

使用显存优化工具 STAlloc
我们在 Megatron-Infinigence 训练镜像中预置了显存优化工具 STAlloc。
该工具位于以下路径:
/workspace/memory_tools工具简介
STAlloc 是一款基于 PyTorch 的显存优化工具,可以有效降低模型训练中的显存碎片,适配多种训练框架如 Megatron-LM、DeepSpeed 和 Colossal-AI 等。
STAlloc 还可用于 Trace 模型训练时的显存,并得到详细的显存分析报告,帮助模型/框架开发人员快速判断当前任务是否合理,并快速定位框架代码中的异常点。
使用 STAlloc 优化模型训练的显存分配,Dense 模型可以达到 95% 左右的显存利用率;MoE 模型可以达到 90% 左右的显存利用率。这不仅可以使得一些原本 OOM 的训练任务可以顺利跑完,还可以将"节省"下来的显存用于尝试更快的训练配置。
使用说明
详细的使用说明文档位于:
/workspace/memory_tools/README.md工作模式
STAlloc 一共有三种模式:Torch、Trace 和 Alloc。
Torch 模式(默认)
STAlloc 在 Torch 模式下仅会在每个 Iteration 结束时打印每个 rank 的显存利用率信息,不做其它操作。
建议用户先用 Torch 模式执行 3 个训练 iteration,并判断:
- 是否 OOM
- 第二和第三个 iteration 输出的显存利用率是否较低
如果 OOM:尝试执行一遍 Trace 模式,并且不开启"Fast-Trace"开关,如果仍然 OOM,说明该训练配置不合理,需要更改训练配置。
对于"Torch 模式下 OOM 但 Trace 模式下能跑完"以及"Torch 模式下显示显存利用率较低"的情况,以及需要获取显存分析报告的情况,可以进一步执行 Trace 模式和 Alloc 模式。
Trace 模式
Trace 模式即抓取模型训练的显存行为。优化显存分配和得到显存分析报告都需要先执行一次 Trace 模式。
在 Trace 模式下,将训练脚本中的 train-iter 设置为 3,eval-iter 设置为 1。
Alloc 模式
在执行完一次 Trace 后,执行相关命令得到显存分配方案,然后再将 STAlloc 改为 Alloc 模式启动模型训练任务。
需要保证 Trace 模式和 Alloc 模式下执行的训练脚本一致,即训练任务配置一致。
脚本配置和代码修改
训练脚本配置
需要在训练脚本中添加以下内容。如果是 Trace 模式,需要设置 train-iter=3,eval-iter=1。
# 设置 STALLOC_DIR 为 memory_tools 的上一级目录,并加入到 PYTHONPATH 中
STALLOC_DIR=YourPath
export PYTHONPATH=${PYTHONPATH}:${STALLOC_DIR}
# 配置 STAlloc 相关环境变量
export STALLOC_MODE=Alloc # 三种模式可选 [Torch, Trace, Alloc]
export STALLOC_TRACE_FAST_MODE=1 # 在 Trace 模式下可以开启 Fast-Trace,加速 Trace 速度
export STALLOC_DYNAMIC=0 # 当训练 MoE 模型时设置为 1
export STALLOC_LOG_LEVEL=1 # LOG 级别
export STALLOC_LIB_PATH=${STALLOC_DIR}/memory_tools/Allocator
# 配置显存信息保存路径
MODEL_TAG=llama3-70b-tp8pp8mbs1gbs128-node${RANK} # 多机训练时,每台机器保存一份显存信息
MEMORY_SAVED_DIR=/workspace/allocator_case
export STALLOC_MODEL_INFO_PATH=${MEMORY_SAVED_DIR}/${MODEL_TAG}
if [ "$STALLOC_MODE" == "Trace" ]; then
if [ -e "${STALLOC_MODEL_INFO_PATH}/trace" ]; then
rm -rf ${STALLOC_MODEL_INFO_PATH}/trace
fi
mkdir -p ${STALLOC_MODEL_INFO_PATH}/trace
mkdir -p ${STALLOC_MODEL_INFO_PATH}/log_output
elif [ "$STALLOC_MODE" == "Alloc" ]; then
if [ ! -e "${STALLOC_MODEL_INFO_PATH}/output/plan" ]; then
exit 1
fi
fipretrain*.py 修改
修改的 Python 文件为训练入口,例如 pretrain_gpt.py。需要在其最开始处 import 相关函数,如果 import 位置靠后可能导致显存分配器加载失败。
# Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
"""Pretrain GPT."""
from memory_tools.utils.hook_model import hook_memory_model
def model_provider(...):
...
