

快速体验部署推理服务
使用本教程快速体验 AIStudio「推理服务」基本部署流程,并访问已部署的服务。
方案描述
本文描述了一个极简的推理服务部署实验,仅适用于学习 AIStudio 推理服务的基础功能,不适用于正式部署。
- 模型:本方案将部署 Qwen/Qwen3-0.6B,一个 0.6B 参数的小模型,主要理解和生成英文内容。该模型将在服务启动时直接从网络下载,因此您无需提前下载模型。
- 镜像:使用平台预置 vLLM 镜像,您无需自行安装任何软件。
准备算力资源
推理服务要求必须使用预付费计算资源(包年/包月/包周/包日资源池)。暂不支持按量付费方式。
注意
包年包月算力资源是指租户按固定周期(包年/包月)购买算力资源配额的独占使用权,到期前需主动续费。包年包月资源提供多种 GPU 配置。
您可以前往算力市场浏览可选配置,支持自助下单(也可以联系商务下单)。
您可以前往资源池页面查看已购资源。如果租户新购的包年包月算力资源,自动进入默认包年包月资源池。请确认默认资源池或专属资源池中已包含算力资源。
准备镜像
- 如果您使用 RTX 4090:建议您使用我们提供的 Dockerfile,在镜像中心,构建 vllm 0.11.0 自定义镜像。参考构建 vLLM 镜像。构建过程约 15 至 30 分钟。
- 如果您使用 NVIDIA Data Center GPU:您可以跳过构建步骤,使用平台预置 vLLM 0.11.0 镜像。
创建推理服务
访问智算云控制台的推理服务页面,点击 创建推理服务,进入创建界面。
推理类型:保持分布式推理开关为关闭状态(默认)。
资源池:平台会列出租户下的所有包年包月资源池。在资源池下拉列表中可直接查看池中空闲卡数。如果资源池为空,请检查是否已购买算力资源(详见准备算力资源)。如果确认已购买资源,但资源池下拉列表仍然为空,请检查当前用户是否使用任何资源池的权限。
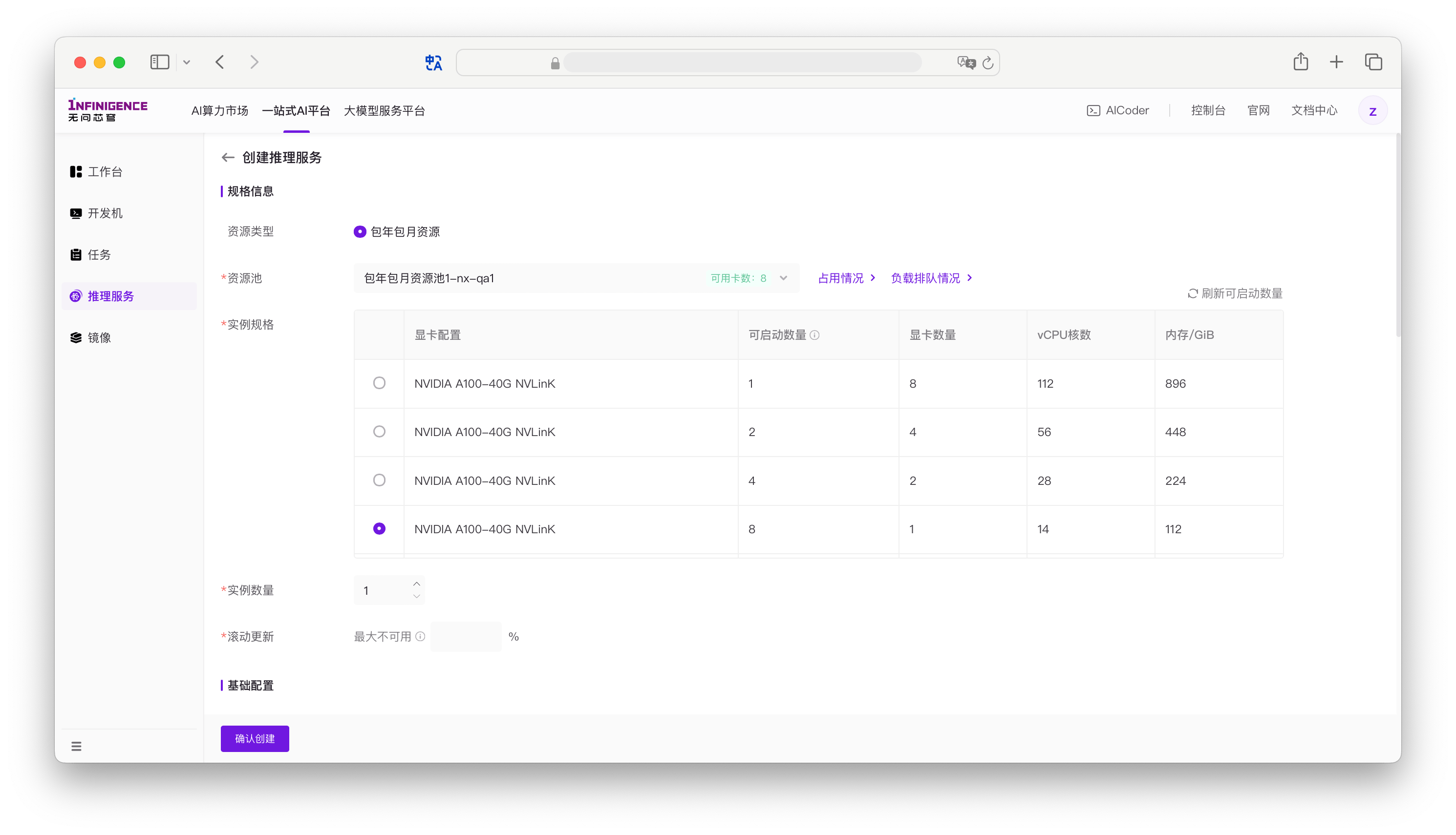
实例规格,选择「显卡数量」为 1 的规格即可,表示每个实例占用 1 卡。
注意
请确保所选规格「可启动数量」不为 0,否则无法启动任何实例。
RDMA 配置: 如果出现该选项,表示当前选中的算力规格支持 IB 或 RoCE 且 GPU 数量为 8 卡。RDMA 配置在规格为 8 卡时自动开启,GPU 数量小于 8 卡时无法开启。对于运行参数量极小的模型,保持该选项关闭即可。
注意
GPU 数量小于 8 卡时禁止使用 RDMA 配置。
实例数量:对于本实验,保持默认值 1 即可。实例数量大于 1 时,平台将自动提供负载均衡,占用的 GPU 总卡数随实例总数增加。
