

配置训练任务的容错功能
AIStudio 训练服务提供平台级别的容错能力,通过模块化的子功能帮助您保护训练作业免受硬件故障和异常情况的影响。容错功能包括环境检测、自动重启和 Hang 检测三个可独立配置的子功能,可自动诊断硬件问题、恢复训练任务,避免训练中断和状态丢失。
前提条件
使用容错功能需要满足以下要求:
- 训练脚本支持检查点恢复:您的训练脚本必须实现检查点的定期保存和加载机制。容错功能可以自动重启任务,但无法恢复内存中的训练状态,必须通过检查点来恢复训练进度。详见下文准备训练脚本。
- 了解工作负载特征:根据训练任务的时长、重要性、硬件需求等特点,选择合适的容错配置。
- 访问任务创建界面:确保您有创建训练任务的权限。
了解容错子功能
容错功能包含三个可独立配置的子功能,可根据训练任务特点灵活组合使用:
- 环境检测:在关键时刻检查硬件和软件环境健康状况,支持任务运行前、任务失败、任务 Hang 三个检测时机。
- 自动重启:任务失败或挂起时自动重启,可配置最大重启次数(1-10 次)和触发条件。
- Hang 检测:监控任务进度识别挂起状态,是其他功能使用任务 Hang 作为触发条件的前提。
容错
├── 环境检测(可独立使用)
│ └── 检测时机:任务运行前 / 任务失败 / 任务 Hang*
├── 自动重启(可独立使用)
│ └── 触发条件:任务失败 / 任务 Hang*
└── Hang 检测(可独立使用)
└── 为其他功能提供"任务 Hang"状态
* 标注项需要 Hang 检测功能开启配置完成并创建任务后,随时可在任务详情页查看已配置的容错功能和参数。例如:
环境检测:关闭
自动重启:
- 触发条件:任务 Hang
- 最大重启次数:5
Hang 检测:任务 Hang 超过 5 分钟后,提示 Hang 检测不通过
环境检测
环境检测在指定时机自动检查关键的软件和硬件环境,帮助您及早发现问题或诊断故障原因。
容错环境检测默认检查以下项目:
- GPU 健康状况(计算性能、显存传输、进程残留)
- RDMA 网络连通性
- 存储 I/O 性能
- 通信连通性(allreduce)
- 运行时环境(PyTorch、CUDA、NCCL 版本)
检测时间取决于选择的检测项,完整检测通常需要 2-4 分钟。您可以通过环境变量自定义检测项,详见下文自定义检测项。
信息
- 使用建议:生产环境长期训练建议开启以诊断硬件问题;开发调试或短期任务可通过自定义检测项关闭或最小化检测项以加快启动。
- 重要提示:如果您的训练环境使用 Conda、venv 等虚拟环境,且 PyTorch 安装在虚拟环境中,必须配置