#return model
return hook_memory_model(model, args)apply_patcher.py 修改
如果使用 megatron-infinigence 进行训练,则另外需要修改 megatron-infinigence/megatron_infini/apply_patcher.py 的 add_and_apply_all_patch_in_target_module() 函数,新增以下内容:
def add_and_apply_all_patch_in_target_module():
# ...
import os
if os.getenv("STALLOC_MODE") != None:
from memory_tools.utils.memory_patcher import add_STAlloc_patch_for_infini
add_STAlloc_patch_for_infini()
# ...环境变量说明
| 环境变量 | 取值 | 说明 |
|---|---|---|
STALLOC_MODE | [Torch (default), Trace, Alloc] | 设置 STAlloc 的模式 |
STALLOC_LIB_PATH | STAlloc 库路径 | 当 STALLOC_MODE 为 Trace 或 Alloc 时必需 |
STALLOC_MODEL_INFO_PATH | 模型显存信息保存路径 | 当 STALLOC_MODE 为 Trace 或 Alloc 时必需 |
STALLOC_DYNAMIC | [0 (default), 1] | MoE 模型(不使用 batchgemm)时,当 STALLOC_MODE 为 Trace 或 Alloc 时必需 |
STALLOC_LOG_LEVEL | [0, 1, 2, 3 (default)] | 设置 STAlloc 的日志级别,数值越小输出内容越详细 |
STALLOC_STATIC_FALLBACK | [0 (default), 1] | 启用静态分配的回退机制,会影响性能 |
STALLOC_TRACE_FAST_MODE | [0 (default), 1] | 使用更快的动态分配器进行 trace,但当模型所需显存达到 GPU 限制时可能导致 OOM |
