

关键概念
这里介绍在 AIStudio 中所提到的一些重要的概念。
算力市场
算力市场是智算云平台提供的一个灵活的计算资源租赁平台,用户可以根据实际需求按需购买和使用各种类型的算力资源。
在算力市场中,用户可以:
- 按需购买:根据项目需求选择合适的 GPU 型号、数量和使用时长
- 灵活计费:支持按小时、按天或包月等多种计费模式
- 资源多样化:提供从入门级到高端的各种 GPU 规格,满足不同场景的计算需求
- 即时可用:短期项目、实验验证、突发性计算需求场景下,可快速获取和释放计算资源,无需长期承诺
- 长期租赁:长期项目、稳定运行的场景下,可通过包月购买方式长期租用算力,获得更优惠的价格。
算力市场让用户能够更经济高效地使用 AI 计算资源,可在 AIStudio 开发机、任务(训练任务)、推理服务中使用。
开发机
开发机可以简单理解为一个挂载了 GPU 的 Linux 开发环境。创建开发机时,需要指定开发机的算力规格(CPU、内存、GPU)、选择镜像(可以理解为预装的 OS、开发环境和依赖项)、按需挂载共享高性能存储等。
开发机可用于训练代码的开发和调试,单机训练、也可以用于测试模型推理和部署。
任务
为了提高易用性和便捷性,AIStudio 支持从网页发起训练任务。您可以通过直观的用户界面进行操作,无需深入掌握复杂的命令行工具或编程环境。
在开发完代码需要进行训练时,可以通过网页界面分配计算资源,挂载共享存储获取代码、模型、数据,快速调整参数。
除了单机任务外,AIStudio 还支持一键发起大规模分布式训练(PyTorchDDP 和 MPI),并提供资源监控、自动容错、实时的训练日志和可视化等功能。
Worker
在训练任务中,「Worker」 是一个核心概念。在 AIStudio 的「任务」中,一个 Worker 通常指负责执行计算任务的最小计算单元(一个容器实例)。
在 AIStudio 创建任务时,需要指定 Worker 的数量以及单个 Worker 需要占用的算力规格,包括 CPU、内存和 GPU 型号和 GPU 数量。
推理服务
AIStudio 的推理服务,可快速便捷地将训练好的模型部署成线上服务,接入实际业务场景。
在服务运行过程中,可以通过 AIStudio 平台了解服务的健康情况,包括资源监控、业务指标监控、实例日志等。
根据服务的实时状况,用户可以按需选择对服务实例数进行扩缩容,或者通过升级功能变更服务的代码、推理框架、模型等。
实例
在推理服务中,实例通常指承载执行推理任务的最小计算单元(一个容器实例)。
在 AIStudio 创建任务时,需要指定实例数量以及单个实例需要占用的算力规格,包括 CPU、内存和 GPU 型号和 GPU 数量。
算力规格
算力规格定义了在 AIStudio 中运行容器实例的资源多少。目前 AIStudio 中仅提供 GPU 算力规格。
