

推理服务资源与事件监控
AIStudio 推理服务监控可提供服务整体与实例级别的资源使用情况。如果使用指定预置镜像,还可以获取推理业务的性能表现、和流量变化等指标。
服务级监控
进入推理服务的详情页,可以切换到服务监控标签页,查看推理服务各个实例的资源使用情况。
推理服务级监控指标分为以下标签展示:
- 资源监控:适用于所有推理服务,反映推理服务的显卡、显存、内存、CPU 的使用情况。
- 业务监控:适用于选择了「特定预置镜像」的推理服务,提供每秒请求数、流量等推理业务通用指标。
- 存储监控:指推理服务实例系统盘(rootfs)的存储用量、性能监控指标。
- 文件存储监控:指推理服务实例挂载的共享存储的性能监控指标。
- LLM 场景业务监控:已适配 SGLang 和 vLLM 推理引擎。详见 LLM 场景业务监控。
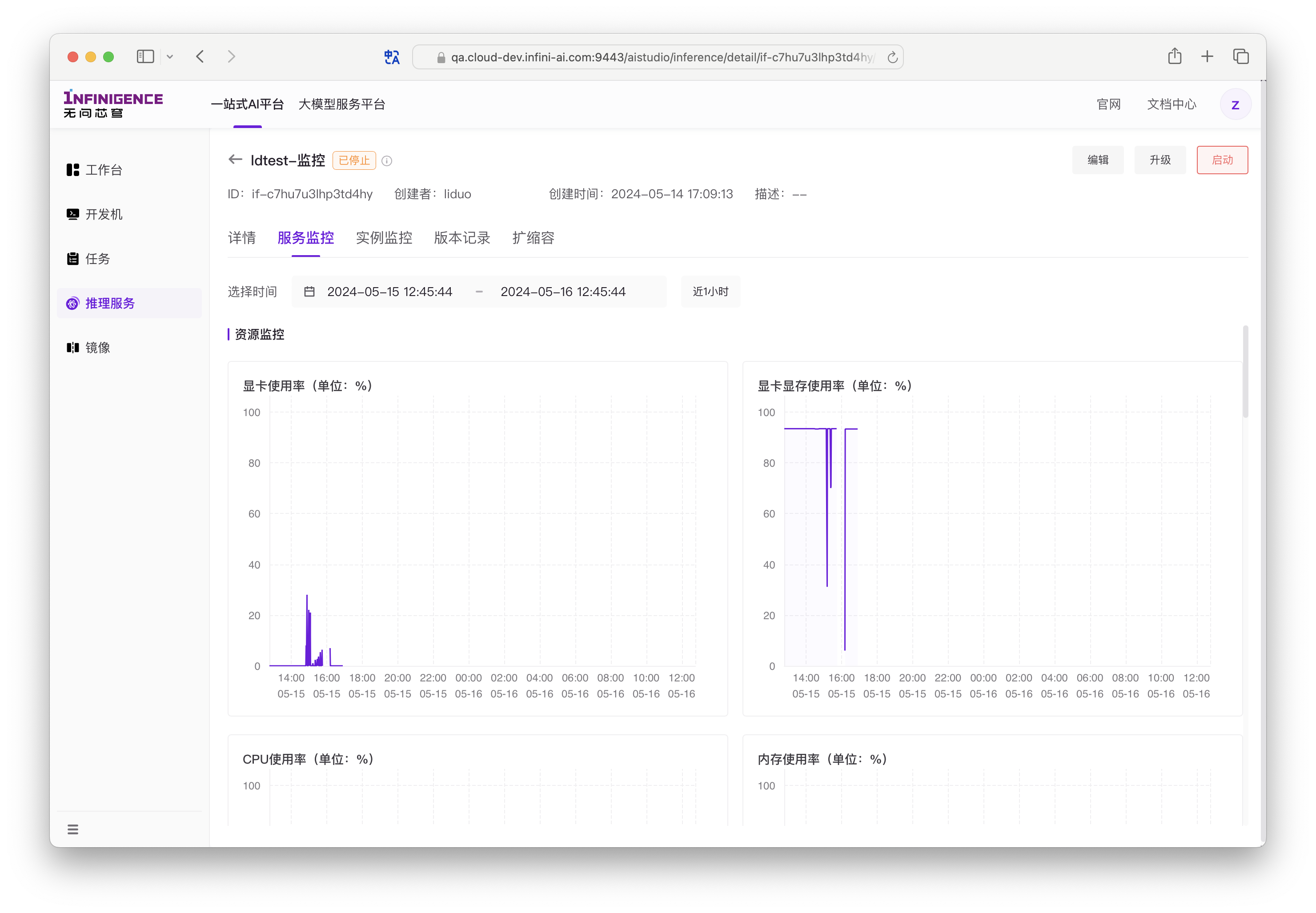
推理服务资源监控指标
默认每 30 秒获取一次数据。在监控指标图表展示时,平台会根据所选择的时间范围动态调整数据聚合粒度。
- 显卡使用率 %:推理服务的显卡使用率(所有实例的平均值)
- 显卡显存使用率 %:推理服务的显卡显存使用率 %(所有实例的平均值)
- CPU 使用率 %:推理服务的 CPU 使用率 %(所有实例的平均值)
- 内存使用率 %:推理服务的内存使用率 %(所有实例的平均值)
- 运行中实例数量
通用推理业务监控指标
默认每 30 秒获取一次数据。在监控指标图表展示时,平台会根据所选择的时间范围动态调整数据聚合粒度。
