

训练 MOE 模型
我们已将 Megatron-Infinigence 训练工具组合打包为容器镜像,用户可直接拉取镜像使用,无需手动配置环境。
镜像名称: infini-ai/megatron-infinigence:v1-ngc25.04-20250725
查看训练框架目录结构
root@c3c6f53a836b:~# tree -L 2 /root/megatron-infinigence/
/root/megatron-infinigence/
├── Megatron-LM -> Megatron-LMs/Megatron-LM_core_r0.8.0
├── Megatron-LMs
│ └── Megatron-LM_core_r0.8.0
├── README.md
├── dist
│ └── megatron_infini-0.0.1-cp312-cp312-linux_x86_64.whl
├── docs
│ ├── MoEtutorial.md
│ ├── profile.md
│ └── qwen3_sft.md
├── megatron_infini
│ ├── __init__.py
│ ├── apply_patcher.cpython-312-x86_64-linux-gnu.so
│ ├── common
│ ├── core
│ ├── examples
│ ├── hardware
│ ├── hetero
│ ├── models
│ ├── multimodal
│ ├── pretrain_deepseek.py
│ ├── pretrain_llama.py
│ ├── pretrain_llava.py
│ ├── pretrain_qwen_moe.py
│ ├── schedulers
│ └── utils
├── requirements.txt
└── tools
├── auto_parallel
├── ckpt_convert
├── loss_align
├── pipeline_simulate
├── plot_scripts
└── preprocess_data性能提升
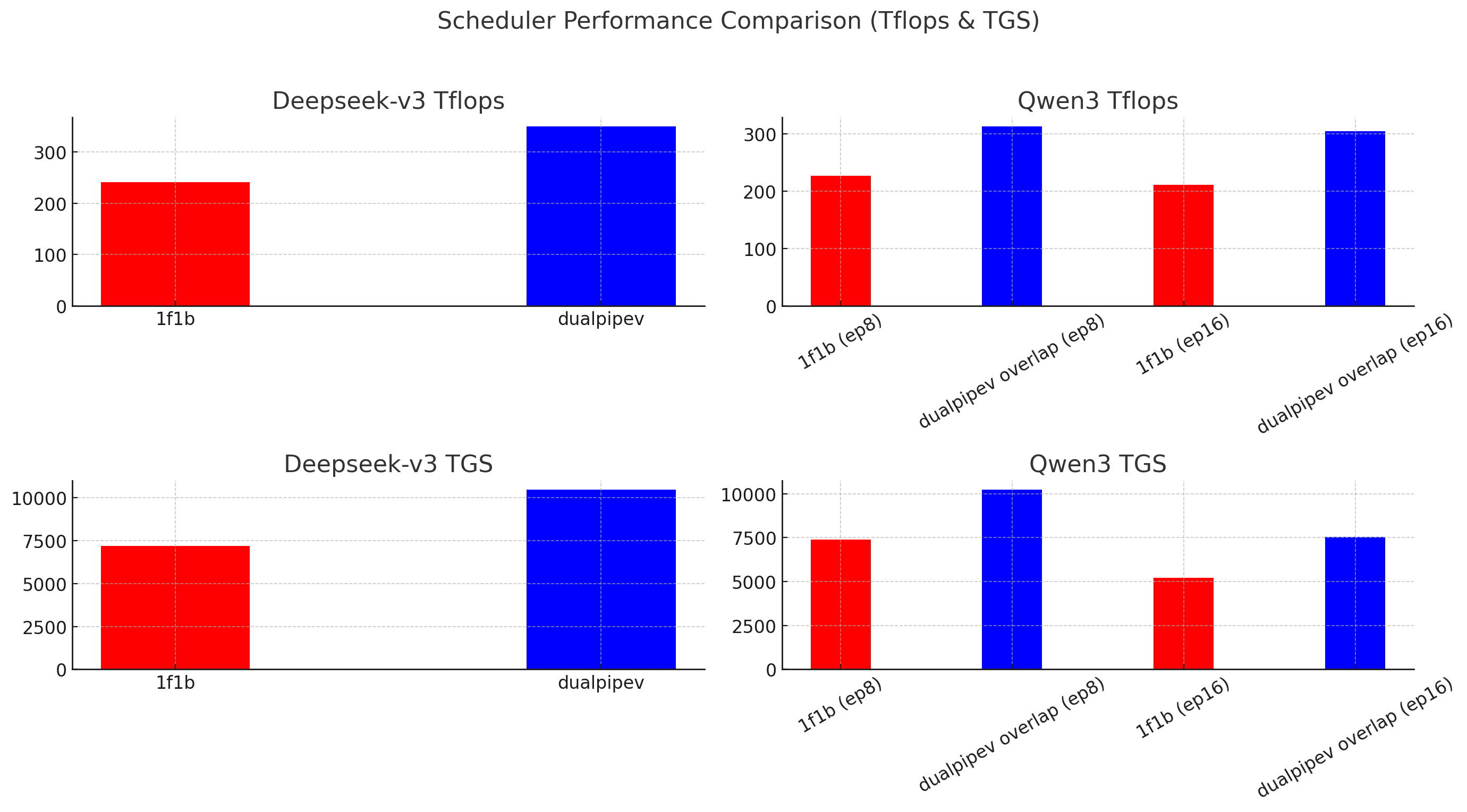
在相同硬件配置(8× H100,TP=1,TPE=1)下,我们对比了不同调度器(1f1b 与 dualpipev)在 Deepseek-v3(7 层,Expert=256)和 Qwen3-235B-A22B(30 层,Expert=128)模型训练中的表现。结果显示,dualpipev 在两个模型上均实现显著性能提升:
- Deepseek-v3 提升约 45%
- Qwen3 提升约 41%
下图展示了不同配置下的 TFLOPS 和每卡每秒吞吐量(TGS)对比:
详细性能测试指标与测试脚本,可参考下文 性能测试。
训练参数
本节详细介绍 Megatron-Infinigence MoE 训练框架的各种参数配置,包括模型配置参数和高级优化特性。这些参数帮助用户根据具体需求和硬件环境优化训练性能。
模型配置参数
以下是针对不同模型架构的核心配置参数,包括 MLA、YARN RoPE 和 MOE 等关键组件的参数设置。
MLA 参数
针对 Multi-head Latent Attention (MLA) 架构的专用配置参数:
--q-lora-rank: MLA 的 Q latent 维度。针对 16B 的 DeepSeek V2 Lite 不使用--kv-lora-rank: MLA 的 K & V latent 维度--qk-rope-head-dim: MLA 的 Q 和 K 的 RoPE 部分的维度--qk-nope-head-dim: MLA 的 Q 和 K 的没有 RoPE 部分的维度--v-head-dim: MLA 的 V 的 head 维度--mla-replicate-l1: MLA 的 replicate L1 优化。针对 TP 切分生效。当开启时,Q/K/V 的 down_proj 不切分,只切分 up_proj,减少一次通信;关闭时,Q/K/V 的 down_proj 和 up_proj 都切分。建议开启,提升 1-3% 性能--mla-fuse-qkv: MLA 的计算中,Q/K/V 的 down_proj 计算合并。对性能几乎无影响,但可以支持 LayerNorm 和 down_proj 的 fuse,重算以节省显存。只支持有 Q-LoRA 的场景。不建议开启,除非显存严重不足,接受降低 3-7% 性能节省 3% 显存
YARN RoPE 参数
针对 DeepSeek 模型中 YARN RoPE 的配置参数:
--rotary-scaling-factor: DeepSeek 中 YARN RoPE 的缩放因子--rotary-mscale: DeepSeek 中 YARN RoPE 的 mscale 参数--rotary-mscale-all-dim: DeepSeek 中 YARN RoPE 的全维度 mscale 参数--original-max-position-embeddings: DeepSeek 中 YARN RoPE 的原始最大位置嵌入--rotary-beta-fast: DeepSeek 中 YARN RoPE 的快速 beta 参数--rotary-beta-slow: DeepSeek 中 YARN RoPE 的慢速 beta 参数
MOE 参数
针对 Mixture of Experts (MOE) 架构的专用配置参数:
--first-k-dense-replace: 针对 DeepSeek 模型,前 K 层使用 Dense 而非 MOE。仅在 DeepSeek 模型中生效--moe-router-topk-scaling-factor: Router score 的 scaling 因子。DeepSeek V2 中使用,V3 中不使用。仅在 DeepSeek 模型中生效--moe-router-deepseekv3: 使用 DeepSeek V3 的 MOE router。支持 loss-free 的 router load balance 策略;尚不支持 device-limited 的 router 策略--moe-router-score-function: 可选 router score function,支持 softmax 和 sigmoid。DeepSeek V3 中使用 sigmoid。仅当moe-router-deepseekv3开启时生效--moe-router-enable-expert-bias: MLA 的 MOE router 的 enable expert bias。仅当moe-router-deepseekv3开启时生效--moe-router-bias-update-rate: Loss-free 的 router load balance 策略中 update rate。仅当moe-router-deepseekv3开启时生效--enable-shared-expert-gate: 开启 shared expert gate。仅在 Qwen 模型中生效--moe-token-dispatcher-type-patch: 优化后的 dispatcher。配合 DualpipeV 使用时,当使用overlap_allgather_fused和overlap_deepep时,支持通信和计算重叠。仅在 DeepSeek 和 Qwen 模型中生效
高级优化特性
以下是 Megatron-Infinigence 框架提供的高级优化特性,这些特性可以显著提升 MoE 模型的训练性能和内存效率。用户可以根据硬件配置和性能需求选择合适的优化组合。
DualpipeV+ 流水线调度
DualpipeV 是基于 Deepseek 开源的 dualpipe 变体的一种流水线调度方式。相较于 1f1b 的流水方式,该方式可以重叠两个 micro batch 之间的前向反向计算与 MLP 层前后 dispatch 和 combine 的通信。我们提出了 DualPipeV 流水编排的优化版本 DualPipeV+,显著降低了显存开销。
使用方式:
在 megatron-infinigence 中打开如下开关:
--scheduler dualpipev计算与通信重叠优化
在统一框架中,如果想要重叠前后计算与 MLP 层前后的 allgather 通信,需要使用特殊的 dispatch 组件。
使用方式:
该开关需要配合 dualpipev 一起使用,在 megatron-infinigence 中打开如下开关:
--scheduler dualpipev
--moe-token-dispatcher-type-patch overlap_allgather_fusedMLP 部分重算优化
在统一框架中,为了节省显存的前提下并且保持原本的计算性能,我们针对部分显存消耗较高的组件进行了重算。针对 MLP 部分的前后两次 fc1 和 fc2,我们只重算第一个 fc1 而不对第二个 fc2 进行重算,这个操作我们称为对 MLP 层的 recompute。
使用方式:
在 megatron-infinigence 中打开如下开关:
--mlp-recomputeTEgroupgemm 加速支持
在统一框架中,目前集成了 TEgroupgemm 组件,该组件使用 transformer-engine 库中提供的高效 groupgemm 算子,将 MLP 层多个 expert 矩阵乘计算融合为一个 groupgemm 算子来提高矩阵乘算子的计算性能。