分析显存和生成显存分配方案
Step 1 确保 Trace 成功
首先确保 Trace 模式执行成功。
Step 2 安装 Synthesizer
cd YourPath/memory_tools/Synthesizer
pip install synthesizer-0.0.1-cp312-cp312-linux_x86_64.whl
python run.py --helpStep 3 分析显存行为
仅分析显存行为,不生成分配方案:
python run.py --model-memory-dir=${STALLOC_MODEL_INFO_PATH} --trace-only --device=0参数说明:
${STALLOC_MODEL_INFO_PATH}即为训练脚本中的同名路径- 显存分析报告保存路径为
${STALLOC_MODEL_INFO_PATH}/output/trace_analysis --trace-only表示只生成显存分析报告--device=0表示生成具体 device 的信息;替换为--devices=8会并行执行 device0~device7 的分析
Step 4 生成显存分配方案
去掉 --trace-only 参数:
python run.py --model-memory-dir=${STALLOC_MODEL_INFO_PATH} --device=0注意
- 当模型较大时,生成显存分配方案可能需要几分钟时间
- 生成显存分配方案后,可以再次执行训练脚本,并将
STALLOC_MODE设置为Alloc
使用示例
以下示例展示了在 LLaMA2-7B 模型上使用显存优化工具的完整流程。
配置信息
- 模型:LLaMA2-7B
- 硬件:单机八卡
- 并行策略:tp4pp1dp2
- 微批次大小:msb4
- 全局批次大小:gbs128
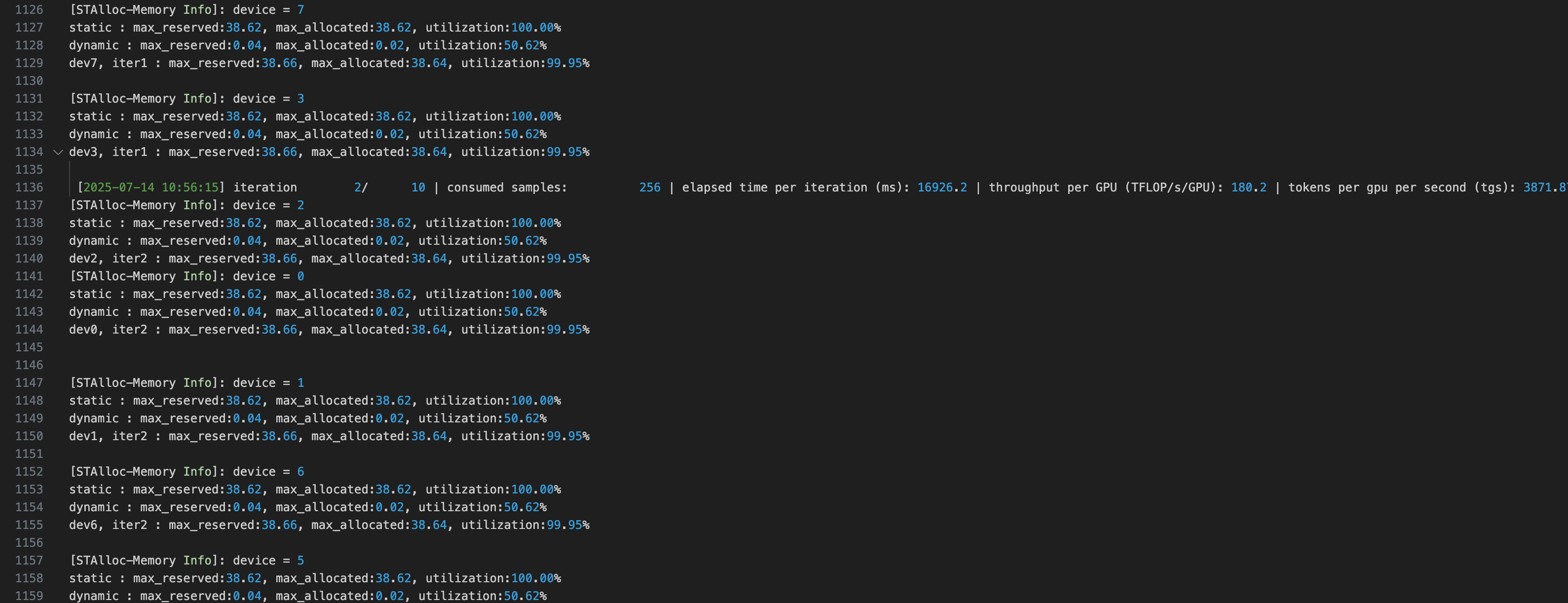
Step 1 使用 Torch 原生显存分配器训练
首先使用 Torch 原生显存分配器进行基准训练:显存利用率:82%
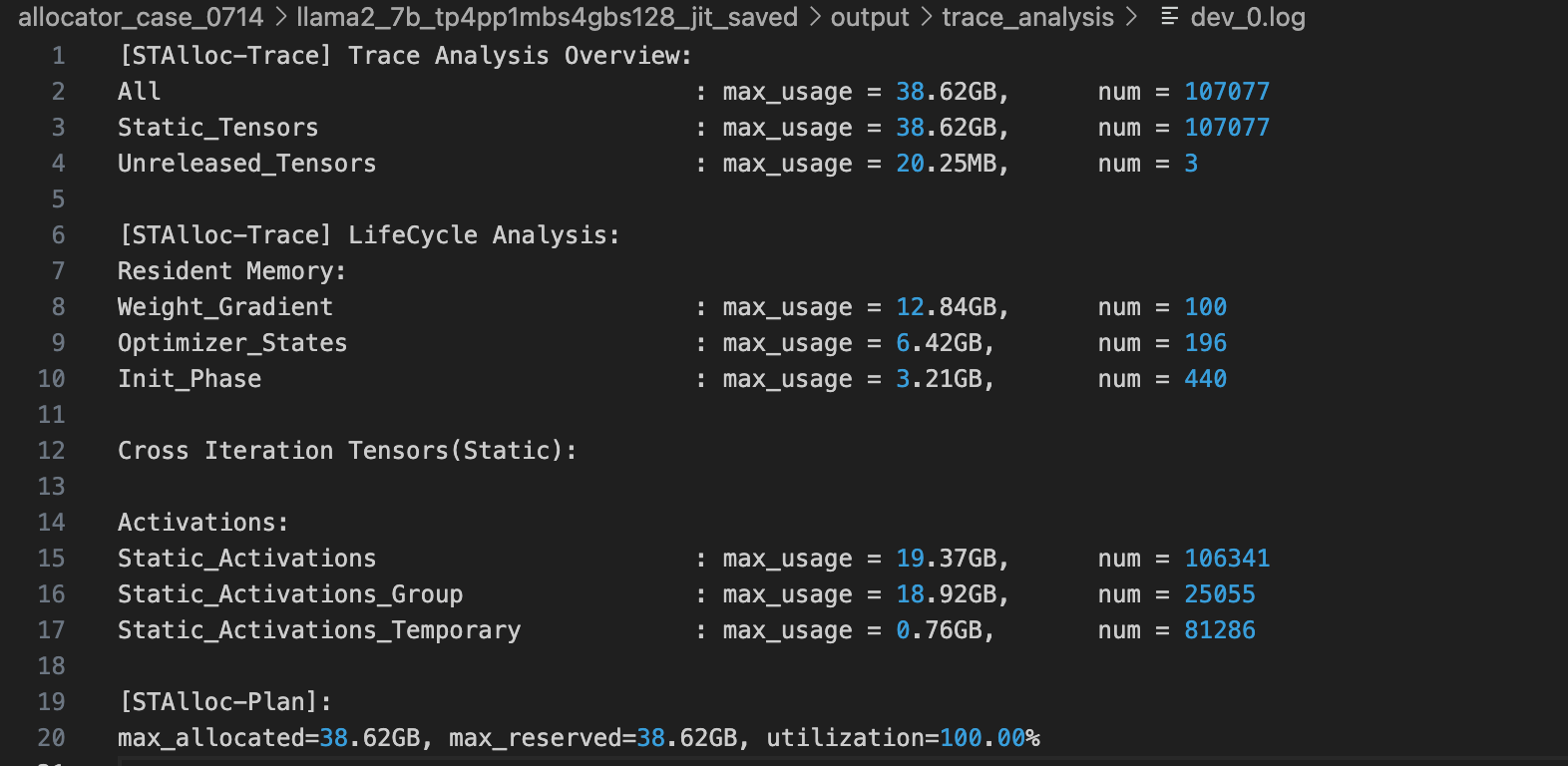