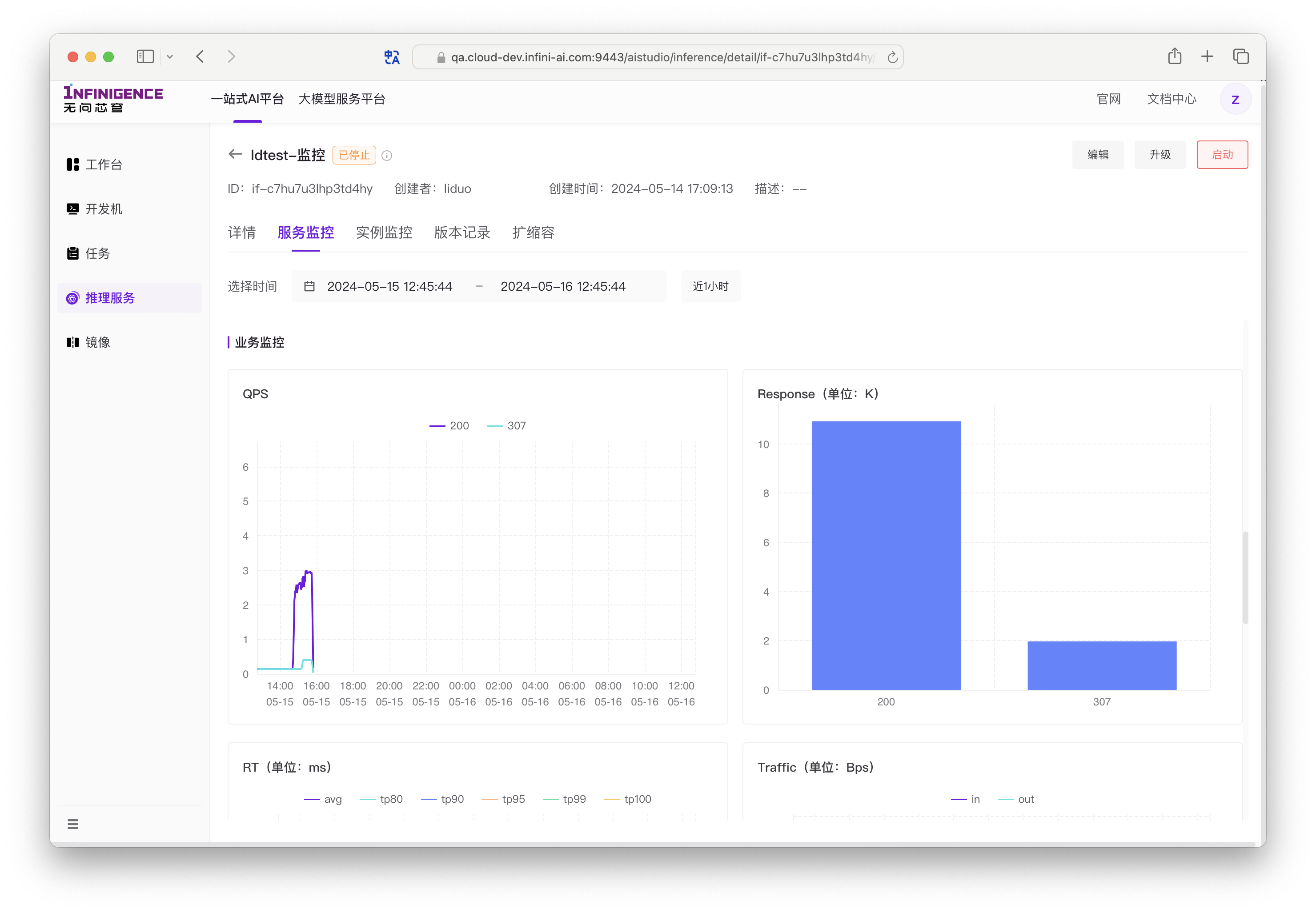
QPS:每秒的请求数,按请求的 HTTP 返回码分类,在折线图中展示多条折线(所有实例的平均值)
Response:请求总数,按请求的 HTTP 返回码分类,在直方图中展示各种 HTTP 返回码对应的请求总数量(所有实例的平均值)
RT:请求的响应时间指标,包括平均响应时间和各个百分位数的响应时间(所有实例的平均值)
- avg:所有请求的平均响应时间(每段时间请求响应总时间/相应总数)
- tp80,tp90,tp95,,tp99,tp100:Top 百分位数,表示在时间范围(单位:ms)内完成响应的请求百分比。tp80 为 40 ms,表示响应速度前 80% 的请求在 40 ms 内完成。如果服务包含多个实例,tp 取所有实例的平均值。
Traffic:服务接收和发出的流量大小,单位为字节每秒(所有实例的平均值)
推理服务存储资源监控指标
推理服务的存储监控由实例(Worker)级别存储监控指标聚合产生,分为两部分:
- 存储监控:指系统盘(rootfs)
- 文件系统监控:指挂载的高性能文件存储
您可以通过存储监控指标直观地排查推理服务实例系统盘(rootfs)写满、存储读写性能异常等常见问题。
| 推理服务监控指标 | 描述 |
|---|---|
| 磁盘用量 | 系统盘(rootfs)的容量占用情况。 |
| 磁盘读数据量 | 在单位时间内对系统盘的读取数据量,单位 MiB。 |
| 磁盘写数据量 | 表示在单位时间内对系统盘写的数据量,单位 MiB |