使用方式:
在 megatron-infinigence 中打开如下开关:
--moe-grouped-gemm-teFlash Attention 3 支持
目前 flashattn 发布了 flashattn3 的算子专门针对 NVIDIA Hopper 系列的 GPU 提高 flash-attn 的性能。
使用方式:
注意如果使用 transformer-engine 内置使用的是 te 自带的 flash-attn,因此需要切换到 local 的 transformer-impl 才能调用到 flash-attn3 算子。
在 megatron-infinigence 中打开如下开关:
export PYTHONPATH=${PROJECT_PATH}:${PROJECT_PATH}/Megatron-LM:$PYTHONPATH:/workspace/flash-attention
--transformer-impl local预训练示例
本节演示如何在已有开源大模型(示例:DeepSeek-V3 / Qwen3)基础上进行预训练),覆盖模型与分词器准备、数据集预处理、权重格式转换、以及在 AIStudio 上发起分布式训练任务的完整流程。
Step 0 下载模型
AIStudio 任务在多个可用区可用。您的模型及所有训练数据必须上传至训练任务所在可用区的共享高性能存储目录中,并完成相应的预处理。
注意
为避免存储访问问题,请确保您的数据与训练任务位于同一可用区。不同可用区之间的存储资源相互隔离,无法跨区直接使用。请按照下文指导进行配置。
请自行下载模型 weight 以及 tokenizer,以 DeepseekV3 为例。
git clone https://modelscope.cn/models/deepseek-ai/DeepSeek-V3注意
由于模型与数据集下载受多种因素影响。为保证高效利用资源,建议提前下载模型与数据集。您可以直接利用 AICoder 下载公有模型与数据集,或通过 AICoder 上传自有数据至选定可用区的共享存储中。
Step 1 处理预训练数据
Megatron Infinigence 使用 MMAP 格式的预训练数据,这种格式经过预先的 tokenize 处理,大大缩短了数据读入时间,尤其在数据量庞大时优势明显。
测试时可以直接使用镜像中已经处理好的数据集:
/workspace/datasets/DeepSeek-V3/
├── deepseekv3_text_document.bin
└── deepseekv3_text_document.idx
/workspace/datasets/Qwen3-30B-A3B/
├── qwen3_text_document.bin
└── qwen3_text_document.idx以下以中文 wudao2.0 数据集的准备流程为例,给出数据预处理指引。
建议通过 AICoder 挂载您已购买的 共享高性能存储,在 AICoder 中通过以下命令下载和解压至共享高性能存储中指定目录。
shellwget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/datasets/WuDaoCorpus2.0_base_sample.tgz tar zxvf WuDaoCorpus2.0_base_sample.tgz在真实场景中,建议通过 AIStudio 任务功能的数据处理任务(不占用 GPU)或 AIStudio 开发机的数据处理任务完成预处理工作。以下以数据处理任务为例,给出数据预处理指引。该类型任务使用租户自购的包年包月资源池中空闲的 CPU 资源,并且优先保障与 GPU 相关任务不受影响。
在智算云平台任务列表页面点击 创建任务,进入创建任务界面,可创建单机或分布式任务。
在任务页面,选择任务类型为数据处理任务。根据页面提示,完成其他所有步骤中的配置。
注意
如果 worker 规格列表中没有可选规格,您可以联系商务或售后服务。
在启动命令中,填写您的数据转换命令。Megatron-infinigence 容器镜像中预置了数据集处理脚本。以下通过使用该工具简述数据预处理要求,对 Wudao 数据执行数据集清洗并进行文件格式转换。请注意正确配置环境变量:
shellWUDAO_DATA_PATH=WUDAO_DATA_PATH # download dataset path WORKSHOP_PATH=WORKSHOP_PATH # megatron-infinigence file path OUTPUT_FILE=OUTPUT_FILE # ouput megatron-infinigence dataset file path TOKENIZER_PATH=TOKENIZER_PATH # tokenzier file path PATCH_TOKENIZER_TYPE=PATCH_TOKENIZER_TYPE # tokenzier type EXTRA_VOCAB_SIZE=EXTRA_VOCAB_SIZE # extra vocab size bash megatron-infinigence/tools/preprocess_data/preprocess_data.sh注意
您可以使用其他数据转换工具,也可以参考镜像中
megatron-infinigence/tools/preprocess_data/目录下的脚本进行修改和使用。
运行成功后得到处理好的数据集。
.bin文件储存 Token 数据,.idx文件存储文档元信息(包括index头、版本号、数据类型、数据大小等信息)。- OUTPUT_FILE_text_document.bin
- OUTPUT_FILE_text_document.idx
Step 2 转换模型格式
在训练前,需要先确定训练的并行配置,然后进行权重转换处理。在实际使用时,可以在 AIStudio 平台使用以下方式完成权重转换:
- 使用 AIStudio 任务功能的数据处理任务完成预处理工作。该类型任务使用租户自购的包年包月资源池中空闲的 CPU 资源,并且优先保障与 GPU 相关任务不受影响。
- 使用 AIStudio 的开发机功能,在 GPU 环境中进行权重转换。
Megatron-infinigence 框架中已经内置了权重转换工具。
/root/megatron-infinigence/tools/ckpt_convert/
├── README.md
├── examples
│ ├── 1.hf-mg-cpu-distil_qwen2_1.5b.sh
│ ├── 2.mg-hf-cpu-distil_qwen2_1.5b.sh
│ ├── 3.hf-mg-cpu-distil_qwen2_7b.sh
│ └── 4.mg-hf-cpu-distil_qwen2_7b.sh
├── src
│ ├── compare_safetensors.py
│ ├── convert_hf_to_middle_file.py
│ ├── convert_mg_to_middle_file.py
│ ├── convert_middle_file_to_hf.py
│ ├── convert_middle_file_to_mg.py
│ ├── default_args.yaml
│ └── utils
│ ├── __init__.py
│ ├── fp8_utils.py
│ ├── mg_loader.py
│ ├── mp_utils.py
│ ├── safetensors_loader.py
│ └── tensor_operations.py
└── tests
├── 1.hf-middle_file-hf-check-cpu-qwen3.sh
└── 2.hf-middle_file1-mg-middle_file2-check-gpu-qwen2.sh
5 directories, 19 files在使用前,请详细阅读 megatron-infinigence/tools/ckpt_convert/README.md。
警告
请确认好之后需要跑的并行配置,不同并行配置之间的 ckpt 不能通用。
SCRIPT_PATH=/磁盘路径/megatron-infinigence/tools/ckpt_convert/src
CKPT_PATH_HF=/磁盘路径/ckpt/DeepSeek-V3
CKPT_PATH_MF=/磁盘路径/ckpt/DeepSeek-V3_middle_file
CKPT_PATH_MG=/磁盘路径/ckpt/DeepSeek-V3_mg_tp1_pp2
TP_SIZE=1
PP_SIZE=2
# # download
# modelscope download --model 'deepseek-ai/DeepSeek-V3' --local_dir "$CKPT_PATH_HF"
rm -rf $CKPT_PATH_MF
python $SCRIPT_PATH/convert_hf_to_middle_file.py \
--load-path $CKPT_PATH_HF \
--save-path $CKPT_PATH_MF \
--model 'DeepSeek-V3' \
--use-gpu-num 0 \
--process-num 16rm -rf $CKPT_PATH_MG
python $SCRIPT_PATH/convert_middle_file_to_mg.py \
--load-path $CKPT_PATH_MF \
