

发起 HuggingFace 训练服务
AIStudio 一站式平台支持使用内置 HuggingFace 框架发起自定义训练。用户需自行提供模型、数据集和训练脚本,以简化训练流程。平台将动态调度空闲算力资源,每项任务按预估时长独立定价并单独结算。本节将指导您完成相关操作。
注意
- 该功能需创建训练服务类型的任务,目前内测邀请中。申请体验,请联系商务或售后服务。
- 平台另提供 DeepSeek 训练服务,内置模型、框架和脚本,用户仅需提供微调数据集及部分参数。详见 发起 DeepSeek 训练服务。
使用流程
使用内置 HuggingFace 框架进行自定义训练的简要流程如下:
训练模式
创建训练服务时,选择 HuggingFace 框架 训练模式,即使用内置 HuggingFace 训练环境。用户需基于此环境提供模型、数据集和训练脚本。训练服务将解析脚本,并根据算力情况动态优化资源配置。
注意
当前 HuggingFace 框架训练模式仅支持单机(最多 8 卡),不支持多机训练。
环境
平台将在专用训练环境中运行您的脚本,可参考以下配置:
基础环境镜像:nvcr.io/nvidia/pytorch:24.09-py3
在此镜像基础上安装以下依赖,以适配平台训练环境:
pip install --upgrade huggingface_hub
pip install datasets
pip install evaluate
pip install accelerate
pip install transformers==4.43.4提示
- 请参考以上环境信息,调整您的训练脚本。确保无环境问题后再提交训练服务。
- 平台镜像中心已提供基础环境镜像:
nvcr.io/nvidia/pytorch:24.09-py3。您也可以通过开发机先行调试,调试完毕后再发起训练服务。