| 文件存储读速度 | 该负载挂载共享存储,在运行期间读带宽监控,单位 MiB/s |
| 文件存储写速度 | 该负载挂载共享存储,在运行期间写带宽监控,单位 MiB/s |
| 文件存储读IOPS | 该负载挂载共享存储,在运行期间单位时间内读取文件次数,单位 次/s |
| 文件存储写IOPS | 该负载挂载共享存储,在运行期间单位时间内写入文件次数,单位 次/s |
| 文件存储读时延 | 发起读取文件到完成操作的时间(平均),单位为 ms |
| 文件存储写时延 | 发起写入文件到完成操作的时间(平均),单位为 ms |
LLM 场景业务监控
该标签页用于展示从 SGLang 和 vLLM 推理引擎直接采集的指标。
使用该功能需要推理服务满足以下要求:
- 推理服务使用 vLLM/SGLang(预置镜像或自定义镜像均可)
- SGLang 需要启用 Production Metrics 输出功能
- 创建推理服务时,已配置监控端口
详见 LLM 场景业务监控。
实例级监控
进入推理服务的详情页,可以点击实例监控,查看推理服务各个实例的资源使用情况。
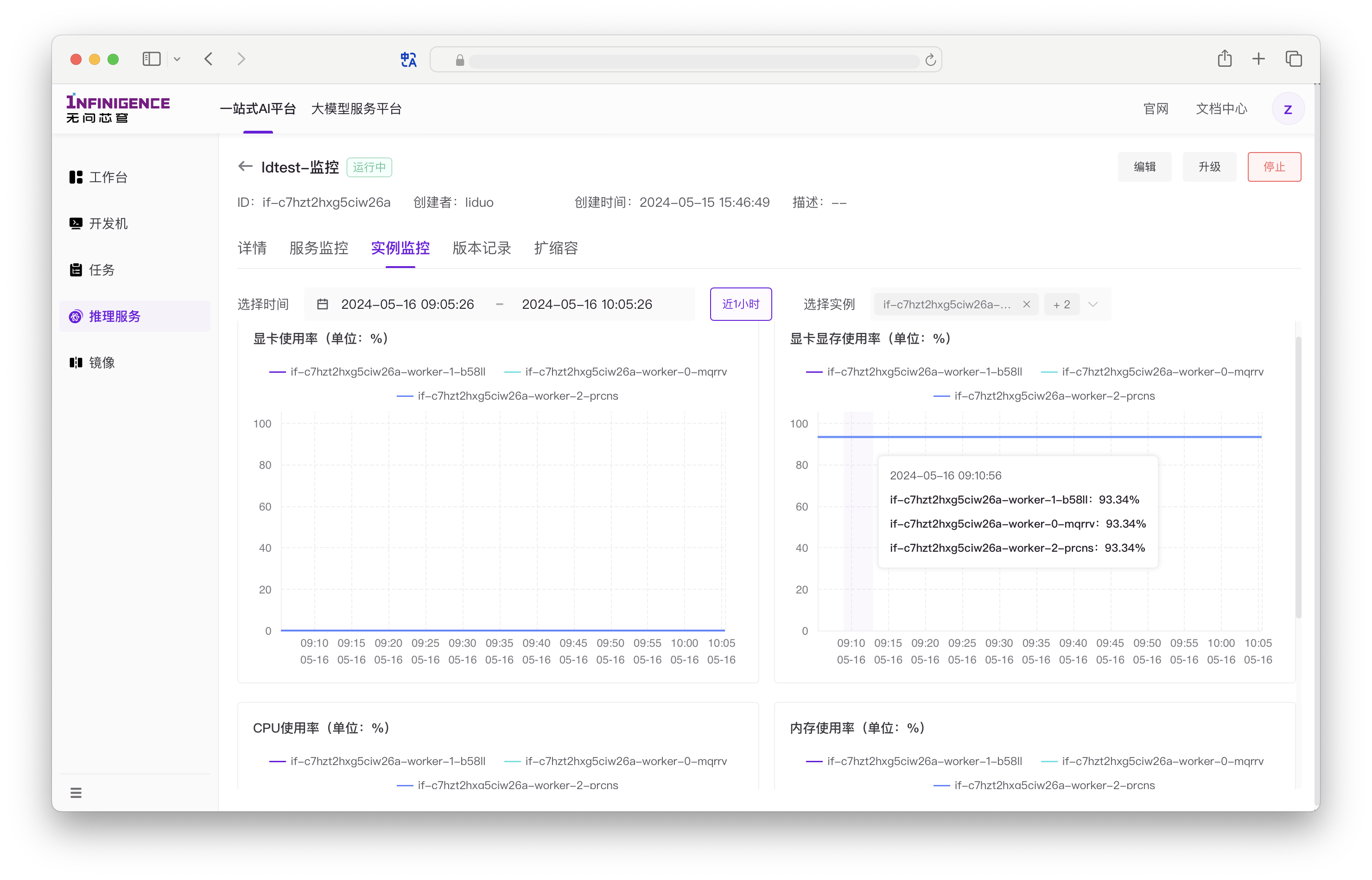
默认每 30 秒获取一次数据。在监控指标图表展示时,平台会根据所选择的时间范围动态调整数据聚合粒度。
实例资源监控指标
- 显卡使用率
- 显卡显存使用率
- CPU 使用率
- 内存使用率
信息
资源监控指标的使用率:实例的资源实际用量 / 实例所使用的资源规格的资源分配量。
实例网络监控指标
| 推理服务实例网络监控指标 | 描述 |