--save-path $CKPT_PATH_MG \
--model 'DeepSeek-V3' \
--tp-size $TP_SIZE \
--tpe-size 1 \
--ep-size 1 \
--pp-size $PP_SIZE \
--use-gpu-num 0 \
--process-num 16rm -rf $CKPT_PATH_MFStep 3 运行预训练任务
在完成数据准备与权重格式转换后,即可发起预训练任务。该步骤重点关注:作业类型选择、镜像/启动脚本、并行与调度器参数校验、以及日志与性能监控。
在智算云平台任务列表页面点击 创建任务,进入创建任务界面,可创建单机或分布式任务。
在任务页面,选择任务类型为训练任务。配置任务 Worker 规格、Worker 数量,设置「分布式框架」为 Pytorch DDP。根据页面提示,完成其他所有步骤中的配置。
选择镜像为
infini-ai/megatron-infinigence:v1-ngc25.04-20250725。Megatron-infinigence 框架中已经预置了测试脚本,您可以直接使用这些脚本运行任务进行测试。
shell/root/megatron-infinigence/megatron_infini/examples/ ├── moe │ └── nvidia │ ├── deepseekv3_671b.sh │ ├── qwen3_235b.sh │ ├── test_deepseek.sh │ ├── test_deepseek_node16.sh │ ├── test_deepseek_node16_baseline.sh │ ├── test_deepseek_node32.sh │ ├── test_deepseek_node32_baseline.sh │ ├── test_deepseek_node8.sh │ ├── test_deepseek_node8_baseline.sh │ ├── test_qwen3.sh │ ├── test_qwen3_node16.sh │ ├── test_qwen3_node16_baseline.sh │ ├── test_qwen3_node32.sh │ ├── test_qwen3_node32_baseline.sh │ ├── test_qwen3_node8.sh │ └── test_qwen3_node8_baseline.sh注意
请注意修改其中的相关并行参数并导入对应的 tokenzier,数据集以及转换好的 ckpt。
在启动命令中,运行测试脚本:
shellbash megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek.sh
SFT 示例
本节展示如何基于 Qwen3 30B A3B 模型执行监督微调 (SFT) 。流程与上方预训练示例平行:涵盖前置准备、数据获取与格式转换、模型 Checkpoint 按并行配置切分、单机示例训练、转换回 Hugging Face 格式以及结果快速校验。一键脚本亦提供端到端自动化。
Step 0 前置准备
确认运行环境与工作目录。以下以使用 AIStudio 的开发机为例。
镜像:
infini-ai/megatron-infinigence:v1-ngc25.04-20250725创建工作目录并设置环境变量:
shellmkdir -p /mnt/public/example_qwen3_sft/ export QWEN3_SFT_WORKSPACE=/mnt/public/example_qwen3_sft
Step 1 数据准备
包含 tokenizer 下载、模型权重下载、指令数据集获取与格式转换。
下载 tokenizer。
shell# 使用 modelscope modelscope download --model "Qwen/Qwen3-30B-A3B" --exclude "*.safetensors" --local_dir "${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_tokenizer" # 使用 huggingface-cli huggingface-cli download "Qwen/Qwen3-30B-A3B" --resume-download --exclude "*.safetensors" --local-dir "${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_tokenizer" # 国内环境使用 huggingface-cli 可以通过 hf-mirror 加速 export HF_ENDPOINT=https://hf-mirror.com下载模型
shell# 使用 modelscope modelscope download --model "Qwen/Qwen3-30B-A3B" --local_dir "${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_hf" # 使用 huggingface-cli huggingface-cli download "Qwen/Qwen3-30B-A3B" --resume-download --local_dir "${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_hf" # 国内环境使用 huggingface-cli 可以通过 hf-mirror 加速 export HF_ENDPOINT=https://hf-mirror.com下载数据集(示例:alpaca_data_zh_51k)
shellmkdir -p ${QWEN3_SFT_WORKSPACE}/data/ wget https://github.com/ymcui/Chinese-LLaMA-Alpaca/raw/refs/heads/main/data/alpaca_data_zh_51k.json -O ${QWEN3_SFT_WORKSPACE}/data/alpaca_data_zh_51k.json # 国内环境可以使用 ghfast.top 加速 wget https://ghfast.top/github.com/ymcui/Chinese-LLaMA-Alpaca/raw/refs/heads/main/data/alpaca_data_zh_51k.json -O ${QWEN3_SFT_WORKSPACE}/data/alpaca_data_zh_51k.json转换数据格式。
说明:
- SFT 数据集读取遵循
Qwen3SFTDataset.preprocess。 - 仅支持 OpenAI 对话格式,不直接支持 Alpaca 原始格式,需转换。
- 示例脚本
scripts/alpaca_to_openai.py将 Alpaca 格式转为 OpenAI 格式。 - 其他自定义格式请先自行规范化到 OpenAI 格式(包含 role / content 列表结构)。
执行转换:
shellpython3 scripts/alpaca_to_openai.py ${QWEN3_SFT_WORKSPACE}/data/alpaca_data_zh_51k.json ${QWEN3_SFT_WORKSPACE}/data/alpaca_converted.json- SFT 数据集读取遵循
Step 2 转换模型 Checkpoint
SFT 前需根据目标并行策略 (TP / TPE / EP / PP / Scheduler) 生成Mmegatron-infinigence 可加载的分片权重。以下展示两种并行布局:
配置 1: tp1 tpe1 ep2 pp4, pp 使用 1f1b schedular
shellbash /root/megatron-infinigence/megatron_infini/examples/qwen3_sft/convert-hf_mg-qwen3_30b_a3b-1.sh配置 2: tp1 tpe1 ep1 pp8, pp 使用 1f1b schedular
shellbash /root/megatron-infinigence/megatron_infini/examples/qwen3_sft/convert-hf_mg-qwen3_30b_a3b-2.sh
注意
框架已对 Megatron Checkpoint 兼容性做增强:
- 在启用 transformer-engine 时仍可加载 local impl 生成的权重。
- 在开启 MoE grouped gemm 时可加载顺序 gemm 生成的权重。
- 因此无需为上述开关分别重复转换,减少磁盘占用。
Step 3 训练示例
以下提供几个示例(对应上面的两种并行切分),日志将写入 result 目录。请按需修改 EP / PP / 数据路径 / LOAD_PATH。
单机 SFT 训练配置 1
配置 1:tp1 tpe1 ep2 pp4, pp 使用 1f1b schedular
# 单机 SFT 训练配置 1, tp1 tpe1 ep2 pp4, pp 使用 1f1b schedular
export QWEN3_SFT_WORKSPACE=${QWEN3_SFT_WORKSPACE:-/mnt/public/example_qwen3_sft}
export PROJECT_PATH=${PROJECT_PATH:-/root/megatron-infinigence}