ATLAS_ACTIVATE_ENV环境变量以确保环境检测能够正确访问 PyTorch 和 CUDA 库。详见下文配置虚拟环境。
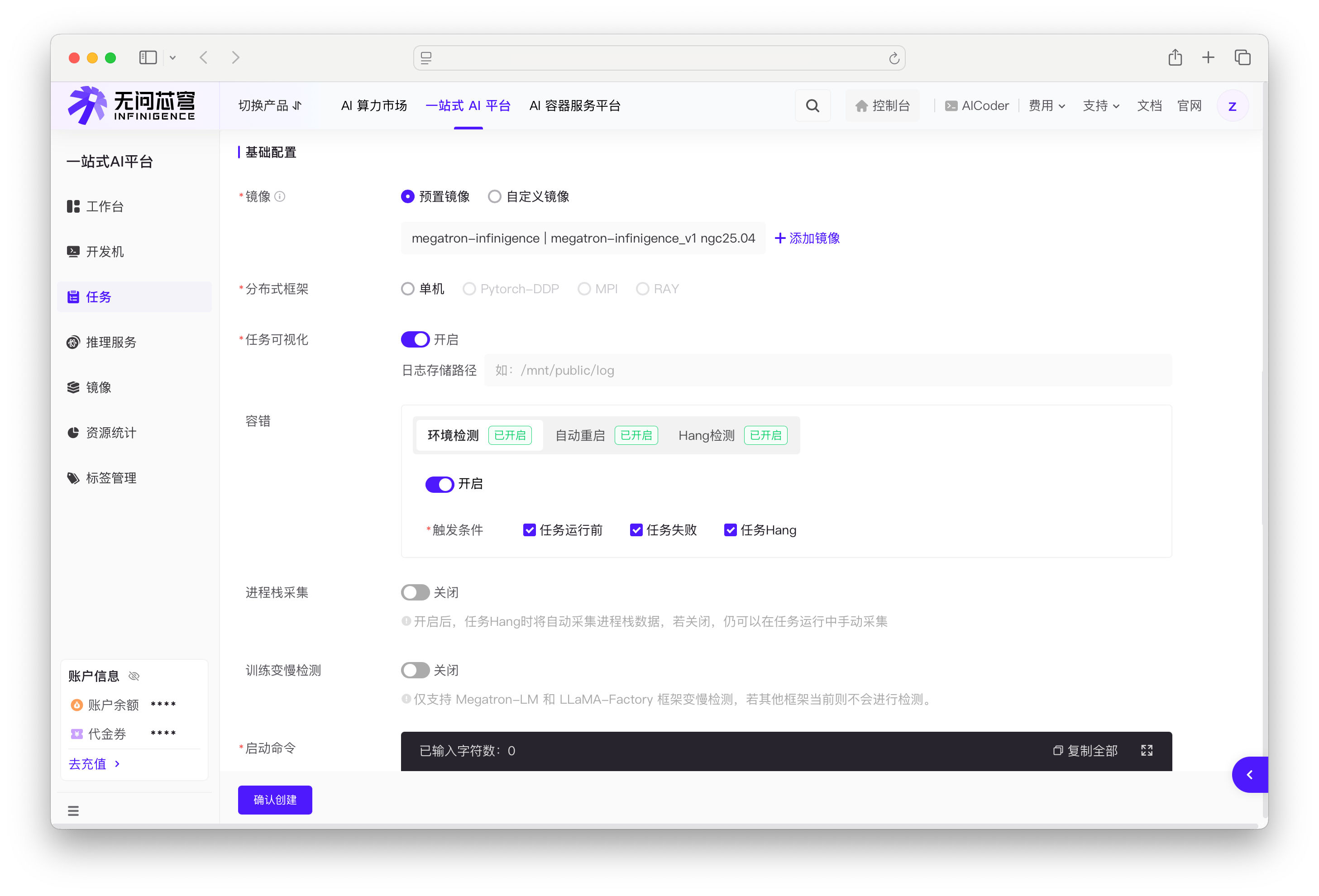
启用环境检测
在创建任务时的容错配置区域,将环境检测开关切换为开启状态,并选择检测时机(可多选)。
- 任务运行前:在任务启动时进行开机检测,及早发现硬件问题
- 任务失败:在任务失败后进行故障检测,帮助诊断故障原因
- 任务 Hang:在任务挂起时进行检测(需要先开启 Hang 检测)
检测结果处理
环境检测的结果有两个输出渠道:
容错日志输出:所有检测结果(无论是否发现问题)都会记录在任务详情页的容错日志标签中。详见下文查看环境检测日志。
触发自动重启:环境检测可以作为自动重启的触发输入(仅在发现 GPU 掉卡错误时可触发重启)。要启用这一联动:
- 开启自动重启功能。
- 在自动重启的触发条件中勾选环境失败。
配置完成后,一旦环境检测发现 GPU 掉卡后,会阻断任务并触发自动重启,将任务重新调度到健康节点。
结果处理总结:
| 检测结果 | 日志输出 | 触发自动重启 | 任务行为 |
|---|---|---|---|
| GPU 掉卡 | ✓ 记录 | ✓ 可触发(需配置) | 阻断任务,重启到健康节点 |
| 其他问题(RDMA、IO、通信等) | ✓ 记录 | ✗ 不触发 | 任务继续执行 |
| 未发现问题 | ✓ 记录 | ✗ 不触发 | 任务继续执行 |
自定义检测项
环境检测默认执行所有检查项。当环境检测功能开启时,您可以通过 ATLAS_BOOTCHECK_ITEMS 环境变量自定义检测项,以优化任务启动时间或满足特定检测需求。
在创建任务时的环境变量区域进行配置。以下为配置示例。
# 快速启动 - 仅检查 GPU 进程残留
ATLAS_BOOTCHECK_ITEMS=gpu_process
# 平衡配置 - 检查关键项目
ATLAS_BOOTCHECK_ITEMS=gpu,allreduce,rdma
# 完整检测 - 所有项目(默认)
ATLAS_BOOTCHECK_ITEMS=all
# 跳过检测(等效于关闭环境检测开关)
ATLAS_BOOTCHECK_ITEMS=none提示
ATLAS_BOOTCHECK_ITEMS仅在环境检测功能开启时生效。平台通过ATLAS_CHECK_ENABLE环境变量控制检测是否启用。ATLAS_BOOTCHECK_ITEMS环境变量同时影响环境检测功能和atlctl命令行工具。ATLAS_BOOTCHECK_ITEMS环境变量必须在创建任务时通过网页的环境变量配置区域设置,在启动命令或训练脚本中设置无效。- 本节提供常用配置示例,完整的检测项列表、时间开销和技术细节请参阅 ATLAS_BOOTCHECK_ITEMS。