|---|---|
| RDMA 接收数据量 | 指定实例(worker) 的 RDMA 接收数据量(MB) |
| RDMA 发送数据量 | 指定实例(worker) 的 RDMA 发送数据量(MB) |
| 网络接收数据量 | 指定实例(worker) 的网络接收数据量(MB) |
| 网络发送数据量 | 指定实例(worker) 的网络发送数据量(MB) |
实例存储监控指标
推理服务实例级别存储监控指标分为两部分:
- 存储监控:指系统盘(rootfs)
- 文件系统监控:指挂载的高性能文件存储
| 推理服务实例存储监控指标 | 描述 |
|---|---|
| 磁盘读取数据量 | 指定实例(worker) 的系统盘内读取数据量(MiB) |
| 磁盘写入数据量 | 指定实例(worker) 的系统盘写入数据量(MiB) |
| 文件存储写入数据量 | 指定实例(worker) 对指定文件存储的写入数据量(MiB) |
| 文件存储读取数据量 | 指定实例(worker) 对指定文件存储的读取数据量(MiB) |
事件监控
智算云平台会记录推理服务在生命周期中的所有事件。
访问详情页面,点击「事件记录」标签页,用于展示负载操作事件,包括事件 ID、事件名称、操作者用户名、事件发生时间等,支持筛选,方便用户追踪自己或他人对当前负载的操作记录。事件记录只保留 30 天。
节点侧硬件与环境类异常,可在详情页通过 服务告警 标签查看当前及历史记录(需申请开通)。详见服务告警 (Unavailable in this edition)。