WORLD_SIZE=1
RANK=0
export NNODES=${WORLD_SIZE}
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NODE_RANK=${RANK}
export TD=allgather
export SCHD=1f1b
export TP=1
export TPE=1
export EP=2
export PP=4
export LOAD_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep2_pp4
export SAVE_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep2_pp4
export CPU_ADAM=1
export TIME=$(date +"%Y%m%d%H%M%S")
export log_path=${PROJECT_PATH}/result/NNODES${NNODES}_${TIME}_test_TP${TP}_TPE${TPE}_EP${EP}_PP${PP}
export GROUP_GEMM_TE=1
if [ ! -d "$log_path" ]; then
echo ${log_path}
mkdir -p ${log_path}
fi
bash ${PROJECT_PATH}/megatron_infini/examples/qwen3_sft/qwen3_30b_a3b_sft.sh 2>&1 | tee -a ${log_path}/rank${NODE_RANK}.log单机 SFT 训练配置 2
单机 SFT 训练配置 2:tp1 tpe1 ep1 pp8, pp 使用 1f1b schedular
# 单机 SFT 训练配置 2, tp1 tpe1 ep1 pp8, pp 使用 1f1b schedular
export QWEN3_SFT_WORKSPACE=${QWEN3_SFT_WORKSPACE:-/mnt/public/example_qwen3_sft}
export PROJECT_PATH=${PROJECT_PATH:-/root/megatron-infinigence}
WORLD_SIZE=1
RANK=0
export NNODES=${WORLD_SIZE}
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NODE_RANK=${RANK}
export TD=allgather
export SCHD=1f1b
export TP=1
export TPE=1
export EP=1
export PP=8
export LOAD_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep1_pp8
export SAVE_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep1_pp8
export CPU_ADAM=1
export TIME=$(date +"%Y%m%d%H%M%S")
export log_path=${PROJECT_PATH}/result/NNODES${NNODES}_${TIME}_test_TP${TP}_TPE${TPE}_EP${EP}_PP${PP}
export GROUP_GEMM_TE=1
if [ ! -d "$log_path" ]; then
echo ${log_path}
mkdir -p ${log_path}
fi
bash ${PROJECT_PATH}/megatron_infini/examples/qwen3_sft/qwen3_30b_a3b_sft.sh 2>&1 | tee -a ${log_path}/rank${NODE_RANK}.log多机 SFT 训练配置 1
多机 SFT 训练配置配置:tp1 tpe1 ep2 pp4, pp 使用 1f1b schedular
注意
建议使用 AIStudio 任务功能发起多机分布式训练。
# 配置1,tp1 tpe1 ep2 pp4, pp 使用 1f1b schedular
export QWEN3_SFT_WORKSPACE=${QWEN3_SFT_WORKSPACE:-/mnt/public/example_qwen3_sft}
export PROJECT_PATH=${PROJECT_PATH:-/root/megatron-infinigence}
export NNODES=${WORLD_SIZE}
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NODE_RANK=${RANK}
export TD=allgather
export SCHD=1f1b
export TP=1
export TPE=1
export EP=2
export PP=4
export LOAD_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep2_pp4
export SAVE_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep2_pp4
export CPU_ADAM=1
export TIME=$(date +"%Y%m%d%H%M%S")
export log_path=${PROJECT_PATH}/result/NNODES${NNODES}_${TIME}_test_TP${TP}_TPE${TPE}_EP${EP}_PP${PP}
export GROUP_GEMM_TE=1
if [ ! -d "$log_path" ]; then
echo ${log_path}
mkdir -p ${log_path}
fi
bash ${PROJECT_PATH}/megatron_infini/examples/qwen3_sft/qwen3_30b_a3b_sft.sh 2>&1 | tee -a ${log_path}/rank${NODE_RANK}.log多机 SFT 训练配置 2
多机 SFT 训练配置配置: tp1 tpe1 ep1 pp8, pp 使用 1f1b schedular
注意
建议使用 AIStudio 任务功能发起多机分布式训练。
# 配置2, tp1 tpe1 ep1 pp8, pp 使用 1f1b schedular
export QWEN3_SFT_WORKSPACE=${QWEN3_SFT_WORKSPACE:-/mnt/public/example_qwen3_sft}
export PROJECT_PATH=${PROJECT_PATH:-/root/megatron-infinigence}
export NNODES=${WORLD_SIZE}
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NODE_RANK=${RANK}
export TD=allgather
export SCHD=1f1b
export TP=1
export TPE=1
export EP=1
export PP=8
export LOAD_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep1_pp8
export SAVE_PATH=${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_mg_tp1_tpe1_ep1_pp8
export CPU_ADAM=1
export TIME=$(date +"%Y%m%d%H%M%S")
export log_path=${PROJECT_PATH}/result/NNODES${NNODES}_${TIME}_test_TP${TP}_TPE${TPE}_EP${EP}_PP${PP}
export GROUP_GEMM_TE=1
if [ ! -d "$log_path" ]; then
echo ${log_path}
mkdir -p ${log_path}
fi
bash ${PROJECT_PATH}/megatron_infini/examples/qwen3_sft/qwen3_30b_a3b_sft.sh 2>&1 | tee -a ${log_path}/rank${NODE_RANK}.logStep 4 转回 Hugging Face 格式
用于发布或下游推理,需要将 Megatron 分片权重恢复为 Hugging Face 结构(两种并行配置分别执行):
配置1:tp1 tpe1 ep2 pp4, pp 使用 1f1b schedular
shell# 1. 配置1 bash /root/megatron-infinigence/megatron_infini/examples/qwen3_sft/convert-mg_hf-qwen3_30b_a3b-1.sh配置2:tp1 tpe1 ep1 pp8, pp 使用 1f1b schedular
shell# 2. 配置2 bash /root/megatron-infinigence/megatron_infini/examples/qwen3_sft/convert-mg_hf-qwen3_30b_a3b-2.sh
