

训练故障处理
本文介绍了智算云平台任务功能故障排查思路及解决方案。
检查启动命令
任务启动命令应该保证做到让容器退出码可信、训练任务可观测、失败可排障、脚本行为确定且平台调度器可以正确感知异常。
重要
推荐阅读优化训练任务启动命令。
查看容错日志
「任务容错」与「训练变慢检测」的输出均展示在任务详情页的容错日志标签页。容错日志一般可用于排查硬件问题。
启动自检与异常定位
开启容错后,平台会在训练任务启动时执行启动检测(Bootcheck),训练失败时会执行异常定位(Troubleshoot),均会检查关键的软件和硬件环境(GPU/RDMA/IO/通信)。
在任务详情页的容错日志中,平台会记录当前任务的最大重启次数、已重启次数、因硬件问题导致的重调度次数。如果发现掉卡错误,会重新调度健康节点,并尝试重启训练。
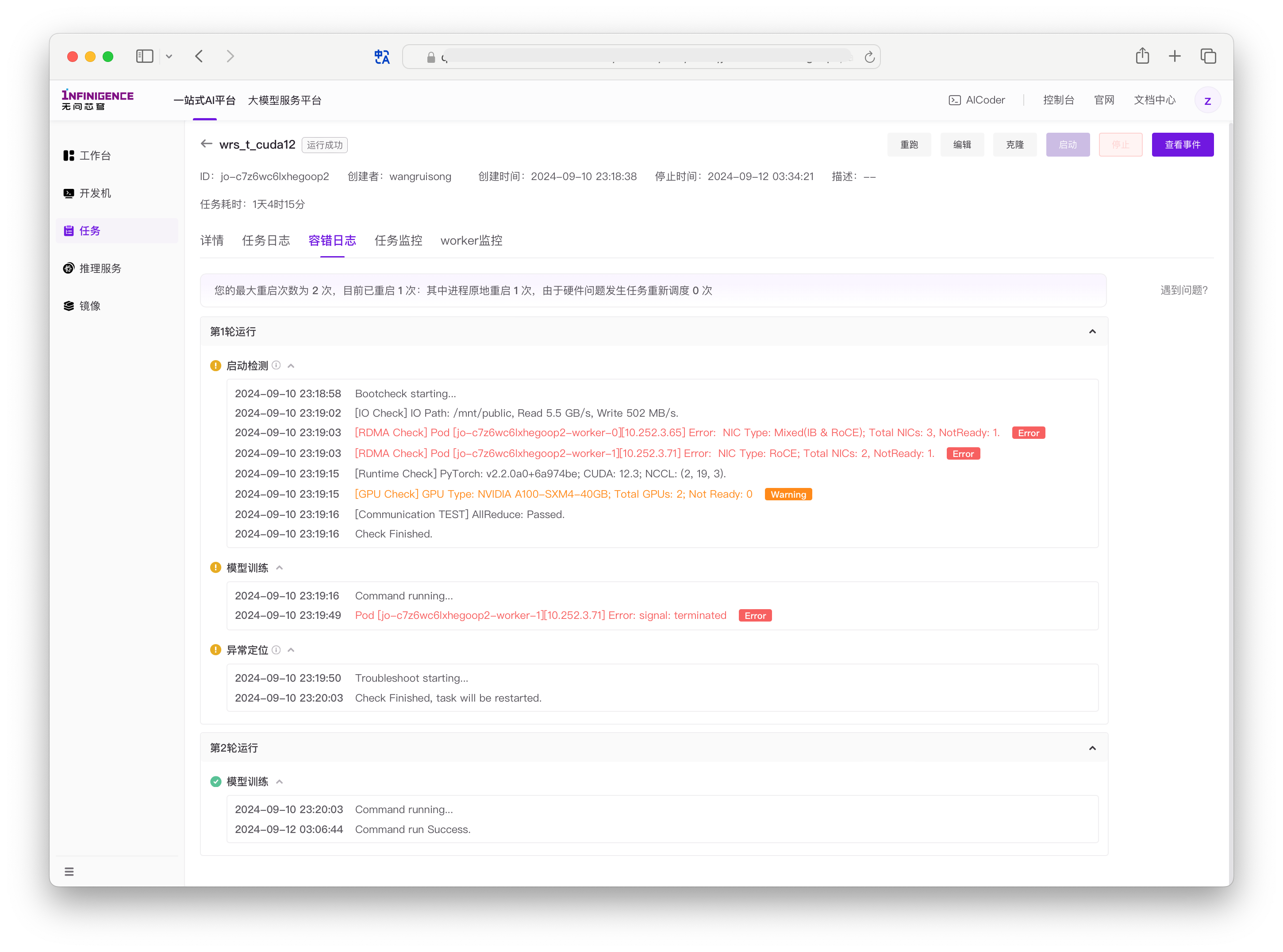
如果启动检测和异常定位都通过,那么很可能是训练代码出现了问题。
如果持续出现硬件问题,请联系商务或售后服务。
警告
- 硬件错误(如掉卡)将阻断任务继续执行,平台将自动帮您进行重调度至健康节点,再重启训练。如集群中无冗余健康节点,容错功能将无法为您恢复训练。
- 其他异常问题(如慢节点)不会阻断任务继续执行,平台将继续执行用户代码。
训练变慢检测
任务开启训练变慢检测后,平台可自动分析训练日志,发现训练变慢后在容错日志中输出告警。仅支持 Megatron-LM 和 LLaMA-Factory 框架变慢检测,若其他框架当前则不会进行检测。
如果您在任务详情页的容错日志发现以下 Warning 日志,说明平台已检测到训练变慢:
2025-04-21 15:19:58 Command running...