滚动更新:如果只使用单个实例,可设置为 0%。详见升级推理服务。
镜像:选择运行推理服务的容器镜像。
- RTX 4090:请选择自定义镜像,筛选您自行构建的 vLLM 镜像。
- NVIDIA Data Center GPU:请选择预置镜像,筛选 vllm 0.11.0 镜像。
启动命令:填写在容器实例启动时执行的命令。您需要根据预置镜像或自定义镜像内的环境和推理框架编写相应的启动命令,例如设置环境变量、准备模型路径、启动推理服务进程。
shell# --- 1. 设置使用 modelscope 或 Hugging Face 国内镜像站 --- # export HF_ENDPOINT=https://hf-mirror.com export VLLM_USE_MODELSCOPE=true export MODEL=Qwen/Qwen3-0.6B # --- 2. 启动 vLLM 服务,要求 vllm 大于 0.10.0 --- vllm serve ${MODEL} \ --host 0.0.0.0 \ --port 8000 \ --served-model-name Qwen3-0.6B \ --reasoning-parser deepseek_r1注意
如何编写启动命令:
- 启动命令是容器创建后要执行的命令,平台会自动用
/bin/bash -c来执行。 - 保持前台运行:命令必须占据前台,否则容器会立即退出。
- 如果启动命令运行完毕,容器主进程就会退出。例如启动命令
echo hello执行完毕,容器立即退出。 - 错误示例如
vllm serve &将 vLLM 放入后台运行,会导致 bash 立即退出。
- 如果启动命令运行完毕,容器主进程就会退出。例如启动命令
- 若命令行太长或逻辑复杂,可考虑在镜像内(或挂载的共享高性能存储中)放置启动脚本,并在启动命令中调用。
- 推荐阅读优化推理服务启动命令。
- 启动命令是容器创建后要执行的命令,平台会自动用
存储配置:无需配置,可跳过。
- 系统盘: 指推理服务容器的根目录
/的存储大小,固定为 50GiB,通常用于存放操作系统和镜像内容。推理服务容器的系统盘为非持久化存储。 - 公共数据:若所选算力规格位于支持的可用区(如广东B、宁夏B、北京D),可勾选「挂载公共数据」。勾选后,容器内
/infini-data/路径下将以只读方式挂载常用的开源模型和数据集。 - 高性能存储: 可为推理服务容器挂载租户的共享高性能存储卷,可访问共享存储中的数据(如模型文件)。详见共享高性能存储。
警告
本次实验中,由 vLLM 自动在启动过程中下载