Step 5 结果测试
对已转回 Hugging Face 格式的权重做最小功能正确性验证:
python /root/megatron-infinigence/megatron_infini/examples/qwen3_sft/simple_test.py --load-path ${QWEN3_SFT_WORKSPACE}/qwen3_30b_a3b_hf_release性能测试
单机脚本验证已经内置在该路径下,由于单机显存限制,对模型进行削减:
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3.sh目前提供8,16,32机的性能复现脚本如下:
# 运行分布式代码前,需要将存储在镜像内部的 dataset 复制至共享磁盘
if [[ $RANK == 0 ]]; then
cp -r /workspace/datasets /共享高性能存储路径/
fi
export DATA_PATH=/共享磁盘/datasets/DeepSeek-V3/deepseekv3_text_document
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek_node8.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek_node8_baseline.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek_node16.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek_node16_baseline.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek_node32.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_deepseek_node32_baseline.sh
export DATA_PATH=/共享磁盘/datasets/Qwen3-30B-A3B/qwen3_text_document
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3_node8.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3_node8_baseline.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3_node16.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3_node16_baseline.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3_node32.sh
/root/megatron-infinigence/megatron_infini/examples/moe/nvidia/test_qwen3_node32_baseline.sh以下是不同调度器配置下的性能对比数据:
Deepseek-v3 Tp 1 tpe1 expert 256 7 层 8机 H100 (性能提升 45%)
| scheduler | ep | pp | hpp | cpuadam | attn | recompute | groupgemm | Tflops / tgs |
|---|---|---|---|---|---|---|---|---|
| 1f1b | 16 | 2 | 4 3 | NA | fla3 | 无 | te | 241.3 / 7183 |
| dualpipev | 16 | 2 | 2 2 1 2 | NA | fla3 | 无 | te | 350 / 10469.135 |
qwen3 tp1 tpe1 expert 128 30层 8机 H100 (性能提升 41%)
| scheduler | ep | pp | hpp | cpuadam | attn | recompute | groupgemm | Tflops / tgs |
|---|---|---|---|---|---|---|---|---|
| 1f1b | 8 | 4 | 2 3 3 3 2 3 3 3 | NA | fla3 | 无 | te | 226.1 / 7392.604 |
| 1f1b | 16 | 4 | 7 8 8 7 | NA | fla3 | 无 | te | 210.8 / 5224.775 |
| dualpipev overlap | 8 | 4 | 2 3 3 3 2 3 3 3 | NA | fla3 | 无 | te | 313.0 / 10233.981 |
| dualpipev overlap | 16 | 4 | 3 4 4 4 3 4 4 4 | NA | fla3 | 无 | te | 304.2 / 7535.244 |
dualpipev 和 1f1b 的 loss 在单机脚本上 Loss 曲线对比如下:
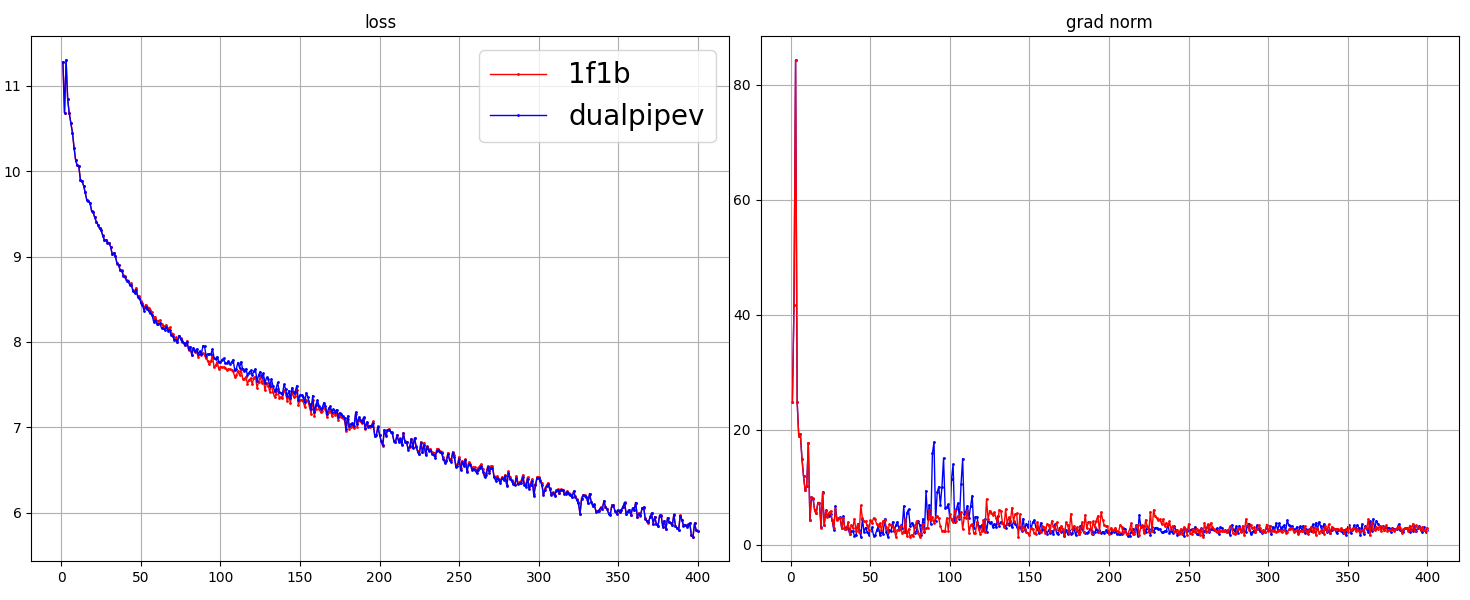
警告
测试过程中需要加载一致的 checkpoint。如果使用初始化 weight,不同的流水方式如 1f1b 和 dualpipev 的 loss 曲线会由于初始化 weight 不一致导致无法对齐 loss。
训练脚本
本节提供完整的训练脚本示例,帮助用户快速启动 DeepSeekV3-671B 和 Qwen3-235B 模型的训练。这些脚本包含了所有必要的配置参数和优化设置。
DeepSeekV3-671B 训练脚本
以下是 deepseekv3_671b.sh 的完整脚本内容:
#!/bin/bash
## 硬件相关环境设置
# CUDA
export CUDA_DEVICE_MAX_CONNECTIONS=32
export TORCH_NCCL_AVOID_RECORD_STREAMS=1
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export NVTE_BWD_LAYERNORM_SM_MARGIN=16
## 软件相关环境变量(python / pytorch / megatron)
export OMP_NUM_THREADS=10
export PYTORCH_ENABLE_SAME_RAND_A100=1
export MHA_BWD_NO_ATOMIC_F64=1
export MAX_JOBS=20
export PROJECT_PATH=${PROJECT_PATH:-/root/megatron-infinigence}
export PYTHONPATH=${PROJECT_PATH}:${PROJECT_PATH}/Megatron-LM:$PYTHONPATH:/workspace/flash-attention
export ARCH="NVIDIA_H100"
## 软件相关环境变量(python / pytorch / megatron)
##############
# Distributed training variables
NNODES=$NNODES
GPUS_PER_NODE=8
GPU_NUM=$((${GPUS_PER_NODE}*${NNODES}))
WORLD_SIZE=$((${GPUS_PER_NODE}*${NNODES}))
NODE_RANK=$NODE_RANK
MASTER_ADDR=${MASTER_ADDR:-localhost}
MASTER_PORT=${MASTER_PORT:-7000}
SEED=${SEED:-1234}
GROUP_GEMM=${GROUP_GEMM:-0}
GROUP_GEMM_TE=${GROUP_GEMM_TE:-0}
TD=${TD:-allgather_fused}
RECOMPUTE=${RECOMPUTE:-0}
CPU_ADAM=${CPU_ADAM:-0}
SCHED=${SCHED:-1f1b}
USE_FLASH3=${USE_FLASH3:-0}
## ORIG:
NUM_LAYERS=${NUM_LAYERS:-61}
HIDDEN_SIZE=7168
NUM_ATTN_HEADS=128
FFN_HIDDEN_SIZE=18432
MOE_FFN_HIDDEN_SIZE=2048
MAX_POSITION_EMBEDDINGS=163840
EXTRA_VOCAB_SIZE=467
RMS_NORM_EPS=1e-6
MAX_SEQ_LEN=4096
MAX_PAD_LEN=4096
MICRO_BATCH_SIZE=1
GLOBAL_BATCH_SIZE=${GLOBAL_BATCH_SIZE:-4096}
# mla
QK_NOPE_HEAD_DIM=128
QK_ROPE_HEAD_DIM=64
V_HEAD_DIM=128
ROPE_THETA=10000
SCALE_FACTOR=40
ORIG_MAX_POSITION_EMBEDDINGS=4096
Q_LORA_RANK=1536
KV_LORA_RANK=512
# moe
NUM_EXPERTS=${NUM_EXPERTS:-256}
ROUTER_TOPK=8
NUM_SHARED_EXPERTS=1