配置虚拟环境
如果环境检测需要访问特定的 Python 虚拟环境(例如虚拟环境中安装了 PyTorch),可以通过 ATLAS_ACTIVATE_ENV 环境变量激活虚拟环境。
在创建任务时的环境变量区域进行配置。以下为配置示例。
# Conda 虚拟环境
ATLAS_ACTIVATE_ENV=source /usr/local/miniconda3/etc/profile.d/conda.sh;conda activate myenv
# Python venv
ATLAS_ACTIVATE_ENV=source /root/project-a/.venv/bin/activate
# 使用 . 命令(等同于 source)
ATLAS_ACTIVATE_ENV=. .venv/bin/activate提示
ATLAS_ACTIVATE_ENV环境变量必须在创建任务时通过网页的环境变量配置区域设置,在启动命令或训练脚本中设置无效。ATLAS_ACTIVATE_ENV环境变量同时影响环境检测功能和atlctl命令行工具。本节提供常用配置示例,完整的作用范围说明、使用场景和技术细节请参阅 ATLAS_ACTIVATE_ENV。
自动重启
自动重启功能在满足特定触发条件时自动重启任务,减少人工干预,加快故障恢复。
触发条件说明
自动重启支持两种触发条件(任务失败有两种触发来源),可在配置界面中多选。
| 触发条件 | 触发来源 | 前置要求 | 说明 |
|---|---|---|---|
| 任务失败 | 任务执行器 | 无 | 任务进程退出且返回非零状态码 |
| 任务失败 | 环境检测子功能 | 需开启环境检测 | 环境检测发现 GPU 掉卡 |
| 任务 Hang | Hang 检测子功能 | 需开启 Hang 检测 | 任务被判定为挂起状态 |
与环境检测的协同
自动重启功能可以独立于环境检测使用。如果同时开启环境检测,则重启前后会自动执行环境检查。
信息
无人值守的长期训练且有完善检查点机制时建议开启;开发调试阶段或反复失败的任务建议关闭以保留故障现场进行分析。最大重启次数建议根据检查点保存频率设置(频繁保存可设置 5-10 次,稀疏保存建议 1-3 次)。
配置自动重启
在创建任务时的容错配置区域,将自动重启开关切换为开启状态,并进行如下配置。