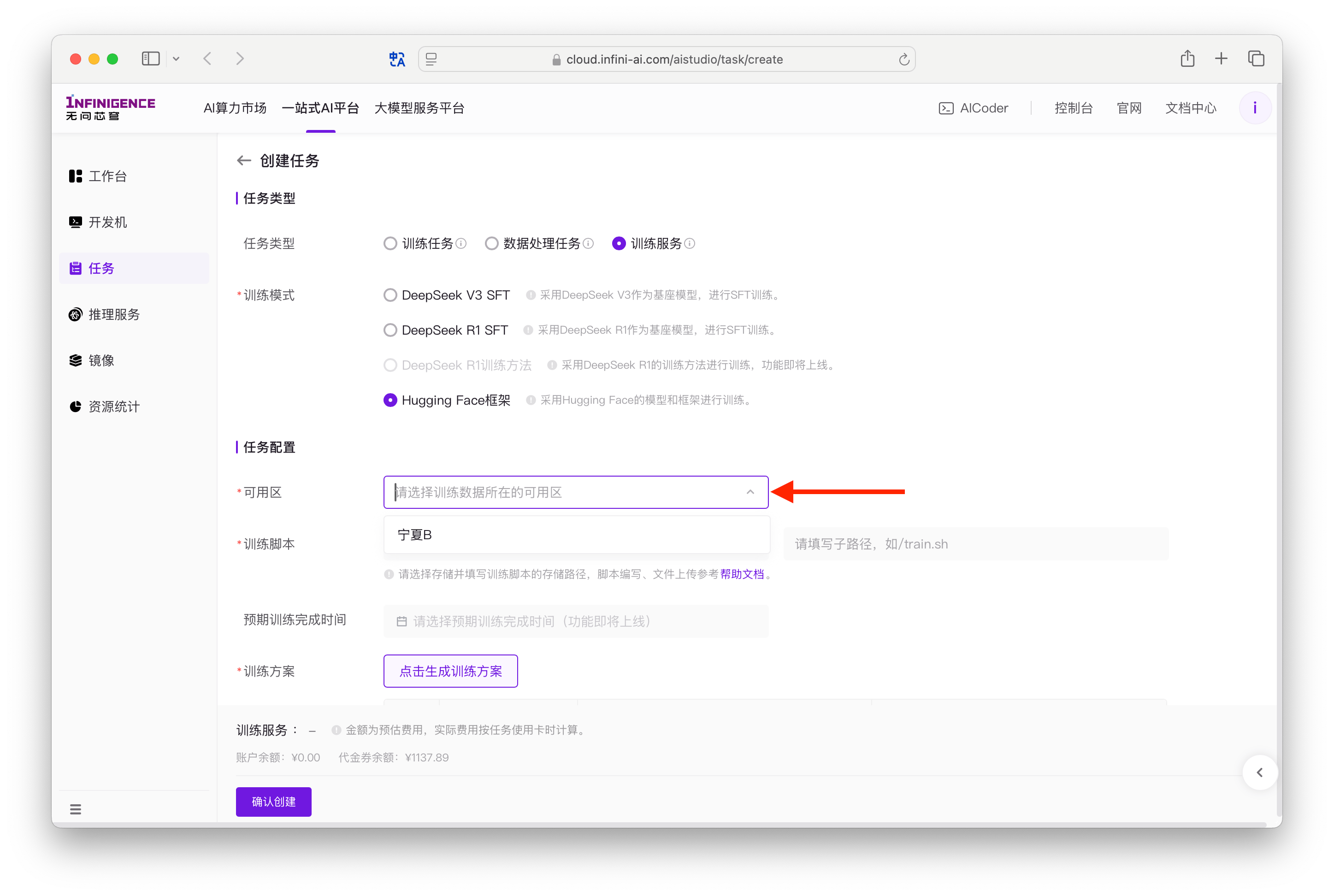
查询可用区
训练服务在多个可用区提供按量付费算力资源。由于用户数据(数据集、模型与训练脚本)需要提前部署到可用区的共享存储中,因此建议您提前确认可用区。
尝试创建训练服务,「可用区」下拉列表即为当前所支持的可用区。
注意
此处只需确认您后续计划选用的可用区,例如「宁夏B」,无需继续创建任务。
准备数据
由于训练服务在多个可用区提供使用 HuggingFace 框架的训练模式,您的所有训练数据必须上传至训练服务所在可用区的共享存储目录中。
注意
为避免存储访问问题,请确保您的数据与训练服务算力位于同一可用区。不同可用区之间的存储资源相互隔离,无法跨区直接使用。请按照下文指导进行配置。
模型与数据集
平台暂不提供预置模型和数据集。您需要自行上传模型与数据集,供训练服务使用。
由于训练数据必须与训练服务算力位于同一可用区,建议您先查询当前支持的可用区。
注意
- 此处只需确认您后续计划选用的可用区,例如「宁夏B」,无需继续创建任务。
- 由于模型与数据集下载受多种因素影响。为保证高效利用资源,建议提前下载模型与数据集。您可以直接利用 AICoder 下载公有模型与数据集,或通过 AICoder 上传自有数据至选定可用区的共享存储中。
脚本
训练服务会负责运行您提供的训练脚本。请严格遵照平台对训练脚本规范撰写脚本。
Shell
以下 Shell 脚本示例已包含了训练服务 Shell 脚本的最佳实践:
PYTHON_FILE="/mnt/public/train/run_clm_sft.py"
OMP_NUM_THREADS=16 python -m torch.distributed.run \
--nproc_per_node 8 \
--nnodes 4 \