FIRST_K_DENSE_REPLACE=${FIRST_K_DENSE_REPLACE:-3}
## trains
TRAIN_TOKENS=1000000000
WARMUP_TOKENS=10000
TRAIN_ITERS=$(( ${TRAIN_TOKENS} / ${GLOBAL_BATCH_SIZE} / ${MAX_SEQ_LEN} ))
LR_WARMUP_ITERS=$(( ${WARMUP_TOKENS} / ${GLOBAL_BATCH_SIZE} / ${MAX_SEQ_LEN} ))
LR_DECAY_ITERS=$(( ${TRAIN_TOKENS} / ${GLOBAL_BATCH_SIZE} / ${MAX_SEQ_LEN} ))
LR=5e-6
MIN_LR=1e-6
# Paths
SRC_PATH=$PROJECT_PATH/megatron_infini/pretrain_deepseek.py
DATA_PATH=${DATA_PATH:-/workspace/datasets/DeepSeek-V3/deepseekv3_text_document}
TOKENIZER_PATH=/workspace/DeepSeek-V3
PARALLEL_PERFORMANCE_ARGS=" \
--bf16 \
--use-distributed-optimizer \
--sequence-parallel \
--transformer-impl transformer_engine \
--use-flash-attn \
--tensor-model-parallel-size ${TP} \
--tensor-model-parallel-for-expert ${TPE} \
--expert-model-parallel-size ${EP} \
--pipeline-model-parallel-size ${PP} \
--moe-token-dispatcher-type-patch ${TD} \
--mla-replicate-l1 \
--no-bias-swiglu-fusion \
"
if [ "$USE_FLASH3" -eq 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--module-impl {\"core_attn\":\"local\"} \
"
fi
if [ "$GROUP_GEMM" -eq 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--moe-grouped-gemm \
"
elif [ "$GROUP_GEMM_TE" -eq 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--moe-grouped-gemm-te \
"
fi
if [ -n "$FORCE_DROP_AND_PADDING" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--force-drop-and-padding \
"
fi
if [ -n "$VPP" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--num-layers-per-virtual-pipeline-stage ${VPP} \
"
fi
if [ "$CUDA_DEVICE_MAX_CONNECTIONS" -gt 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--no-async-tensor-model-parallel-allreduce \
"
fi
if [ "$SCHED" != "1f1b" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--scheduler ${SCHED} \
"
fi
if [ -n "$HPP" ]; then
if [ "$SCHED" == "1f1b" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--hetero-pipeline-stages $HPP \
"
else
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--virtual-hetero-pipeline-stages $HPP \
"
fi
fi
if [ "$RECOMPUTE" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--recompute-method uniform \
--recompute-num-layers 1 \
--recompute-granularity full \
"
elif [ "$MOE_LAYER_RECOMPUTE" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--moe-layer-recompute \
"
elif [ "$MLP_RECOMPUTE" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--mlp-recompute \
"
fi
if [ "$CPU_ADAM" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--optimizer hybridadam \
--optimizer-offload-policy static \
--optimizer-offload-fraction 1 \
--optimizer-enable-pin \
"
fi
if [ "$DP_OVERLAP" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--overlap-grad-reduce \
"
fi
MOE_ARGS=" \
--num-experts ${NUM_EXPERTS} \
--moe-router-topk ${ROUTER_TOPK} \
--moe-ffn-hidden-size ${MOE_FFN_HIDDEN_SIZE} \
--enable-shared-expert \
--num-shared-experts ${NUM_SHARED_EXPERTS} \
--first-k-dense-replace ${FIRST_K_DENSE_REPLACE} \
--moe-router-deepseekv3 \
--moe-router-score-function sigmoid \
--moe-router-enable-expert-bias True \
--moe-router-topk-scaling-factor 2.5 \
--moe-router-bias-update-rate 1e-3 \
--moe-aux-loss-coeff 1e-4 \
"
MLA_ARGS=" \
--q-lora-rank ${Q_LORA_RANK} \
--kv-lora-rank ${KV_LORA_RANK} \
--qk-nope-head-dim ${QK_NOPE_HEAD_DIM} \
--qk-rope-head-dim ${QK_ROPE_HEAD_DIM} \
--v-head-dim ${V_HEAD_DIM} \
--kv-channels ${V_HEAD_DIM} \
--qk-layernorm \
"
OTHER_NETWORK_ARGS=" \
--use-mcore-models \
--disable-bias-linear \
--patch-tokenizer-type DeepSeekTokenizer \
--tokenizer-model ${TOKENIZER_PATH} \
--extra-vocab-size ${EXTRA_VOCAB_SIZE} \
--max-padding-length ${MAX_PAD_LEN} \
--swiglu \
--normalization RMSNorm \
--norm-epsilon ${RMS_NORM_EPS} \
--use-rotary-position-embeddings \
--no-rope-fusion \
--position-embedding-type rope \
--untie-embeddings-and-output-weights \
--rotary-base ${ROPE_THETA} \
--rotary-scaling-factor ${SCALE_FACTOR} \
--rotary-seq-len-interpolation-factor 1 \
--rotary-mscale 1.0 \
--rotary-mscale-all-dim 1.0 \
--original-max-position-embeddings ${ORIG_MAX_POSITION_EMBEDDINGS} \
--rotary-beta-fast 32 \
--rotary-beta-slow 1 \
"
NETWORK_SIZE_ARGS=" \
--num-layers ${NUM_LAYERS} \
--hidden-size ${HIDDEN_SIZE} \