Qwen/Qwen3-0.6B模型至推理服务容器系统盘中。这会造成以下问题:- 推理服务进入「运行中」后,需要先下载模型;导致推理服务一段时间内不可用
- 推理服务容器系统盘非持久化存储,每次重启服务均需要重新下载模型
最佳实践:提前将模型下载至共享高性能存储中,在推理服务中挂载存储卷以访问模型。
- 系统盘: 指推理服务容器的根目录
外网配置:启用后,服务将可以通过公网访问。选择默认地址。Auth 配置 保持为 Authorization。详见访问推理服务。
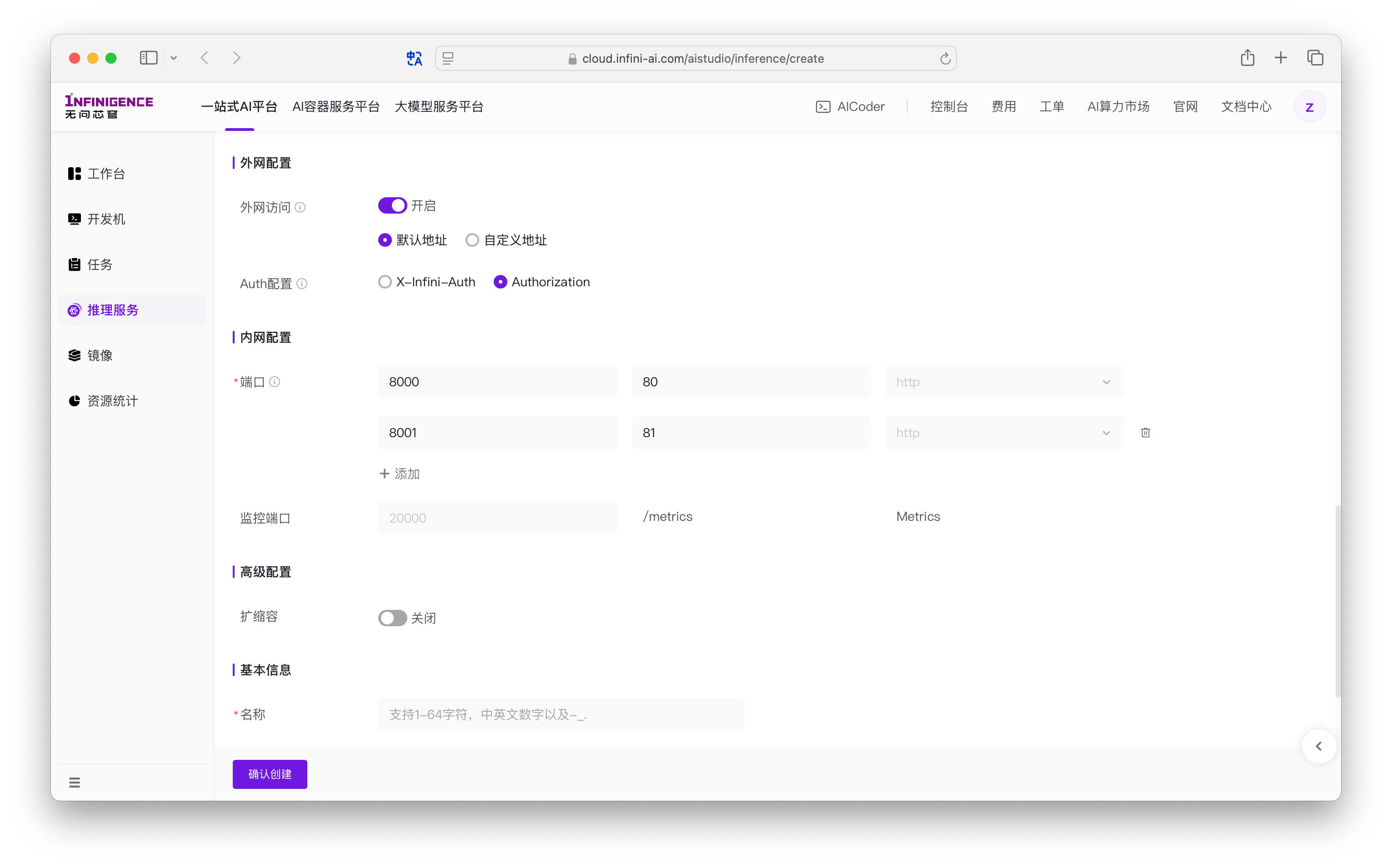
内网配置(端口):保持监听端口为默认值
8000,调用端口为默认值80。监控端口配置为8000。详见服务监控。注意
平台通过您设置的监听端口将外部流量转发到容器内部。因此,该监听端口必须容器内服务的监听端口一致(常通过
--port/server_port/--http-port之类参数指定),否则平台无法正确访问您的服务。高级配置区域可跳过。扩缩容默认关闭,详见扩缩容。
为您的推理服务命名并添加描述。
- 名称:推理服务的名称,1~64 个字符,支持中英文、数字、下划线 (
_) 和连字符 (-)。名称在租户内不必唯一。 - 描述与标签:在本实验中可留空。
- 名称:推理服务的名称,1~64 个字符,支持中英文、数字、下划线 (
完成所有配置后,点击确认创建。服务将进入创建流程。
注意
推理服务进入「运行中」状态后,vLLM 将先下载模型,随后加载模型,再启动模型推理。您可以等待 5 分钟左右;或进入推理服务详情页,切换到「日志」标签页的输出,观察是否报错,若出现 Application startup complete,表示推理服务 API 已经可以调用。
验证推理 API
推理服务创建完成后,可以通过内网或外网调用 API 来验证服务是否正常运行。
内网调用 API
从平台上同一个可用区内访问该推理服务时,仅通过内网调用 API,这种方式无需通过 API Key 验证。
打开推理服务详情页,记录以下数据:
- 可用区:表示推理服务算力资源所在可用区
- 内网访问地址:表示在同可用区内,访问当前推理服务所使用的 URL 地址,例如
http://if-db3o6xyqoxfcolln-service:80
点击顶部 AICoder 按钮,选择与推理服务相同的可用区。
注意
也可以使用同一个可用区的开发机。
替换以下命令中的推理服务内网访问地址为真实 URL 后,在 AICoder Shell 中运行命令。注意推理服务访问路径后必须拼接 vLLM OpenAI 兼容的 API 服务器路径