2025-04-21 15:25:56 Smoothed mean (iters 83-87: 9465.00 ms, baseline: 3101.00 ms), threshold ratio:2.05. Warning
2025-04-21 15:27:26 Smoothed mean (iters 88-92: 16704.00 ms, baseline: 3101.00 ms), threshold ratio:4.39. Warning这个日志片段关键数字及其含义如下:
- 9465.00 ms 和 16704.00 ms
- 这是系统计算的“平滑平均耗时”,分别对应两次时间段的迭代(83-87次和88-92次)。
- 表示这些迭代中训练步骤(step)的平均执行时间(毫秒),数值越高说明训练速度越慢。
- 3101.00 ms
- 这是本次训练任务中训练速度最快时平滑处理过的耗时(baseline)。
- 作为性能基准,用于对比当前训练速度是否下降。
- 2.05 和 4.39
- 这是“阈值比率”(threshold ratio),即当前平滑平均耗时与最快耗时的比值。
- 2.05,4.39:当前平均耗时是最快耗时的2.05/4.39倍,达到警告阈值(目前设定为0.8)。
注意
当训练速度异常缓慢或 GPU 利用率低时,可使用 atlctl burn 烧机测试验证硬件性能是否正常。
查看任务日志
在任务运行过程中的所有日志(任务所有 Worker 的日志),均会展示在任务详情页的任务日志标签页,包括训练代码输出,也包括「任务容错」与「训练变慢检测」的输出。
日志筛选
在查看任务日志时,可组合筛选条件:
- Worker:选择单个、全部 Worker
- 时间: 根据时间筛选日志(精确到秒)。
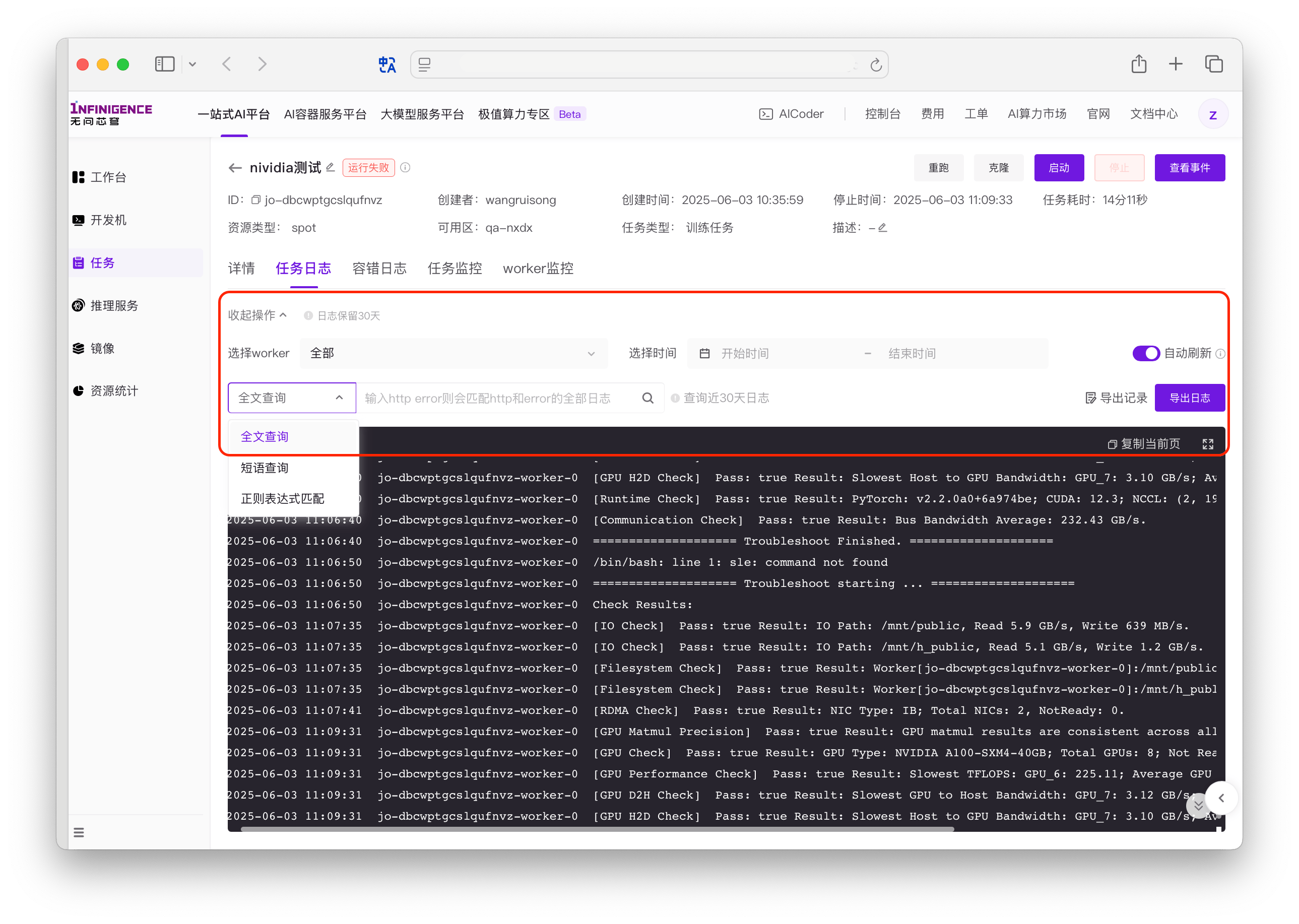
日志搜索
支持全文查询、短语查询、正则表达式搜索日志。支持以下查询方式:
- 全文查询:输入关键字进行整条日志搜索。如果一条日志中出现所有关键词,则为一次匹配。支持模糊匹配。