Step 2 使用 Trace 模式分析显存行为
使用 Trace 模式抓取显存分配行为并进行分析:
- 使用显存工具的 Synthesizer 模块进行分析,具体使用方法参考 README.md
- 显存分析报告主要信息:
- 理论峰值显存:38.62 GB
- 模型权重大小:12.84 GB
- 优化器状态大小:6.42 GB
- 激活值显存:19.37 GB
- 生成显存分配方案,理论最大显存使用量为 38.62 GB,理论显存利用率为 100%
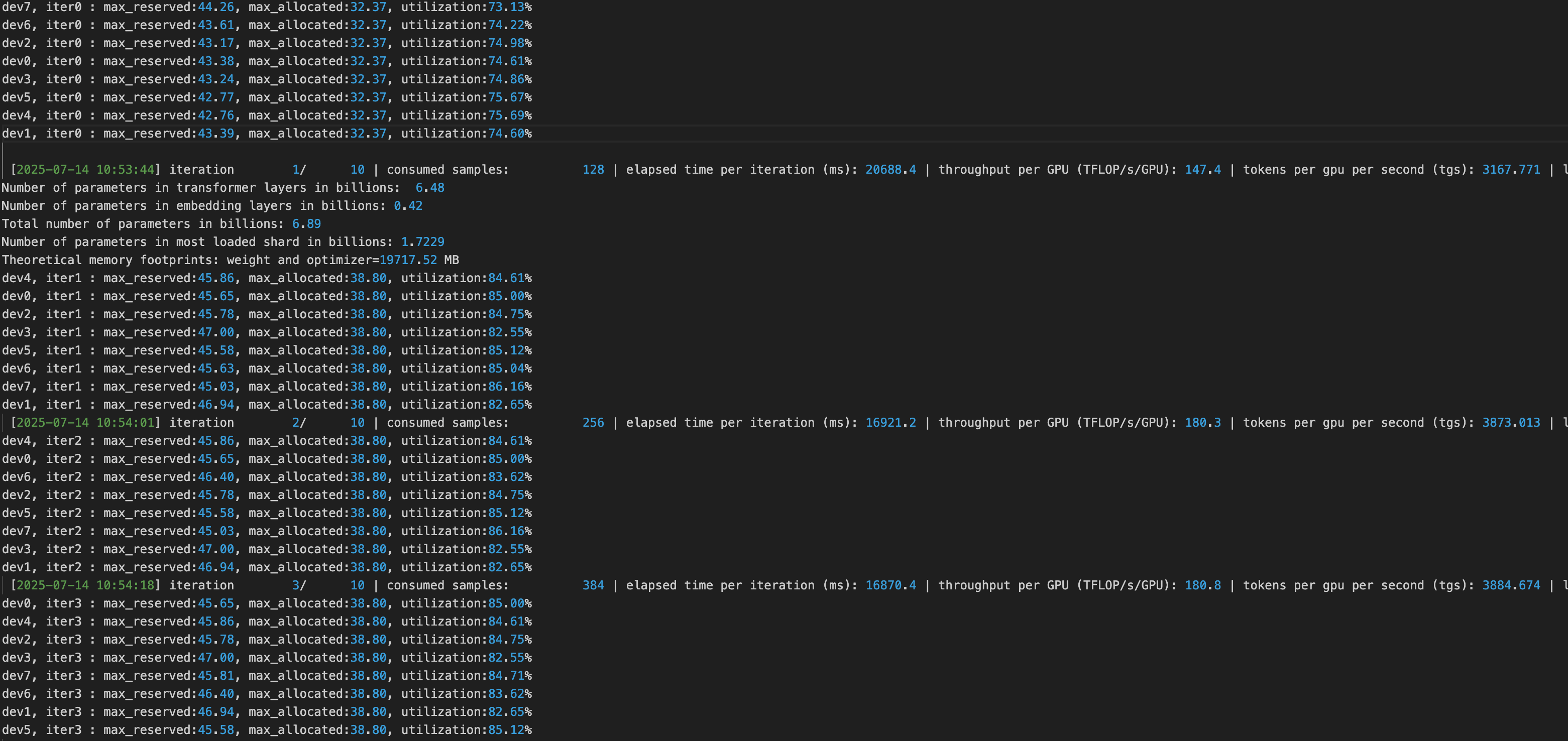
Step 3 使用 Alloc 模式进行优化训练
应用生成的显存分配方案进行模型训练:
- 每轮训练结束后,每个设备都会输出当前的显存状态
- 对比 Torch 原生显存分配器,显存利用率从 82% 提升至 99.95%
- 训练速度不受影响
性能提升
通过使用显存优化工具,可以实现:
- 显存利用率提升:从 82% 提升至 99.95%
- 训练效率保持:训练速度不受影响
- 资源优化:更高效地利用 GPU 显存资源
补充说明
其他框架适配
memory_tools/utils 中的代码可以将显存工具的 hooks 等 patch 到 megatron 框架中。
如果需要在其它训练框架上使用显存工具,例如 Colossal-AI,需要手动增加相关 hook。
其他框架上的 patch
参考 memory_tools/utils/memory_patcher.py:
- patch
train_step()方法:在 Trace 模式下,需要在train_step()执行前后往显存记录文件中写入 Iteration 相关信息 - patch
evaluate()方法:在 Alloc 模式下,需要在进入和退出时分别 evaluate() 调用STAllocConfig.checkpoint() - patch
forward_step和backward_step:在进入对应方法前往显存记录文件中写入 micro-batch 信息 - patch
report_memory:在 Trace 和 Alloc 模式下不能调用torch.cuda.max_memory_reserved()等 API