--num-attention-heads ${NUM_ATTN_HEADS} \
--ffn-hidden-size ${FFN_HIDDEN_SIZE} \
--max-position-embeddings ${MAX_POSITION_EMBEDDINGS} \
--seq-length ${MAX_SEQ_LEN} \
"
TRAINING_ARGS=" \
--micro-batch-size ${MICRO_BATCH_SIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--train-iters ${TRAIN_ITERS} \
--eval-interval 10000 \
--eval-iters 0 \
"
LEARNING_ARGS=" \
--lr ${LR} \
--min-lr ${MIN_LR} \
--lr-decay-style cosine \
--lr-decay-iters ${LR_DECAY_ITERS} \
--lr-warmup-iters ${LR_WARMUP_ITERS} \
--attention-dropout 0.0 \
--hidden-dropout 0.0 \
--weight-decay 0.1 \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--clip-grad 1.0 \
--init-method-std 0.008 \
--seed ${SEED} \
"
LOAD_SAVE_ARGS=" \
--no-load-optim \
--no-load-rng \
--num-workers 8 \
--no-save-optim \
"
if [ -n "$LOAD_PATH" ]; then
LOAD_SAVE_ARGS="$LOAD_SAVE_ARGS \
--load ${LOAD_PATH} \
"
fi
if [ -n "$SAVE_PATH" ]; then
LOAD_SAVE_ARGS="$LOAD_SAVE_ARGS \
--save ${SAVE_PATH}
"
fi
LOGGING_ARGS=" \
--log-interval 1 \
--log-throughput \
--save-interval 500 \
--timing-log-level 2 \
"
INTERVAL_ARGS=" \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters -1 \
"
DATASET_ARGS=" \
--num-workers 8 \
--data-path ${DATA_PATH} \
--split 99,1,0 \
--dataset LLama-Pretrain-Idxmap \
"
LAUNCHER=" \
torchrun \
--nproc_per_node ${GPUS_PER_NODE} \
--nnodes ${NNODES} \
--node_rank ${NODE_RANK} \
--master_addr ${MASTER_ADDR} \
--master_port ${MASTER_PORT} \
"
RUN_CMD="${LAUNCHER} ${SRC_PATH} \
${PARALLEL_PERFORMANCE_ARGS} \
${MIXED_PRECISION_ARGS} \
${MOE_ARGS} \
${MLA_ARGS} \
${OTHER_NETWORK_ARGS} \
${NETWORK_SIZE_ARGS} \
${TRAINING_ARGS} \
${LEARNING_ARGS} \
${LOAD_SAVE_ARGS} \
${LOGGING_ARGS} \
${INTERVAL_ARGS} \
${DATASET_ARGS} \
"
echo ${RUN_CMD}Qwen3-235B 训练脚本
以下是 qwen3-235b.sh 的完整脚本内容:
#!/bin/bash
## 硬件相关环境设置
# CUDA
export CUDA_DEVICE_MAX_CONNECTIONS=32
export TORCH_NCCL_AVOID_RECORD_STREAMS=1
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export NVTE_BWD_LAYERNORM_SM_MARGIN=16
## 软件相关环境变量(python / pytorch / megatron)
export OMP_NUM_THREADS=10
export PYTORCH_ENABLE_SAME_RAND_A100=1
export MHA_BWD_NO_ATOMIC_F64=1
export MAX_JOBS=20
export PROJECT_PATH=${PROJECT_PATH:-/root/megatron-infinigence}
export PYTHONPATH=${PROJECT_PATH}:${PROJECT_PATH}/Megatron-LM:$PYTHONPATH:/workspace/flash-attention
export ARCH="NVIDIA_H100"
## 软件相关环境变量(python / pytorch / megatron)
##############
# Distributed training variables
NNODES=$NNODES
GPUS_PER_NODE=8
GPU_NUM=$((${GPUS_PER_NODE}*${NNODES}))
WORLD_SIZE=$((${GPUS_PER_NODE}*${NNODES}))
NODE_RANK=$NODE_RANK
MASTER_ADDR=${MASTER_ADDR:-localhost}
MASTER_PORT=${MASTER_PORT:-7000}
SEED=${SEED:-1234}
GROUP_GEMM=${GROUP_GEMM:-0}
GROUP_GEMM_TE=${GROUP_GEMM_TE:-0}
TD=${TD:-allgather_fused}
RECOMPUTE=${RECOMPUTE:-0}
CPU_ADAM=${CPU_ADAM:-0}
SCHED=${SCHED:-1f1b}
## ORIG:
NUM_LAYERS=${NUM_LAYERS:-94}
HIDDEN_SIZE=4096
FFN_HIDDEN_SIZE=12288
EXTRA_VOCAB_SIZE=421
RMS_NORM_EPS=1e-5
MAX_SEQ_LEN=4096
MAX_PAD_LEN=4096
# gqa
NUM_ATTN_HEADS=64
NUM_KEY_VALUE_HEADS=4
# rope
MAX_POSITION_EMBEDDINGS=131072
ROPE_THETA=1000000
ROPE_PERCENT=1.0
# moe
MOE_FFN_HIDDEN_SIZE=1536
NUM_EXPERTS=${NUM_EXPERTS:-128}
ROUTER_TOPK=8
# bz
MICRO_BATCH_SIZE=${MICRO_BATCH_SIZE:-1}
GLOBAL_BATCH_SIZE=${GLOBAL_BATCH_SIZE:-4096}
## trains
TRAIN_TOKENS=1000000000
WARMUP_TOKENS=10000
TRAIN_ITERS=$(( ${TRAIN_TOKENS} / ${GLOBAL_BATCH_SIZE} / ${MAX_SEQ_LEN} ))
LR_WARMUP_ITERS=$(( ${WARMUP_TOKENS} / ${GLOBAL_BATCH_SIZE} / ${MAX_SEQ_LEN} ))
LR_DECAY_ITERS=$(( ${TRAIN_TOKENS} / ${GLOBAL_BATCH_SIZE} / ${MAX_SEQ_LEN} ))
LR=5e-6
MIN_LR=1e-6
# Paths
SRC_PATH=$PROJECT_PATH/megatron_infini/pretrain_qwen_moe.py
DATA_PATH=${DATA_PATH:-/workspace/datasets/Qwen3-30B-A3B/qwen3_text_document}
TOKENIZER_PATH=/workspace/Qwen3-30B-A3B
PARALLEL_PERFORMANCE_ARGS="
--bf16 \
--use-distributed-optimizer \
--sequence-parallel \
--transformer-impl transformer_engine \
--use-flash-attn \
--tensor-model-parallel-size ${TP} \
--tensor-model-parallel-for-expert ${TPE} \
--expert-model-parallel-size ${EP} \
--pipeline-model-parallel-size ${PP} \
--moe-token-dispatcher-type-patch ${TD} \
--use-local-multi-tensor-scale \
"
if [ "$GROUP_GEMM" -eq 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--moe-grouped-gemm \