- 短语查询:用户指定必须在日志中完整出现的「短语」。如果一条日志中完整「短语」,则为一次匹配。例如用户输入
http error,如果一条日志中出现http error,则为一次匹配。大小写不敏感。 - 正则表达式匹配:如果一条日志符合表达式要求,则为一次匹配。例如,输入
[0-9]+查询连续数字。正则表达式语法与 OpenObserve 一致,参考 re_match。
注意
每条日志的前缀(时间,实例名称、Worker 名称)不在日志搜索范围中。您可以通过组合筛选条件获取最准确的结果。支持先筛后搜或先搜后筛。
日志分析步骤
如果训练代码存在问题,导致任务失败,您可以参考以下步骤分析任务日志和 Worker 日志。
- 当发生错误时,查看所有的错误日志记录,找到第一个异常日志记录及其对应的 Pod 信息。
- 根据第一条错误日志的记录信息,查找相应的代码位置,分析可能的原因,例如通信超时退出、计算错误退出、硬件错误退出、Pod 或进程失去连接退出等。
日志下载
在任务详情页「任务日志」页面可选择导出日志。
注意
日志下载功能需申请开通。
- 若您未对日志做任何筛选(时间筛选,实例筛选和搜索),则默认导出过去 30 天日志。
- 若当前已经进行筛选、搜索,则下载筛选、搜索后的日志。
导出日志量大时比较耗时,请耐心等待。平台将为您保存最近 5 条导出记录。
原地调试
AIStudio 任务功能支持原地调试,您可以登录任务 Worker 直接控制任务状态,排查问题。
保留现场
任务失败后平台将清理 Pod,导致无法进入训练环境。为了保留现场,在启动命令最后添加 sleep 10000,使任务失败后仍将 Pod 保留一段时间,方便排查。
详见优化训练任务的启动命令。
登录任务的 worker
在任务详情页可查看任务 worker 的状态,可点击刷新获取当前最新状态。必要时可以登录 worker 进行错误排查。
Worker 的登录入口在任务详情页 Worker 信息中。点击登录按钮后可从网页端打开命令行界面。
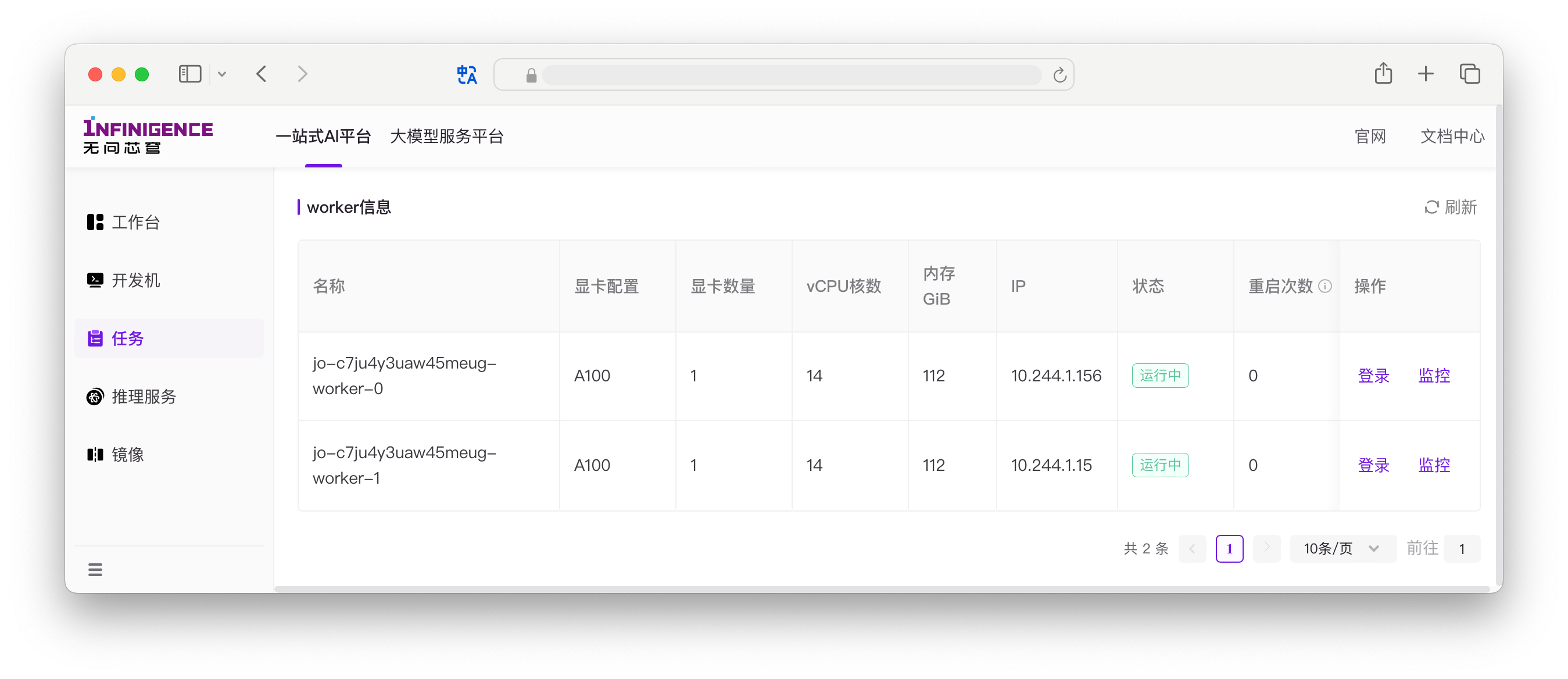
您也可以自行运行基准测试以检查 Pod 和硬件是否存在问题。如果这些测试都通过,那么很可能是代码出现了问题。