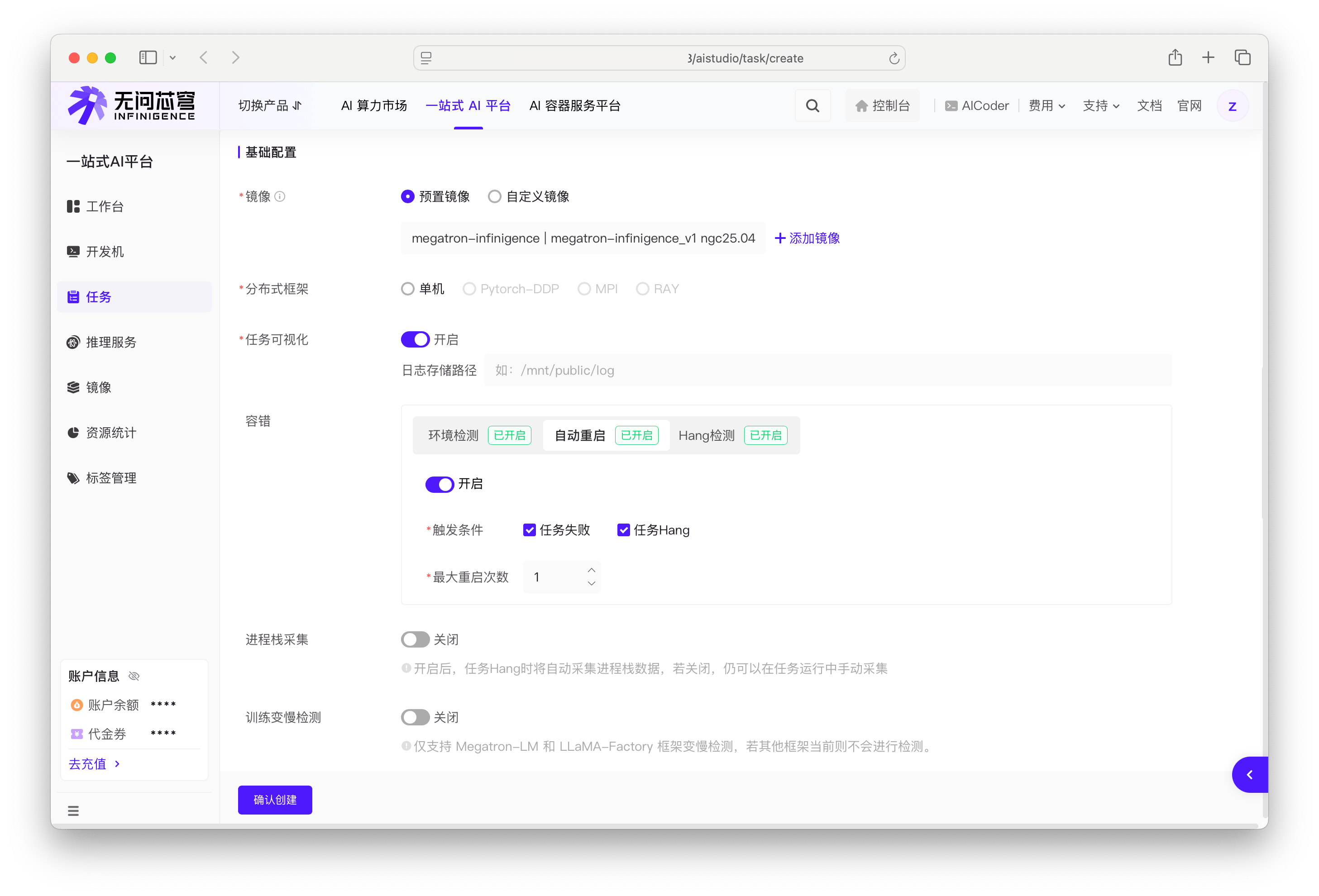
选择触发条件
任务失败:
- 任务进程异常退出时触发(容器主进程返回码不为 0)。为避免误报,请确保您的任务启动命令遵循最佳时间,以正确返回训练进程的返回码。详见优化训练任务的启动命令。
- 平台可在检测到硬件问题时重新调度到不同节点(硬件故障检测依赖开启环境检测)
任务 Hang:任务挂起时触发(需先开启 Hang 检测)
配置最大重启次数
- 最大重启次数:可配置为 1-10 次,默认为 1 次
- 超过最大重启次数后,任务将标记为失败并结束。训练状态必须通过检查点机制恢复,平台不会自动恢复内存中的训练状态。
Hang 检测
Hang 检测功能监控任务的执行进度(GPU 计算活动),识别任务是否处于挂起(无响应)状态。
- 当一段时间内未检测到 GPU 计算活动时,判定任务挂起
- 触发挂起状态后,可自动收集进程栈信息供诊断使用
- 挂起状态可以触发环境检测或自动重启。Hang 检测是其他功能使用任务 Hang 触发条件的前提。如果需要在任务挂起时执行环境检测或自动重启,必须先开启 Hang 检测。
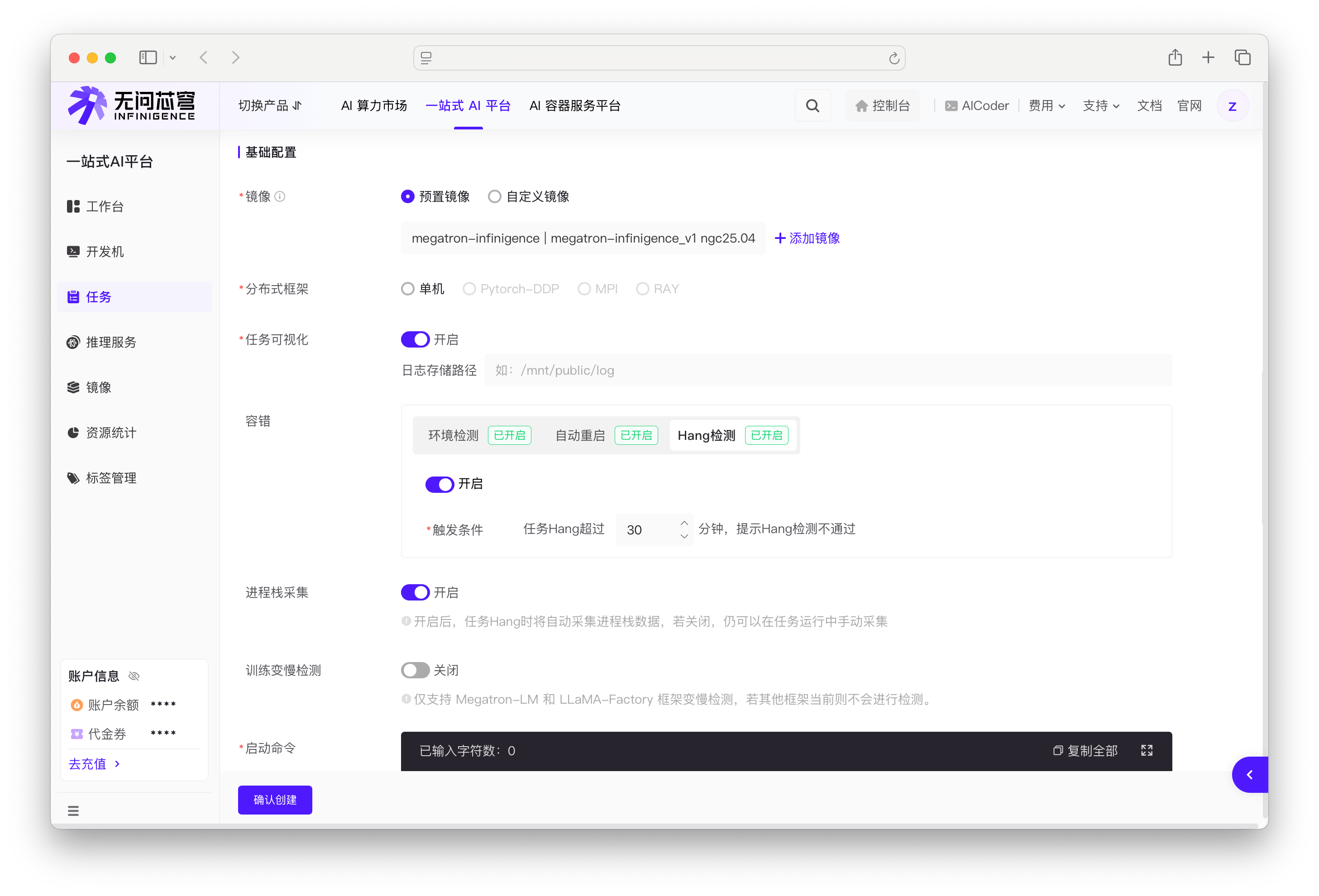
配置 Hang 检测
在创建任务时的容错配置区域进行设置,将 Hang 检测开关切换为开启状态,配置触发 Hang 检测失败的时长(分钟)。
信息
开启 Hang 检测后,环境检测和自动重启的任务 Hang 选项才可用。
配置建议
Hang 检测监控训练循环中的 GPU 计算活动,从首次 GPU 计算开始生效。任务启动阶段的 CPU 操作(如环境初始化、模型加载)不会触发检测。
平台已支持识别 Checkpoint(检查点)保存等训练阶段:在保存检查点等正当耗时阶段,可减轻因 GPU 活动暂时下降 导致的 Hang 误判;仍建议配合异步保存与合理超时阈值,以获得最稳妥的体验。
为确保 Hang 检测与您的训练任务良好配合,强烈建议遵循以下最佳实践:
- 推荐配置:使用异步检查点保存(如 PyTorch 异步保存功能),可避免训练循环阻塞,让 Hang 检测与检查点阶段识别更好配合。
其他配置场景:
- 使用同步检查点保存时:将超时阈值设置为大于检查点保存时间(例如:保存检查点需 30 分钟,超时设为 50 分钟以上)。
- 训练循环包含长时间 CPU 操作时:建议关闭 Hang 检测,或仅在 GPU 密集型分布式训练中使用。
准备训练脚本
实现基于检查点的恢复