GPU 算力规格一般包含 1/2/4/8 个 GPU,可以利用深度学习框架的 GPU 版本加速深度学习模型的训练和推理。每种算力规格都提供了 CPU 核数和内存的上限。容器运行过程中一旦超过上限会导致任务的失败。
算力规格产品模块中名称略有区别。在创建开发机、任务、推理服务时,分别需要指定「规格」「Worker 规格」「实例规格」。
资源节点是算力资源的载体,算力规格则是对节点资源的逻辑划分。
注意
AIStudio 一般按 GPU 型号和 GPU 数量定义算力规格。每种 GPU 类型均提供 1、2、4、8 卡四种规格,配备固定的 CPU 核数和内存上限。AIStudio 仅支持按预定义的规格创建容器,不支持自由定义算力规格。
例如: 您的租户的算力资源为 NVIDIA A100 80G 显存 * 8,则表示该租户获得了使用 8 个 NVIDIA A100 的配额,可创建 8 个包含 1 个 GPU 的开发机。
镜像
指容器镜像,是一个用于创建和运行算力容器的模板,其中包含了运行算力容器所必要的环境和依赖,例如代码、运行时、库、环境变量、和配置文件等。
目前 AIStudio 提供了 PyTorch 官方镜像、NGC 官方镜像、CUDA 社区镜像、Ubuntu 基础镜像等,也支持用户构建自己的镜像。
更多内容请见镜像中心。
共享高性能存储
共享高性能存储是智算云平台平台提供的通用存储服务。在机器学习流程中,通常模型、数据集的规模都比较庞大,每次运行都重复上传代码和数据非常不现实。您可以使用购买共享高性能存储,作为 AIStudio 容器实例的扩展存储,用于持久化保存和复用数据。
开发机、任务的 Worker、推理实例均可挂载共享高性能存储,让您轻松地与团队成员共享文件,并在大数据量情况下高效地进行协作。
更多内容请见共享高性能存储。
文件系统
「文件系统」特指共享高性能存储中为租户分配的隔离的存储空间。
- 文件系统的大小决定了租户可用存储空间的上限(暂不支持展示大小)。
- 文件系统的可用区决定了存储可被挂载和使用的可用区,只有同一可用区实例(开发机、任务、推理服务、AICoder)可使用该文件系统提供的存储资源。
- 文件系统不可直接被实例挂载使用。拥有文件系统后,租户可自主创建存储卷。存储卷可被同一可用区实例(开发机、任务、推理服务、AICoder)挂载。
存储卷
在共享高性能存储中,「存储卷」指可被可用区实例(开发机、任务、推理服务、AICoder)挂载的存储单元。
存储卷有以下关键属性:
存储卷 ID: 用于识别存储卷,例如
vo-c7hp65uszhr7hb7x存储卷目录路径:在文件系统中,使用该路径划分存储卷使用的存储空间。例如,路径为
/public,表示使用该存储卷时限制操作在该文件系统/public目录下的数据。注意
- 在创建实例(开发机、任务、推理服务、AICoder)时,平台以存储卷 ID 与目录路径的组合来表示存储卷。例如: 您会在存储下拉列表中看到存储卷名称为