- 计算基准测试,如 gpu-burn
- 通信基准测试,如 nccl-test
- 训练基准测试等
注意
- 仅在任务运行中时可登录 Worker,仅支持从网页端登录 Worker,暂不支持 SSH 远程登录任务的 Worker。
原地调试工具 atlctl
AIStudio 在任务 Worker 的 Web Terminal 中内置了 atlctl 调试工具,可对所有 Worker 下发调试命令。
解决环境问题
建议您提前使用开发机等方式进行验证,或提前进行试运行(特别是从外部迁移至平台的自定义镜像),确保您的训练环境可正常工作。以下针对常见的环境问题总结了解决方案。
系统级 CUDA/cuDNN
镜像中可能缺失系统级 CUDA 和 cuDNN 的问题,无法使用 nvcc。例如 DeepSpeed 明确依赖 nvcc。
RDMA 网络
如果在多机训练时发现无法使用 RDMA 网络,或达不到正常速度,请检查以下项目:
前往任务详情页,检查「规格信息」,查看当前所使用的规格的「训练网配置」是否为 RoCE / IB 训练网。如果不是,需要更换为其他支持 IB 或 RoCE 的规格。
前往任务详情页,检查「规格信息」,查看当前所使用的规格的「RDMA 配置」是否「开启」状态。如果不是,可选择重跑任务,并选择改配重跑,启用「RDMA 配置」。
如果问题仍然持续,请验证镜像是否支持 RDMA。可在任务运行中前往详情页,在底部找到 Worker 信息,登录 Worker 后执行以下命令,检查镜像中是否已安装 RDMA 所有依赖项(也可以用该任务镜像新建开发机后执行检查)。如有缺失,可参考 RDMA 网络。
shell# Ubuntu 22.04 dpkg -l infiniband-diags perftest ibverbs-providers libibumad3 libibverbs1 libnl-3-200 libnl-route-3-200 librdmacm1
Conda
在训练服务中使用镜像中的 Conda,可能会遇到 conda activate 命令报错,导致无法激活 Conda 虚拟环境。