容错功能可以自动重启任务,但无法自动恢复内存中的训练状态。因此,您的训练脚本必须支持优雅重启,即在每个进程启动时首先加载上次保存的检查点,然后继续训练。这样在任何故障情况下,您只会丢失自上次保存检查点以来的训练进度。
训练脚本中应包含 load_snapshot 和 save_snapshot 等类似逻辑:
def main():
load_snapshot(snapshot_path)
initialize()
train()
def train():
for batch in iter(dataset):
train_step(batch)
if should_checkpoint:
save_snapshot(snapshot_path)最佳实践:
- 检查点保存频率:根据训练时长和重启成本平衡保存频率。保存过于频繁会影响训练性能,保存过于稀疏会在重启时丢失较多进度。
- DDP 优化:使用 DDP 时,建议只在一个进程中保存模型,然后在所有进程中加载,从而减少写入开销。
参考资源:
- 具体实现可参考 PyTorch 官方文档 Saving and loading snapshots - Fault-tolerant Distributed Training with torchrun
- 使用 DDP 时的优化方法参见 PyTorch 官方文档 Save and Load Checkpoints - Getting Started with Distributed Data Parallel
查看容错日志
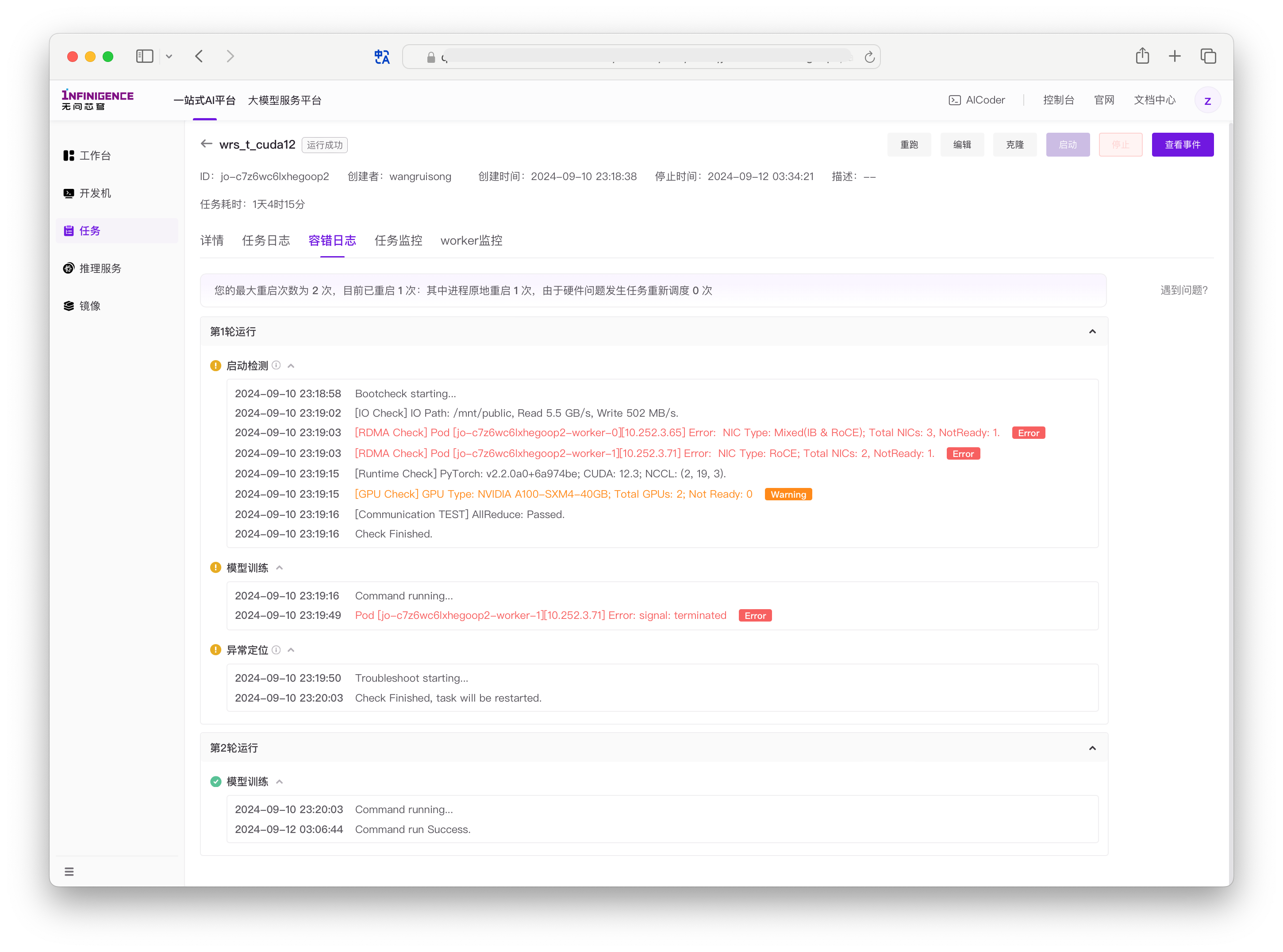
访问容错日志
开启容错功能后,可以在任务详情页找到"容错日志"标签页。日志记录了每一轮容错操作的详细信息。
容错日志顶部会显示:
- 最大重启次数
- 已重启次数
- 因硬件问题导致的重调度次数
信息
任务详情页的"任务日志"标签也会包含容错相关的日志输出。
查看环境检测日志
环境检测日志会显示每次检测的详细结果。日志内容取决于您的环境检测配置。
启动检测日志(任务运行前)
场景 1:开启启动检测
当您在配置中选中"任务运行前"检测时机时,任务启动时会执行完整的环境检测:
2025-01-08 15:54:15 Bootcheck starting...
2025-01-08 15:54:16 [IO Check] IO Path: /mnt/public, Read 7.6 GB/s, Write 408 MB/s.
2025-01-08 15:54:18 [RDMA Check] NIC Type: nil; Total NICs: 0, NotReady: 0.