"
elif [ "$GROUP_GEMM_TE" -eq 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--moe-grouped-gemm-te \
"
fi
if [ -n "$FORCE_DROP_AND_PADDING" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--force-drop-and-padding \
"
fi
if [ -n "$VPP" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--num-layers-per-virtual-pipeline-stage ${VPP} \
"
fi
if [ "$CUDA_DEVICE_MAX_CONNECTIONS" -gt 1 ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--no-async-tensor-model-parallel-allreduce \
"
fi
if [ "$SCHED" != "1f1b" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--scheduler ${SCHED} \
"
fi
if [ -n "$HPP" ]; then
if [ "$SCHED" == "1f1b" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--hetero-pipeline-stages $HPP \
"
else
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--virtual-hetero-pipeline-stages $HPP \
"
fi
fi
if [ "$RECOMPUTE" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--recompute-method uniform \
--recompute-num-layers 1 \
--recompute-granularity full \
"
elif [ "$MOE_LAYER_RECOMPUTE" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--moe-layer-recompute \
"
elif [ "$MLP_RECOMPUTE" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--mlp-recompute \
"
fi
if [ "$CPU_ADAM" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--optimizer hybridadam \
--optimizer-offload-policy static \
--optimizer-offload-fraction 1 \
--optimizer-enable-pin \
"
fi
if [ "$DP_OVERLAP" == "1" ]; then
PARALLEL_PERFORMANCE_ARGS="$PARALLEL_PERFORMANCE_ARGS \
--overlap-grad-reduce \
"
fi
MOE_ARGS=" \
--num-experts ${NUM_EXPERTS} \
--moe-router-topk ${ROUTER_TOPK} \
--moe-ffn-hidden-size ${MOE_FFN_HIDDEN_SIZE} \
--moe-router-topk-scaling-factor 2.5 \
--moe-aux-loss-coeff 1e-4 \
--moe-router-pre-softmax \
--cross-entropy-loss-fusion \
"
GQA_ARGS=" \
--group-query-attention \
--num-query-groups ${NUM_KEY_VALUE_HEADS} \
--num-attention-heads ${NUM_ATTN_HEADS} \
--add-qkv-bias \
"
OTHER_NETWORK_ARGS=" \
--use-mcore-models \
--disable-bias-linear \
--patch-tokenizer-type Qwen3Tokenizer \
--tokenizer-model ${TOKENIZER_PATH} \
--extra-vocab-size ${EXTRA_VOCAB_SIZE} \
--swiglu \
--normalization RMSNorm \
--norm-epsilon ${RMS_NORM_EPS} \
--use-rotary-position-embeddings \
--position-embedding-type rope \
--rotary-percent ${ROPE_PERCENT} \
--rotary-base ${ROPE_THETA} \
--rotary-emb-use-cache \
--max-position-embeddings ${MAX_POSITION_EMBEDDINGS} \
--untie-embeddings-and-output-weights \
"
NETWORK_SIZE_ARGS=" \
--num-layers ${NUM_LAYERS} \
--hidden-size ${HIDDEN_SIZE} \
--seq-length ${MAX_SEQ_LEN} \
"
TRAINING_ARGS=" \
--micro-batch-size ${MICRO_BATCH_SIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--train-iters ${TRAIN_ITERS} \
--eval-interval 10000 \
--eval-iters 0 \
"
LEARNING_ARGS=" \
--lr ${LR} \
--min-lr ${MIN_LR} \
--lr-decay-style cosine \
--lr-decay-iters ${LR_DECAY_ITERS} \
--lr-warmup-iters ${LR_WARMUP_ITERS} \
--attention-dropout 0.0 \
--hidden-dropout 0.0 \
--weight-decay 0.1 \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--clip-grad 1.0 \
--init-method-std 0.008 \
--seed ${SEED} \
"
LOAD_SAVE_ARGS=" \
--no-load-optim \
--no-load-rng \
--no-save-optim \
--no-save-rng \
"
if [ -n "$LOAD_PATH" ]; then
LOAD_SAVE_ARGS="$LOAD_SAVE_ARGS \
--load ${LOAD_PATH}
"
fi
if [ -n "$SAVE_PATH" ]; then
LOAD_SAVE_ARGS="$LOAD_SAVE_ARGS \
--save ${SAVE_PATH}
"
fi
LOGGING_ARGS=" \
--log-interval 1 \
--log-throughput \
--save-interval 500 \
--timing-log-level 2 \
"
INTERVAL_ARGS=" \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters -1 \
"
DATASET_ARGS=" \
--num-workers 8 \
--data-path ${DATA_PATH} \
--split 99,1,0 \
--dataset LLama-Pretrain-Idxmap \
"
LAUNCHER=" \
torchrun \
--nproc_per_node ${GPUS_PER_NODE} \
--nnodes ${NNODES} \
--node_rank ${NODE_RANK} \
--master_addr ${MASTER_ADDR} \
--master_port ${MASTER_PORT} \
"
RUN_CMD="${LAUNCHER} ${SRC_PATH} \
${PARALLEL_PERFORMANCE_ARGS} \
${MIXED_PRECISION_ARGS} \
${MOE_ARGS} \
${GQA_ARGS} \
${OTHER_NETWORK_ARGS} \
${NETWORK_SIZE_ARGS} \
${TRAINING_ARGS} \
${LEARNING_ARGS} \
${LOAD_SAVE_ARGS} \
${LOGGING_ARGS} \
${INTERVAL_ARGS} \
${DATASET_ARGS} \
"
echo ${RUN_CMD}