警告
在训练场景下,为了缩小镜像体积、降低复杂性,最佳实践是不要使用 Conda 虚拟环境,而是制作一个最小化专用镜像。
修改镜像
如果您接受修改镜像,可以直接在镜像中心以预置镜像/自定义镜像的基础,执行以下命令,构建新版镜像。使用新版镜像运行训练任务即可。
conda init --system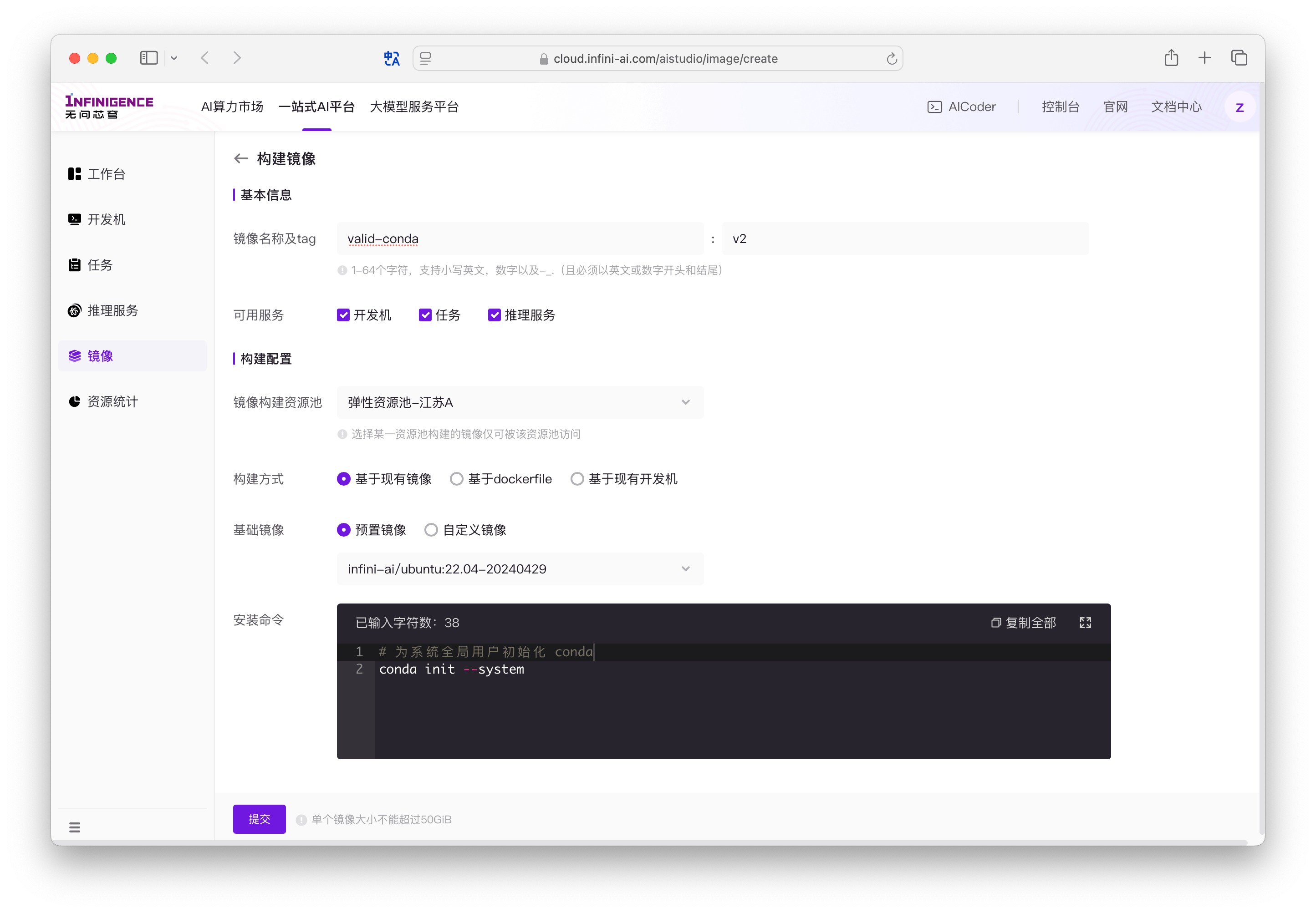
不修改镜像
如果您直接在任务的启动命令中执行 conda activate,解决方案有以下两种(请自行确认镜像中 conda 的实际安装路径):
通过 conda hook 初始化,先确保 conda 命令可用,然后初始化 conda 的 shell 函数和环境变量
shell# 请自行确认镜像中 conda 的实际安装路径 export PATH="/usr/local/miniconda3/bin:$PATH" eval "$(conda shell.bash hook)" # 在 activate 前执行上述命令 conda activate your-env更简洁的方式,直接使用 conda 预置的初始化脚本
conda.shshell# 请自行确认镜像中 conda 的实际安装路径 source /usr/local/miniconda3/etc/profile.d/conda.sh # 在 activate 前执行上述命令 conda activate your-env
如果在任务启动命令中执行了外部 Shell 脚本,脚本内部执行 conda activate,解决方案有以下两种(请自行确认镜像中 conda 的安装路径):
修改引用的外部 Shell 脚本,在脚本中先
sourceconda 预置的初始化脚本conda.shshell# 请自行确认镜像中 conda 的实际安装路径 source /usr/local/miniconda3/etc/profile.d/conda.sh # 在 activate 前执行上述命令 conda activate your-env如果镜像的