2025-01-08 15:54:25 [Runtime Check] PyTorch: v2.3.0a0+40ec155e58.nv24.03; CUDA: 12.4; NCCL: (2, 20, 5).
2025-01-08 15:54:25 [GPU Check] GPU Type: NVIDIA A100-PCIE-40GB; Total GPUs: 2; Not Ready: 0
2025-01-08 15:54:31 [Communication Check] AllReduce connection passed.
2025-01-08 15:54:31 Check Finished.场景 2:未开启启动检测
当您未在配置中选中"任务运行前"检测时机时,启动检测会被跳过:
2026-01-08 17:44:59 Bootcheck starting...
2026-01-08 17:45:00 [Bootcheck Disabled] Bootcheck has been disabled.
2026-01-08 17:45:00 Check Finished.随后任务会直接开始执行用户代码:
2026-01-08 17:45:01 Command running...异常定位日志(任务失败时)
场景 1:开启任务失败检测
当任务失败且您选中了"任务失败"检测时机时,平台会自动执行异常定位:
2026-01-08 18:23:45 Command failed with exit code 1
2026-01-08 18:23:46 Troubleshoot starting...
2026-01-08 18:23:47 [IO Check] IO Path: /mnt/public, Read 7.4 GB/s, Write 395 MB/s.
2026-01-08 18:23:49 [RDMA Check] NIC Type: nil; Total NICs: 0, NotReady: 0.
2026-01-08 18:23:55 [Runtime Check] PyTorch: v2.3.0a0+40ec155e58.nv24.03; CUDA: 12.4; NCCL: (2, 20, 5).
2026-01-08 18:23:55 [GPU Check] GPU Type: NVIDIA A100-PCIE-40GB; Total GPUs: 2; Not Ready: 0
2026-01-08 18:24:01 [Communication Check] AllReduce connection passed.
