微调)可以将日志写入同一个父目录,但必须各自写入不同的子目录:
# 推荐:使用 3 层结构,自动避免冲突
SummaryWriter("/mnt/shared/runs/mnist/20231215-140000/") # MNIST 训练
SummaryWriter("/mnt/shared/runs/llm/20231215-140030/") # LLM 微调# 错误:两个任务写入同一目录
SummaryWriter("/mnt/shared/runs") # 数据会混乱!危险
多个任务同时写入同一目录会导致:
- 不同实验的 loss/accuracy 曲线混在一起
- step 空间冲突,曲线变得无意义
- 无法区分哪条曲线属于哪个实验
高级:使用环境变量同步日志路径
克隆或重跑任务时,训练脚本的日志写入路径和平台「日志存储路径」容易出现不同步的问题。平台支持在两处使用相同的环境变量,确保写入路径和读取路径始终一致。
注意
何时使用此功能
此功能适用于希望 TensorBoard 只显示当前任务的实验数据的场景。如果您希望查看和对比多个实验,请在「日志存储路径」中填写父目录(如 /mnt/shared/runs/),无需使用变量替换。
工作原理
| 步骤 | 操作 | 示例 |
|---|---|---|
| 1. 定义环境变量 | 在平台任务配置页面添加环境变量 | RUN_ID=exp_v1 |
| 2. 脚本读取变量 | 训练脚本使用 os.getenv() 构建写入路径 | log_dir = f"{base_dir}/{run_id}" |
| 3. 平台引用变量 | 「日志存储路径」使用 ${VAR} 语法引用变量 | /mnt/shared/runs/my_experiment/${RUN_ID} |
| 4. 变量替换 | 平台替换变量后启动 TensorBoard | 只读取 /mnt/shared/runs/my_experiment/exp_v1 |
配置示例
训练脚本:
import os
from torch.utils.tensorboard import SummaryWriter
base_dir = "/mnt/shared/runs"
experiment_name = "my_experiment"
run_id = os.getenv('RUN_ID', 'default_run') # 从环境变量读取
log_dir = os.path.join(base_dir, experiment_name, run_id)
writer = SummaryWriter(log_dir)平台控制台配置:
- 环境变量:添加
RUN_ID,值设为exp_v1 - 日志存储路径:填写
/mnt/shared/runs/my_experiment/${RUN_ID}
克隆任务时的操作
克隆任务后,只需修改环境变量 RUN_ID 的值(如 exp_v2),脚本写入路径和 TensorBoard 读取路径会同步更新:
/mnt/shared/runs/
└── my_experiment/
├── exp_v1/ ← 原任务
├── exp_v2/ ← 克隆任务(修改 RUN_ID 后)
└── exp_v3/提示
环境变量方法的优势:
- 单一变量源:变量在一处定义,脚本和平台同步使用
- 克隆友好:重跑任务时只需修改环境变量值,无需改动脚本
- 避免不同步:消除脚本写入
exp_v2但 TensorBoard 读取exp_v1的风险
Step 1 提交训练任务
在完成训练脚本后,您需要通过平台的控制台网页提交训练任务,并指定 TensorBoard 日志目录。
在任务可视化的「日志存储路径」中,请填写 父目录(根目录)路径,例如 /mnt/shared/tensorboard/runs。
重要
填写父目录,而非具体 run 目录
- 如果脚本写入
/mnt/shared/runs/mnist/20231215-140000/ - 在平台填写
/mnt/shared/runs/(父目录) - TensorBoard 会自动发现该目录下的所有子目录(runs),包括
mnist/、llm/等
Step 2 查看 TensorBoard 可视化