.bashrc中已存在有效的 conda 配置,可以不修改脚本内容,仅修改脚本的执行方式为使用 interactive shell 执行(bash -i):shell# -i 方式会在子 Shell 中加载当前 Shell 的 .bashrc bash -i myscript.sh
注意
- 平台在执行任务启动命令时,会加上
--login参数。Login shell 会依次读取/etc/profile~/.bash_profile,~/.bash_login,~/.profile,默认不读取~/.bashrc。 - 修改/制作自定义镜像时,可以考虑使用
conda init --system,将 conda 相关配置写入系统全局配置,如/etc/profile.d/conda.sh(conda init默认写入用户设置,如~/.bashrc)。
调试 NCCL
在调试和排障时,使用以下 NCCL 环境变量有助于排查问题。
设置 NCCL 在运行时打印丰富的日志信息,帮助调试和分析 NCCL 相关的性能问题和错误。
# 调试时打印日志使用
export NCCL_DEBUG=INFO注意
打印大量调试信息可能会影响 NCCL 的性能,因此建议只在调试需要时启用此设置。
暂时绕过自动选择接口的机制,指定 NCCL 通信使用的网络接口。
# 设置socket建环使用eth0的通道
export NCCL_SOCKET_IFNAME=eth0如果您的镜像是用的 NGC 镜像,或者加载了 NCCL 的 sharp 等插件的话,有可能会出错。可临时添加如下环境变量,帮助诊断问题或验证网络配置。
# 指示 NCCL 不使用任何网络通信插件
export NCCL_NET_PLUGIN=none 注意
部分自定义镜像(比如从外部平台迁移的镜像)可能会携带预设环境变量,导致训练问题,请注意提前检查。
其他使用建议
为了增强 AIStudio 任务功能使用体验,我们建议您使用以下功能。
任务状态通知
AIStudio 任务功能已支持配置通知。
- 飞书机器人告警:为了及时获取任务异常、或运行失败等情况,建议您配置飞书机器人告警通知。