--node_rank $RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT \
$PYTHON_FILE \
$DATA_ARGS \
$TRAIN_ARGS \
--do_train \
--seed $RANDOM \
--bf16 \
--lr_scheduler_type cosine \
--warmup_ratio 0.01 \
--weight_decay 0.1 \
--logging_strategy steps \
--save_strategy epoch \
--save_total_limit 10 \
--dataloader_num_workers 8 \
--overwrite_output_dir True \
--ddp_timeout 30000 \
--logging_first_step True \
--torch_dtype bfloat16 \
--gradient_checkpointing \
--ddp_find_unused_parameters False 2>&1 | tee $OUTPUT_DIR/train.log其他注意事项:
- 必须使用
python -m torch.distributed.run发起训练。 - 请直接在 Shell 脚本中调用
python -m torch.distributed.run。请避免在 Shell 脚本中嵌套调用其他 Shell 脚本,并在嵌套脚本中发起训练。 - 训练服务运行过程中可根据资源可用情况动态调整
--nproc_per_node与--nnodes,您无需在意脚本中设置的具体值。但目前最多支持单机 8 卡。 - 以下为训练服务提供的预置变量,在脚本中无需定义,直接使用即可:
$RANK$MASTER_PORT$MASTER_ADDR
- 不得修改
transformers库或版本。 - 通常不建议额外安装依赖项。如必须安装其他依赖,建议在开发环境充分测试后,通过
pip install -y指定要安装的库。 - 请避免在 Shell 脚本中加入判断或循环逻辑。
Python
如果要对接平台的 TensorBoard 日志可视化服务,需要在 Python 训练脚本中将日志写入符合平台要求的路径,供平台 TensorBoard 服务读取。
平台读取 TensorBoard 日志路径为 Shell 脚本在共享存储的父目录。
例如,假设训练服务数据上传后,共享存储目录为 /mnt/public,训练脚本路径为 /train/train.sh,则平台将会在 /mnt/public/train/ 目录下读取 TensorBoard 日志。
上传数据
建议通过智算云平台免费提供的 AICoder 将数据上传到目标可用区的共享存储目录。
建议通过免费的 AICoder 上传模型只共享存储中。请在顶部导航激活 AICoder,选择您计划选用的可用区。
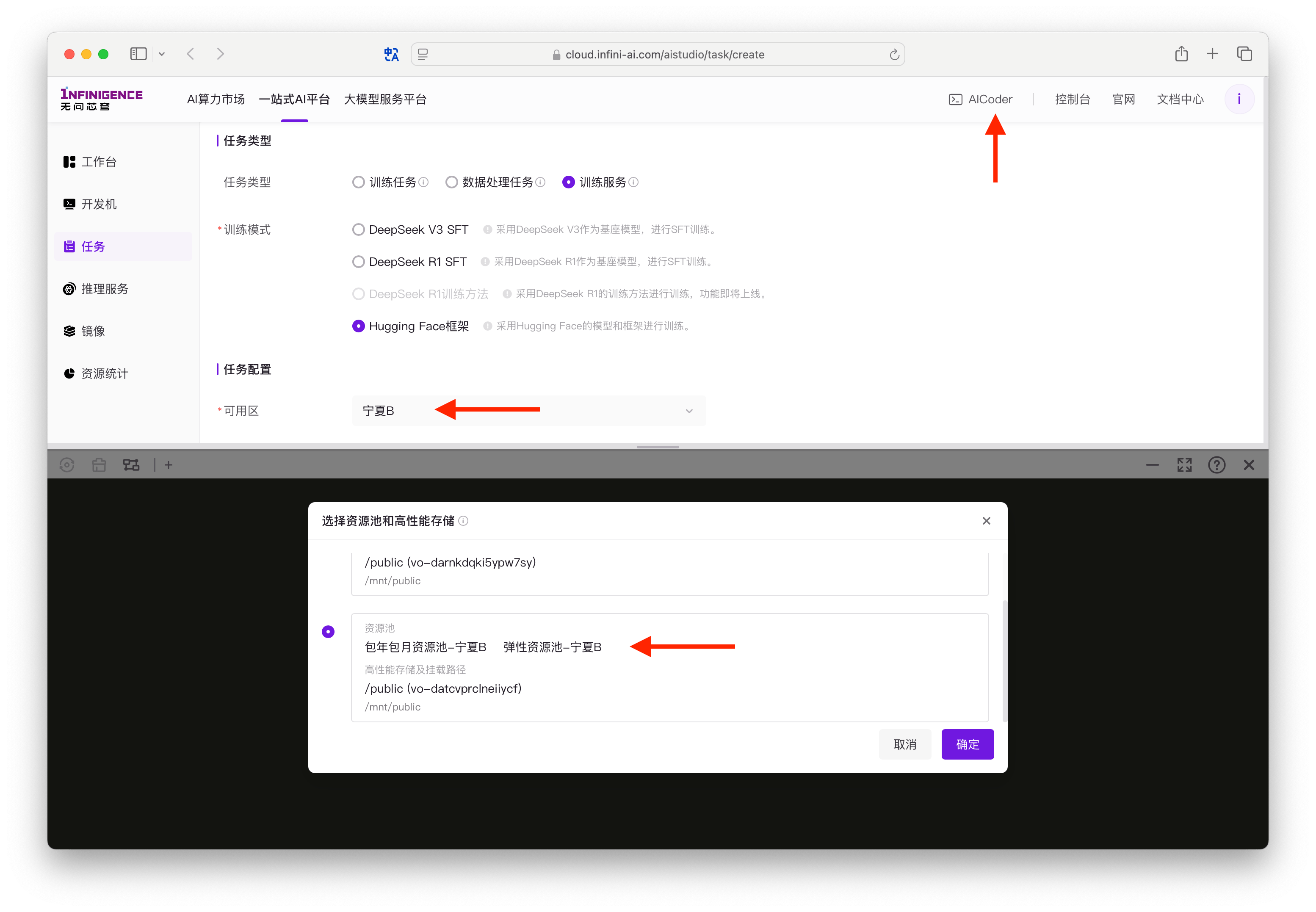
重要
- AICoder 启动时会展示您已有的计算或存储资源对应的可用区。若要挂载已购买的文件存储,AICoder 必须与其在同一可用区。因此在激活 AICoder 时,选择您计划选用的可用区非常重要。例如,您计划使用「宁夏B」可用区的算力,此处必须选择「宁夏B」可用区创建 AICoder。
- 请在 AICoder 弹窗中选择存储卷,并指定该存储卷在 AICoder 中的挂载点(例如
/mnt/public)。
打开 AICoder Shell 后,在窗口右上角点击密钥按钮,以获取 AICoder 实例的数据上传命令。AICoder 支持