一旦训练任务启动,平台会自动为您的任务启动一个 TensorBoard 服务。该服务会读取您指定的日志目录,并提供一个可视化界面,让您可以实时监控训练进度。
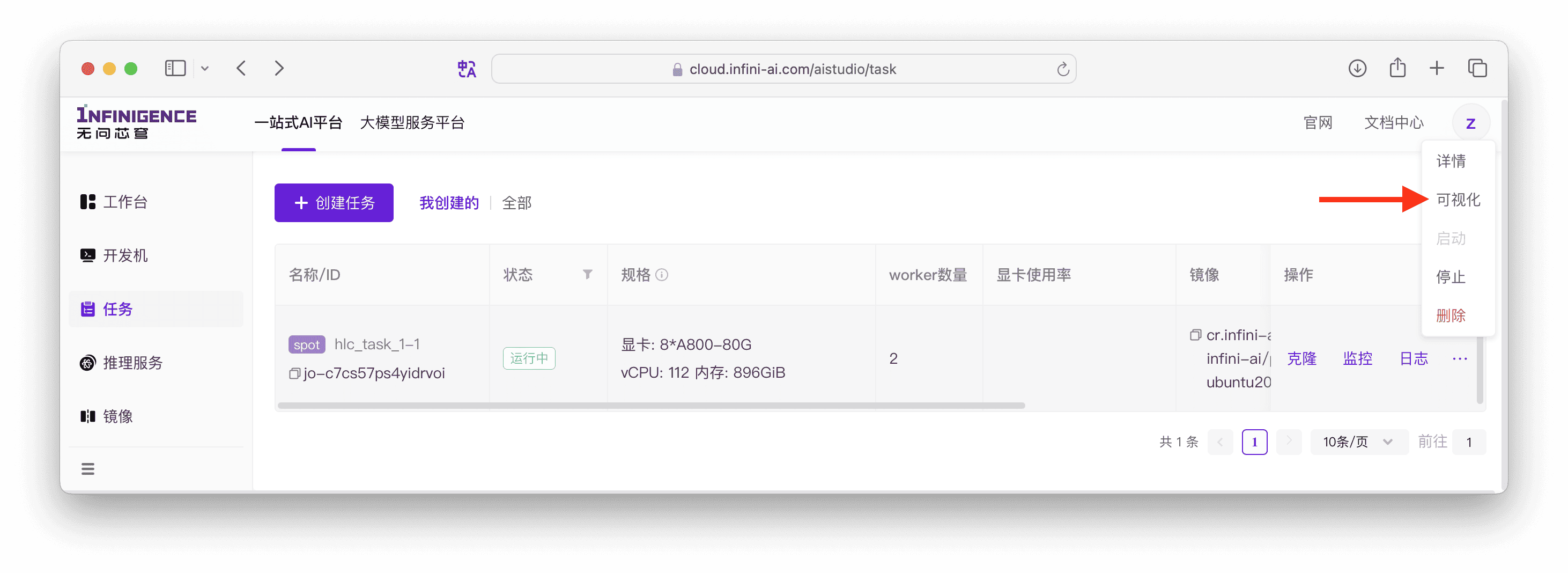
您可在任务列表页的右侧操作栏中找到可视化按钮,直接跳转 TensorBoard 看板。也可以在任务详情页找到可视化按钮。
注意
- 任务结束后,任务可视化按钮失效。如果任务日志持久化保存在共享存储上,您可以自行运行 TensorBoard 看板服务查看日志。例如,可以使用开发机运行 TensorBoard 服务,并指定日志路径为当前训练任务的日志。
- 如果您提交了多个训练任务,每个任务的 TensorBoard 服务是独立的,互不干扰。
修改日志读取路径
在任务运行过程中,如果发现创建任务时填写了错误的日志路径,您可以直接修改「日志存储路径」配置,平台会自动重启 TensorBoard 服务以读取新路径下的日志。
操作步骤如下:
- 进入运行中任务的详情页。
- 找到「任务可视化」配置区域。
- 修改「日志存储路径」。
- 点击提交。
平台会重启 TensorBoard 服务,新路径生效后即可查看更新后的日志数据。
注意
- 修改日志路径仅影响 TensorBoard 的读取位置,不会改变训练脚本的日志写入路径。如需同步修改写入路径,请更新训练脚本或环境变量配置。
- 仅支持在任务运行中时修改日志存储路径。任务处于「删除中」、「运行成功」、「运行失败」、「清理中」状态时无法修改。
常见问题
为什么 TensorBoard 左侧只显示一个 run?
原因:日志直接写入了父目录,而不是子目录。TensorBoard 将每个包含事件文件的目录识别为一个 run。
诊断步骤:
检查日志目录结构:
bashfind /mnt/shared/runs -type f -name "events*"查看输出结果:
问题情况(事件文件在父目录):
/mnt/shared/runs/events.out.tfevents.1702627200.host1正常情况(事件文件在子目录):
/mnt/shared/runs/exp1/events.out.tfevents.1702627200.host1 /mnt/shared/runs/exp2/events.out.tfevents.1702627300.host1
解决方案:
修改训练脚本,确保每次实验写入独立的子目录:
# 错误:直接写入父目录
writer = SummaryWriter("/mnt/shared/runs")
# 正确:写入子目录
writer = SummaryWriter("/mnt/shared/runs/exp1")SummaryWriter() 不指定路径时,日志写到哪里了?
如果调用 SummaryWriter() 或 SummaryWriter("runs") 而不使用绝对路径,日志会写入当前工作目录(CWD)下的 runs/ 文件夹。
警告
当前工作目录取决于 Python 进程的启动位置,不是脚本文件所在目录。在容器、Jupyter、Slurm 任务中,CWD 可能出乎意料。
建议:始终使用绝对路径,避免混乱。
# 避免
writer = SummaryWriter()
writer = SummaryWriter("runs")
# 推荐
writer = SummaryWriter("/mnt/shared/tensorboard/runs/mnist/20231215-140000")多 GPU(DDP)训练如何正确记录日志?
在使用 DistributedDataParallel 进行多 GPU 训练时,只应在 rank 0 进程写入 TensorBoard 日志,否则会导致重复记录:
import torch.distributed as dist
# 只在主进程创建 writer
if dist.get_rank() == 0:
writer = SummaryWriter(log_dir)
else:
writer = None
# 训练循环中
if writer is not None:
writer.add_scalar('Loss/train', loss.item(), step)