/datasets(vo-c7hp65utvgohcz2k)。 - 存储卷的目录路径仅表示其在文件系统上的位置,与实例容器内的访问目录无关。在挂载存储卷时,您可以将存储卷映射至容器内部的自定义路径。
- 在创建实例(开发机、任务、推理服务、AICoder)时,平台以存储卷 ID 与目录路径的组合来表示存储卷。例如: 您会在存储下拉列表中看到存储卷名称为
存储卷挂载权限:用于控制不同用户/用户组对存储卷可见性以及读写权限。如果用户对存储卷的权限与该用户所在用户组对存储卷的权限不同,则取并集。
容器内访问路径
「容器内访问路径」指在创建实例(开发机、任务、推理服务)时,将外部的存储卷挂载到容器内部文件系统中的具体目录路径。
- 作用:用户在容器内部(如终端、代码中)通过该路径访问存储卷中的数据。
- 自定义:用户可自定义该路径,但不能使用系统保留路径(如
/,/boot,/dev等)。 - 示例:将 ID 为
vo-db2mlm7jmq55l5kh,路径为/public的存储卷挂载到容器内的/mnt/public,则在容器内访问/mnt/public目录即访问该存储卷。
重要
关于 /mnt/public 的说明
文档中频繁出现的 /mnt/public 仅作为示例路径。平台不会默认自动创建或挂载此路径。
如果您希望在容器中使用 /mnt/public 访问共享存储,必须在创建实例(开发机、任务等)的「存储配置」步骤中,显式地将「挂载点」设置为 /mnt/public。如果您设置了其他路径(如 /mnt/data),则请在代码中使用 /mnt/data 访问数据。
资源规格
资源规格用于描述租户购买的计算资源配额。
例如,如果您的租户下单购买了 2 份以下包年包月计算资源规格:
- 资源规格编码:
g6l.111xlarge - 显卡型号 NVIDIA RTX4090-24G PCIe
- 显卡数量 8
- vCPU 核数 112
- 内存 896GB
注意
默认情况下,在租户购买包年包月资源时,仅支持按 8 卡资源规格购买配额(单个资源节点 8 卡),不支持按 1/2/4 卡购买资源配额。
那么,您的租户获得了使用最多同时使用 16 个 NVIDIA RTX4090 的配额。
- 如果使用 1卡的算力规格创建开发机,最多可同时创建并运行 16 台包含 1 个 GPU 的开发机。每台开发机的 GPU 核数为 14、内存为 112GB。
- 如果使用 8卡算力规格创建任务,最多可同时创建并运行 2 个包含 8 个 GPU 的开发机。
- 创建推理服务时,如果1卡的算力规格,使用 16 个实例,最多可同时运行 1 个推理服务。
您可以在资源池页面查看租户购买的算力资源配额、规格。
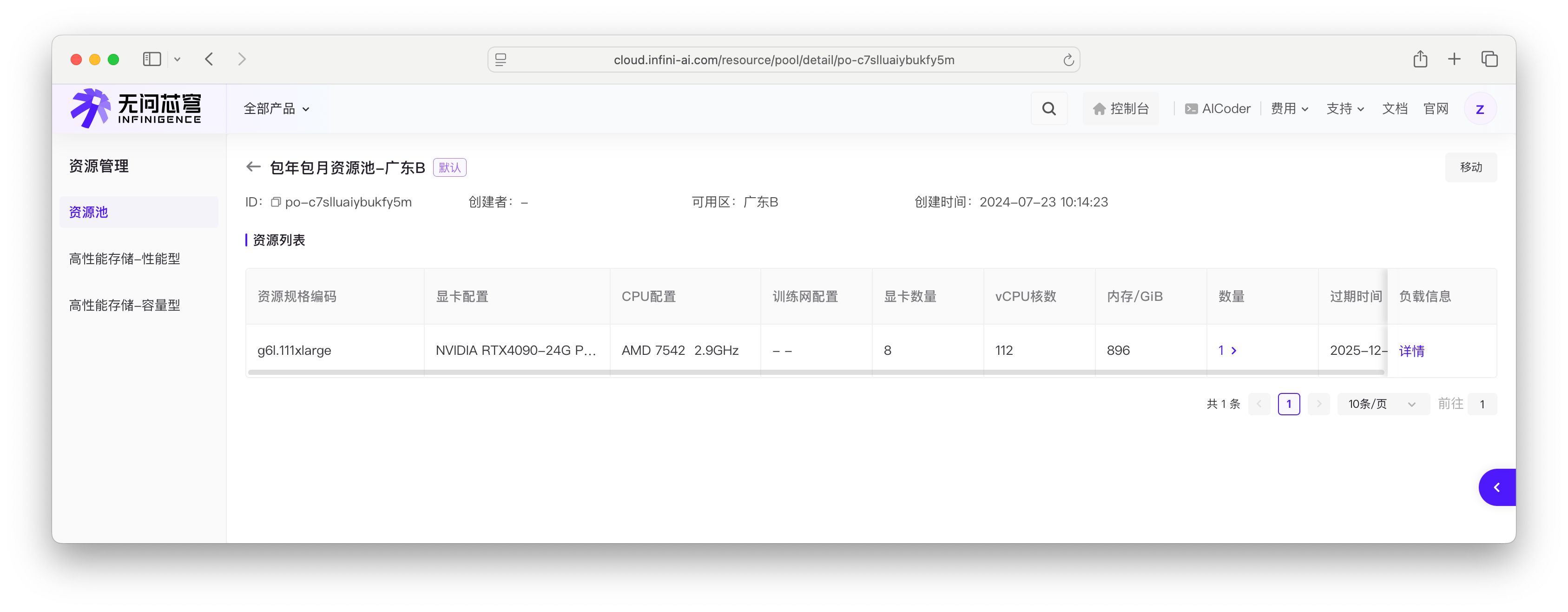
资源池
AIStudio 采用了「可用区」和「资源池」的概念组合,帮助租户管理云上的计算资源。
更多内容请见资源池。