scp/sftp/rsync进行数据上传,并支持一键拷贝传输命令(其中已携带连接信息)。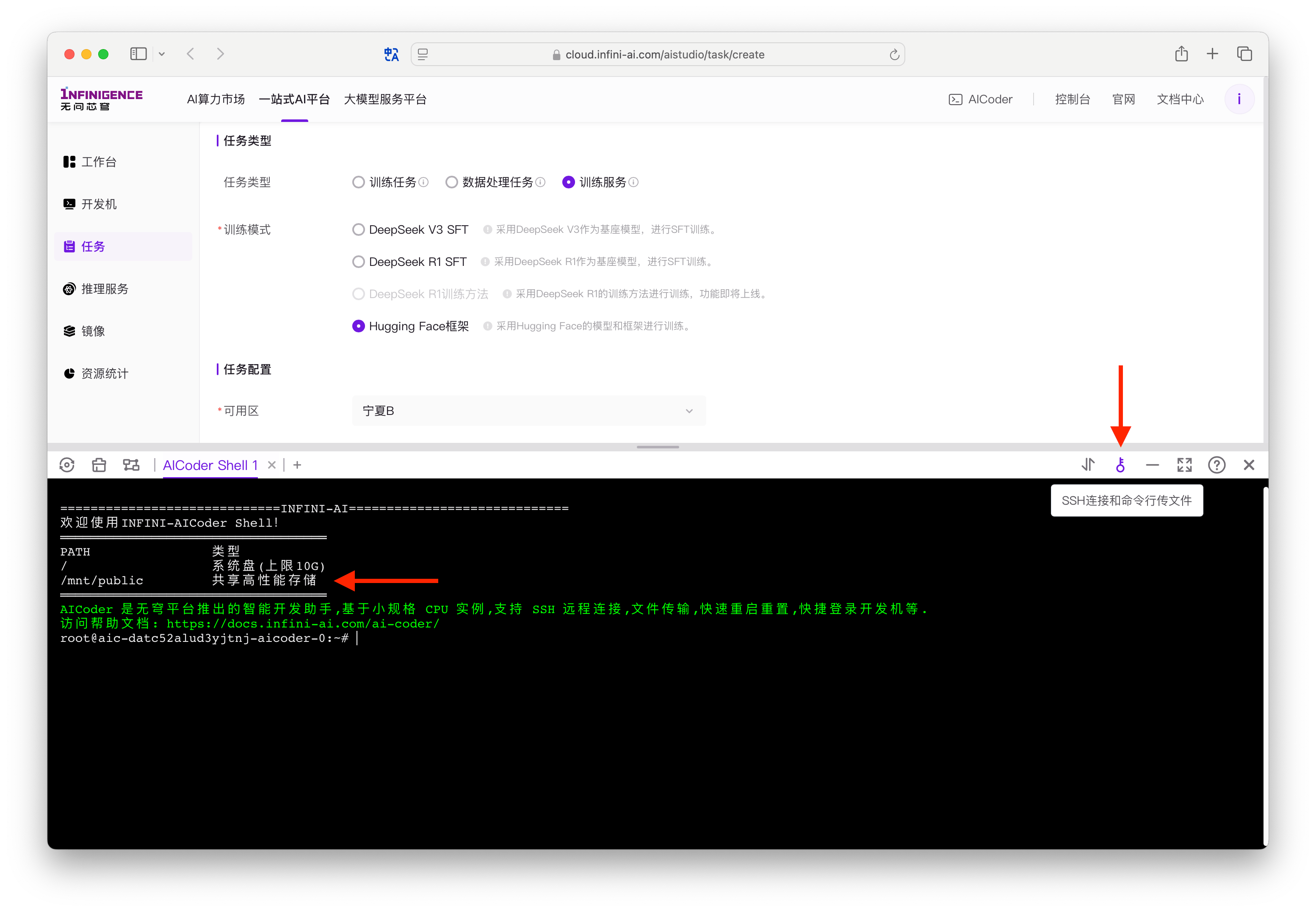
点击后出现弹窗,可在弹窗中复制
scp/sftp/rsync传输命令。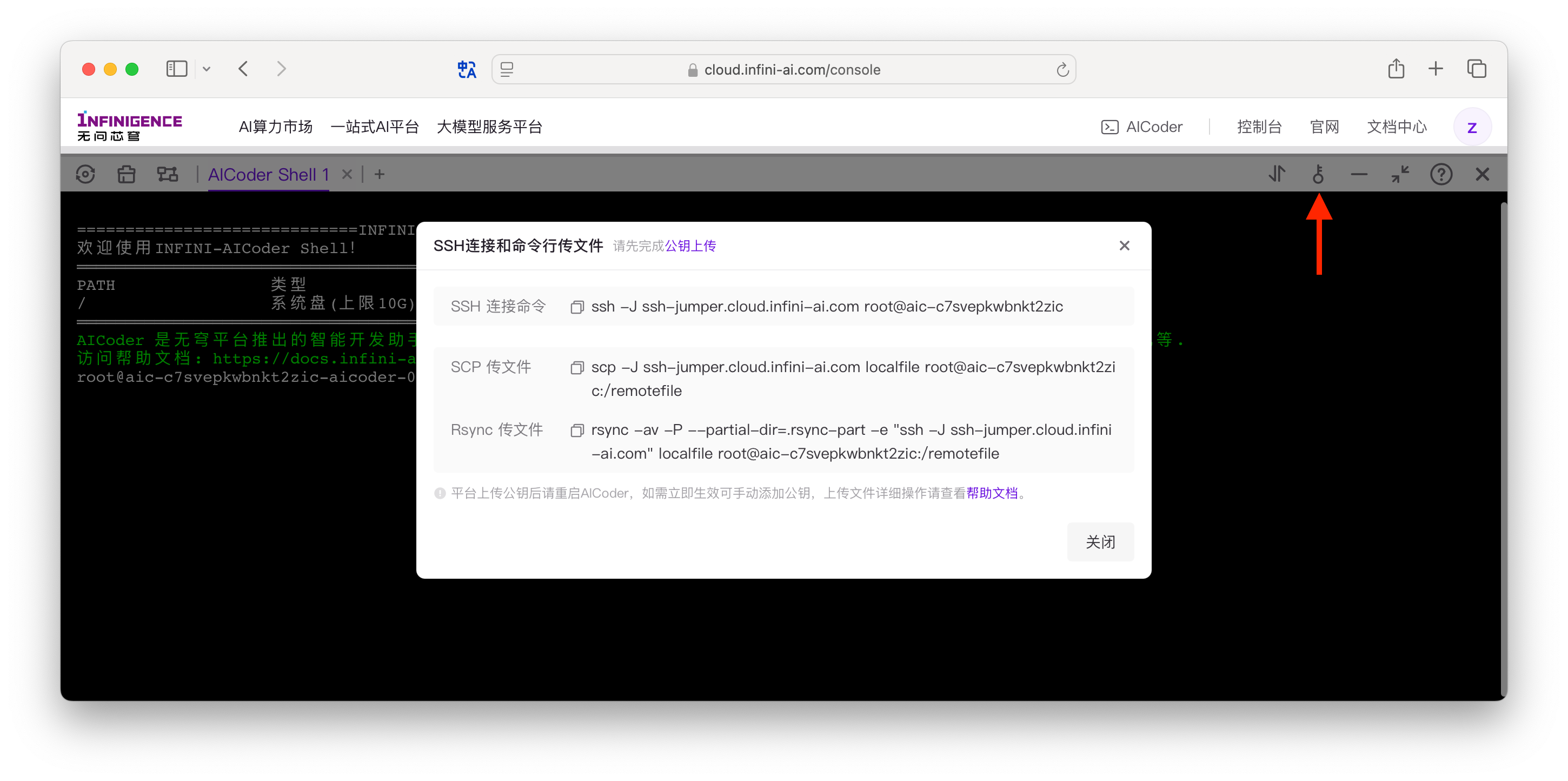
推荐使用 Rsync 进行数据传输。假设将本地存在
/Users/tom/project-hf目录:shell# tree /Users/tom/project-hf/train /Users/tom/project-hf/train ├── finetune_jsonl_dataset └── train.sh └── run_clm_sft.py └── models您需要将该目录上传到 AICoder 所挂载的可用区的共享存储目录(
/mnt/public),示例 Rsync 命令如下:shellrsync -av -P --partial-dir=.rsync-part -e "ssh -J ssh-jumper.cloud.infini-ai.com" /Users/tom/project-hf root@aic-c7svepkwbnkt2zic:/mnt/public/
创建训练服务作业
模型、数据集、脚本准备好后,可以前往智算云平台,创建训练服务作业。
在智算云平台任务列表页面点击 创建任务,进入创建任务界面,选择训练服务。
选择训练模式为 HuggingFace 框架。在任务配置中选择可用区。此处请确保选择模型、数据集、脚本所在的共享存储,填写配置脚本路径。
假设您的训练数据均已通过 AICoder 上传至「宁夏B」的共享存储目录,则此处应选择「宁夏B」。
指定训练脚本路径。例如,在上一步示例中,如果您在