megatron-infinigence 特殊说明
如果使用 megatron-infinigence 并且使用了 megatron-infini 中的 schedulers,可能会在 Trace 时拿不到 micro-batch 信息,此时需要参考上述第三点,需要 patch megatron-infini 中对应 scheduler 的 forward_step 和 backward_step。
常见问题
Trace 完成后的检查
Trace 完成后,会在对应设置的目录下生成 memlog.txt,检测 memlog.txt 正确性:
- 有
Iteration Index :字符,并且 Index 范围为 0~End。如果没有,则检查当前框架的train_step()方法是否被正确 patch - 有
micro-batch : F和micro-batch : B字符。如果没有,则检查当前框架的forward_step和backward_step方法是否被正确 patch - 如果是 MoE 模型,还应该有
Layer字符。如果没有:- 检查是否在
pretrain*.py中修改了 model_provider() 的返回值为return hook_memory_model(model, args) - 检查是否在训练脚本中设置
export STALLOC_DYNAMIC=1 - 参考
memory_tools/utils/hook_model.py,根据 model 结构修改 hook 中抓取对应层的判定
- 检查是否在
API 调用错误
Trace 或者 Alloc 过程中遇到调用 torch.cuda.max_memory_reserved() 等系列 API 导致的报错:注释掉这些 API 的调用。
Triton 算子问题
基于较高版本的 torch 环境跑 Megatron 训练,运行显存工具可能会遇到 Triton 生成的算子内部调用了 torch.cuda.max_memory_allocated() 等 API。需要将 Megatron-LM/megatron/core/jit.py 中的 jit_fuser 设置为 torch.jit.script。