2026-01-08 18:24:01 Check Finished.如果检测未发现硬件问题,任务会根据自动重启配置决定是否重启。
场景 2:未开启任务失败检测
当任务失败但您未选中"任务失败"检测时机时,不会执行异常定位,任务直接失败或根据自动重启配置决定是否重启。
Hang 检测日志(任务挂起时)
当开启 Hang 检测且任务被检测为挂起状态时,日志会记录检测事件:
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning如果您同时选中了"任务 Hang"检测时机,平台会随后执行环境检测:
2026-01-08 17:51:31 Troubleshoot starting...
2026-01-08 17:51:32 [IO Check] IO Path: /mnt/public, Read 7.5 GB/s, Write 401 MB/s.
2026-01-08 17:51:34 [RDMA Check] NIC Type: nil; Total NICs: 0, NotReady: 0.
2026-01-08 17:51:40 [Runtime Check] PyTorch: v2.3.0a0+40ec155e58.nv24.03; CUDA: 12.4; NCCL: (2, 20, 5).
2026-01-08 17:51:40 [GPU Check] GPU Type: NVIDIA A100-PCIE-40GB; Total GPUs: 2; Not Ready: 0
2026-01-08 17:51:46 [Communication Check] AllReduce connection passed.
2026-01-08 17:51:46 Check Finished.日志解读
检测项说明:
- IO Check:存储读写性能测试
- RDMA Check:RDMA 网卡状态和数量
- Runtime Check:PyTorch、CUDA、NCCL 版本信息
- GPU Check:GPU 型号和健康状态
- Communication Check:分布式通信连通性测试
异常情况处理:
- 仅在发现 GPU 掉卡错误时会触发重新调度到不同节点
- 其他类型的问题会在日志中记录,但任务继续执行或根据配置重启
查看自动重启日志
自动重启日志会记录每次重启事件的详细信息。
场景 1:任务失败触发自动重启
当任务执行失败且配置了"任务失败"触发条件时:
2026-01-08 18:24:01 Check Finished.
2026-01-08 18:24:02 Job failed with exit code 1. Auto-restart triggered (1/3).
2026-01-08 18:24:03 Restarting job...
2026-01-08 18:24:10 Bootcheck starting...日志中会显示:
- 失败原因(退出码)
- 当前重启次数和最大重启次数(例如:1/3 表示第 1 次重启,最多 3 次)
- 重启操作的时间点
场景 2:任务 Hang 触发自动重启
当任务被检测为挂起且配置了"任务 Hang"触发条件时:
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning
2026-01-08 17:51:46 Check Finished.
2026-01-08 17:51:47 Job hang detected. Auto-restart triggered (2/5).
2026-01-08 17:51:48 Restarting job...
2026-01-08 17:51:55 Bootcheck starting...场景 3:重新调度到不同节点
当环境检测发现 GPU 掉卡等硬件问题时,任务会重新调度到健康节点:
2026-01-08 19:15:23 [GPU Check] GPU Type: NVIDIA A100-PCIE-40GB; Total GPUs: 8; Not Ready: 1
2026-01-08 19:15:23 GPU card drop detected on node-123. Rescheduling to healthy node.
2026-01-08 19:15:24 Check Finished.
2026-01-08 19:15:25 Rescheduling job to different node...
2026-01-08 19:15:35 Job rescheduled to node-456.
2026-01-08 19:15:36 Bootcheck starting...重新调度的任务会在新节点上重新开始执行。
场景 4:达到最大重启次数
当重启次数达到配置的上限时,任务将失败:
2026-01-08 20:30:15 Check Finished.
2026-01-08 20:30:16 Job failed with exit code 1. Maximum restart count reached (3/3).