/mnt/public目录下上传了project-hf文件夹,其中包含了train.sh脚本,则脚本路径为/project-hf/train.sh。点击生成训练方案。平台会根据您的数据集、脚本配置开始计算训练方案。方案生成后,请选择合适的预算方案提交作业。
注意
提交训练服务作业后,平台会将任务加入队列,在算力资源可用时运行作业。
查看任务状态
您可以前往任务详情页,在以下标签页检查作业状态:
- 详情:当前作业的基本信息,如训练模式、可用区、脚本路径等。
注意
如您的 Python 训练脚本将日志写入了符合平台要求的目录,可从此处标签页的任务可视化跳转打开 TensorBoard 看板。
- 任务日志:训练服务输出的日志,可按时间筛选。日志保存 30 天。
- 任务兼容:训练服务的资源监控指标。详见资源监控。
模型下载
训练运行成功后可以将模型下载到本地。推荐通过智算云平台免费提供的 AICoder 进行数据下载。由于数据量比较大,建议使用 Rsync。
登录智算云平台,打开 AICoder。选择您创建的训练服务所在的可用区,例如 “宁夏 B”。
获取 Rsync 命令,其中包含了 AICoder 的 SSH 连接信息。
弹窗中仅展示 Rsync 上传命令,需改写为下载命令。假设模型保存在
/mnt/public/project-hf/checkpoints目录,可以通过以下命令下载:shellrsync -av -P --partial-dir=.rsync-part -e "ssh -J ssh-jumper.cloud.infini-ai.com" root@aic-c7svepkwbnkt2zic:/mnt/public/project-hf/checkpoints /User/tom/project-hf/checkpoints
取消作业
在微调作业完成之前,您可以随时取消该作业。我们将对已消耗的算力进行收费。