/v1/chat/completions(命令中已拼接)。shellexport INTRANET_SERVICE_URL="推理服务内网访问地址" curl -s --request POST \ --url "$INTRANET_SERVICE_URL/v1/chat/completions" \ --header "Content-Type: application/json" \ --data '{ "model": "Qwen3-0.6B", "messages": [ {"role": "user", "content":"Give me a short introduction to large language model"} ] }' | python3 -m json.tool
公网调用 API
如果从公网访问推理服务(例如,跨可用区访问,或从您的本地设备调用 API),则需要获取公网访问地址,且必须通过 API Key 验证。
前往密钥管理页面,申请 API 密钥。
打开推理服务详情页,记录以下数据:
- 外网访问地址:表示从公网访问当前推理服务所使用的 URL 地址,例如
https://cloud.infini-ai.com/AIStudio/inference/api/if-db3o6xyqoxfcolln/
- 外网访问地址:表示从公网访问当前推理服务所使用的 URL 地址,例如
替换以下命令中的推理服务外网访问地址 / API 密钥为真实值后,运行命令。注意推理服务访问路径后必须拼接 vLLM OpenAI 兼容的 API 服务器路径
/v1/chat/completions(命令中已拼接)。shellexport INTERNET_SERVICE_URL="推理服务外网访问地址" export API_KEY="API 密钥" curl --request POST \ --url "$INTRANET_SERVICE_URL/v1/chat/completions" \ --header "Authorization: Bearer $API_KEY" \ --header "Content-Type: application/json" \ --data '{ "model": "Qwen3-0.6B", "messages": [ {"role": "user", "content":"Give me a short introduction to large language model"} ] }'在您的本地设备中,打开命令行界面(MacOS 的终端,或 Windows CMD)。
注意
也可以使用 AICoder 或开发机。