2026-01-08 20:30:16 Job terminated due to exceeding maximum restart attempts.查看 Hang 检测日志
Hang 检测日志会记录任务挂起的检测事件和相关操作。
Hang 检测触发示例
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning日志解读:
- 检测时间:2026-01-08 17:51:30
- 检测结果:任务可能已挂起
- 触发来源:gpuprobe(GPU 探测模块,自动检测)或 webterminal(手动触发
atlctl hang) - 自动操作:清理相关进程
查看任务事件
除了在容错日志标签查看详细日志外,还可以在任务详情页点击查看事件按钮,查看 Hang 检测的生命周期事件。
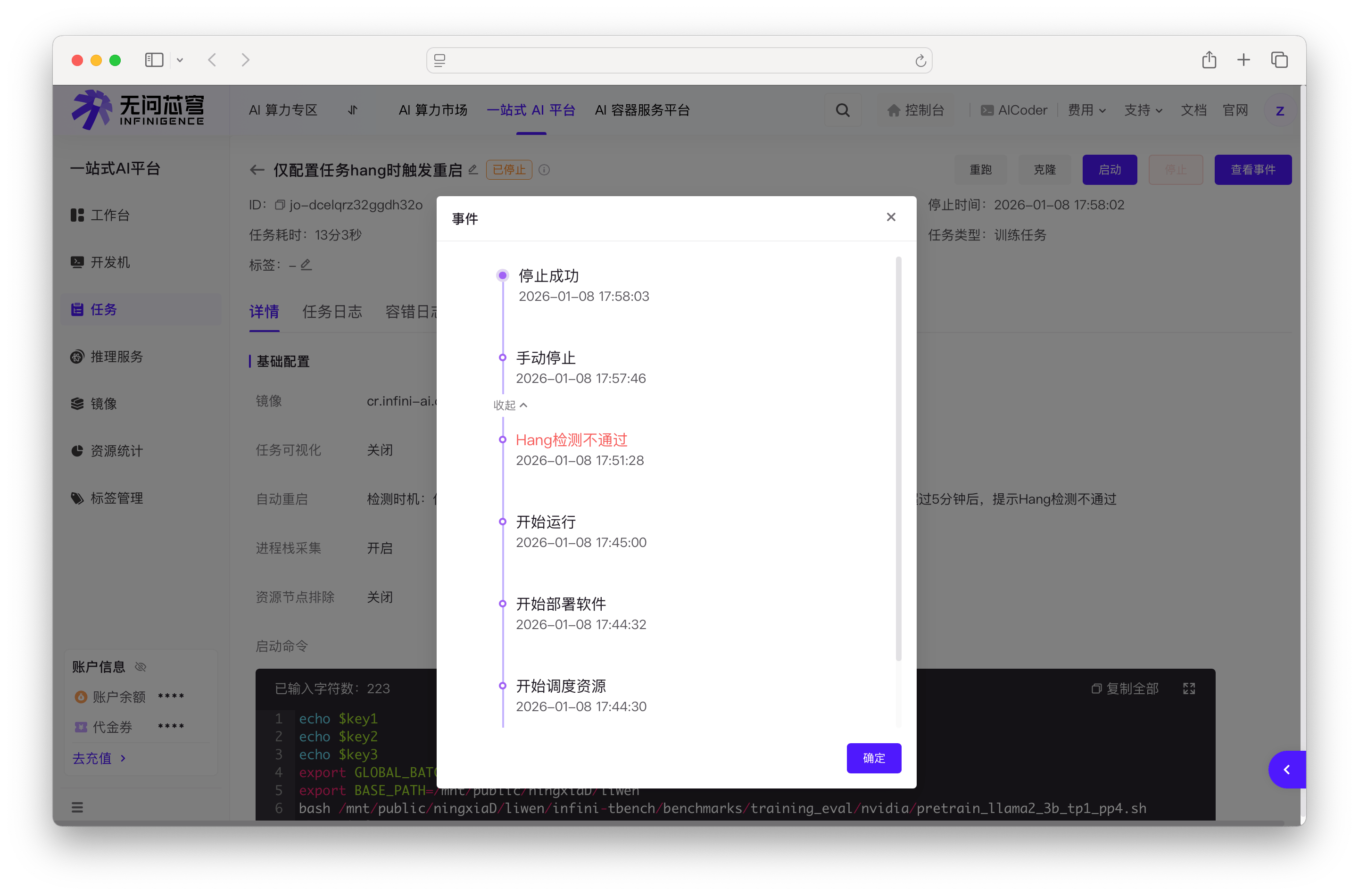
事件列表中会显示 "Hang 检测不通过" 事件及其时间戳,方便快速了解任务的 Hang 检测历史。
Hang 检测后的处理流程
根据您的配置,Hang 检测后可能触发以下操作:
1. 仅开启 Hang 检测(无后续操作):
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning
2026-01-08 17:51:31 Hang detection completed. No further actions configured.2. Hang 检测 + 环境检测("任务 Hang"时机):
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning
2026-01-08 17:51:31 Troubleshoot starting...
2026-01-08 17:51:32 [IO Check] IO Path: /mnt/public, Read 7.5 GB/s, Write 401 MB/s.
...
2026-01-08 17:51:46 Check Finished.3. Hang 检测 + 自动重启("任务 Hang"触发条件):
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning
2026-01-08 17:51:31 Job hang detected. Auto-restart triggered (1/5).
2026-01-08 17:51:32 Restarting job...4. Hang 检测 + 环境检测 + 自动重启(完整配置):
2026-01-08 17:51:30 This job may have caused a hang. Relevant processes are being cleaned up. Triggered by: gpuprobe | Warning
2026-01-08 17:51:31 Troubleshoot starting...
2026-01-08 17:51:32 [IO Check] IO Path: /mnt/public, Read 7.5 GB/s, Write 401 MB/s.
...
2026-01-08 17:51:46 Check Finished.
2026-01-08 17:51:47 Job hang detected. Auto-restart triggered (1/5).
2026-01-08 17:51:48 Restarting job...相关文档
- 使用 atlctl 进行手动调试:了解如何使用 atlctl 工具手动执行环境检测和调试命令。
- 创建训练任务:了解如何创建和配置训练任务,如何找到容错配置区域。