

使用进程栈采集功能
AIStudio 训练服务提供进程栈采集功能,帮助您诊断任务挂起和性能问题。该功能可在任务挂起时自动采集进程栈数据,或在任务运行中手动触发采集,为分布式训练调试提供详细的执行状态信息。
前提条件
使用进程栈采集功能需要满足以下要求:
- 任务处于运行状态:任务必须正在执行才能采集进程栈数据。
- 开启 Hang 检测(自动采集):如需在任务挂起时自动采集进程栈,必须先在容错配置中开启 Hang 检测功能。
- 了解任务特征:建议了解您的训练框架和代码结构,以便更好地解读进程栈信息。
开启进程栈采集
通过任务配置,您可以在任务 Hang 时自动采集进程栈。即使关闭自动采集,仍可手动采集。推荐在生产环境或历史上出现过挂起问题的任务中开启。
配置自动采集
在创建任务、改配任务、克隆任务时,均可配置自动采集进程栈。
- 在容错配置区域,开启 Hang 检测功能。
- 在进程栈采集配置区域,将开关切换为开启状态。
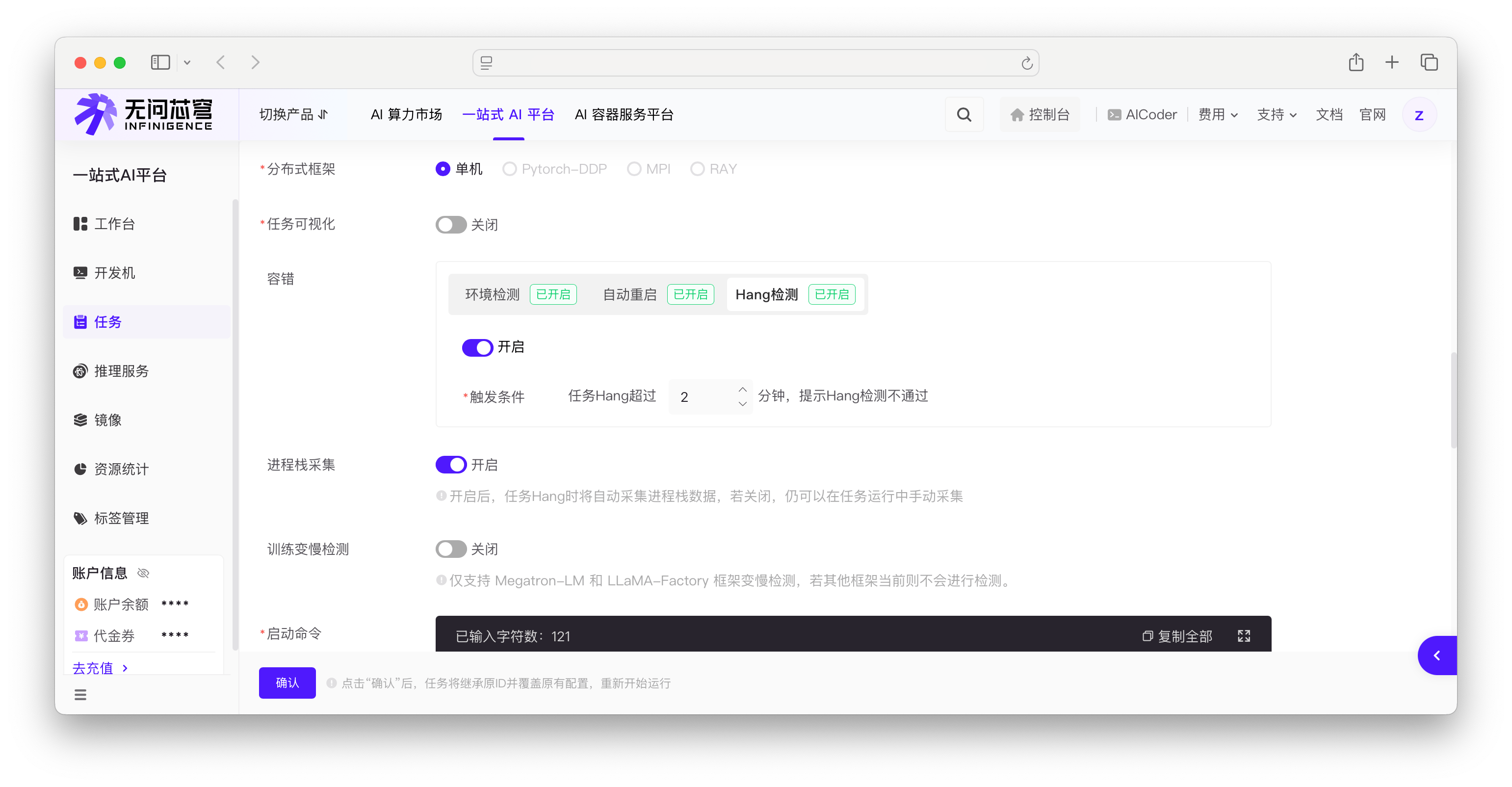
警告
进程栈采集配置区域仅在容错配置区域的 Hang 检测功能开启后可用。
手动采集进程栈
无论是否开启自动采集,都可在任务运行中手动触发采集。
- 进入任务详情页
- 点击进程栈采集标签
- 点击手动采集按钮
- 等待采集完成(通常几秒到几十秒)
适用于性能分析、问题诊断或对比不同时间点的执行状态。
查看进程栈采集结果
进程栈采集数据保存在任务详情页的进程栈采集标签中,保留 30 天。

该标签包含三个子标签:
- 报告:以 Markdown 呈现的栈分析摘要与函数调用统计表(覆盖整个任务所有 Worker / rank 的聚合结果)
- 进程栈:原始进程栈跟踪数据(按线程组织的结构化数据)
- NCCL 状态:NCCL 通信状态信息(如适用)
查看报告
报告标签展示 Stack Trace Analysis Report:先给出任务级摘要,再以 Markdown 表格列出函数调用统计,便于阅读、复制和与同事分享。一次采集的报告聚合整任务范围,无需在多个 Worker 之间分别打开即可对比各 rank 上的热点符号。
报告结构说明
典型章节如下(标题与字段以控制台为准):
Summary(摘要)
- Job ID:任务 ID
- Analysis Time:分析时间(UTC)
- Print ID:本次报告打印 ID,便于与平台支持沟通时引用
Function Call Statistics(函数调用统计)Markdown 表格一般包含三列:
列名 含义 Function Name 符号名称及路径提示:可为 Python 源码位置,也可为 C++ 标准库、PyTorch / CUDA 等动态库中的符号,便于区分用户代码与底层库 Call Count 该符号在统计中的调用次数(聚合后的计数) Sources 该符号出现在哪些 Worker / rank 上;常附带各来源上的计数,例如 worker-rank0 (3), worker-rank1 (3)
表格通常按调用热度排序,方便快速定位最频繁的等待、同步或计算路径。
报告示例(节选)
以下为真实输出形式的节选,仅用于说明版式与内容类型:
Stack Trace Analysis Report
## Summary
- **Job ID**: `jo-dcpihjb32vcheeso`
- **Analysis Time**: `2026-03-20 09:57:19 (UTC)`
- **Print ID**: `1774000631934257167`
## Function Call Statistics
| Function Name | Call Count | Sources |
| --- | ---: | --- |
| `select /usr/lib/python3.12/selectors.py:415` | 24 | infiniai-a19-rank0 (3), infiniai-a19-rank1 (3), … |
| `std::condition_variable::wait /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.33:0` | 64 | infiniai-a19-rank0 (8), infiniai-a19-rank1 (8), … |
| `pretrain /mnt/public/.../megatron/training/training.py:801` | 8 | infiniai-a19-rank0, infiniai-a19-rank1, … |完整报告中的行数较多,可在控制台内滚动查看,或使用复制将整份 Markdown 粘贴到本地编辑器、工单或文档中留存、对比。
查看进程栈详情
进程栈标签显示每个进程的原始栈跟踪信息,包含 Python 调用栈;在支持的环境下还可呈现 C++ 动态库等原生代码相关的栈帧,便于定位扩展模块与底层库中的阻塞点。
筛选和查看进程栈
进程栈标签支持按 Worker 和 GPU 筛选进程:
- 在进程栈标签中,使用下拉菜单或筛选器选择特定的 Worker 和 GPU
- 例如:选择
worker-0-gpu-0查看该 GPU 对应进程的栈跟踪 - 可以逐个查看不同 Worker 和 GPU 的进程栈,对比不同进程的执行状态
进程栈原始数据示例
进程栈原始数据通常以 JSON 数组形式展示,每个元素一般对应一个线程的采集结果。以下为简化示例,用于帮助理解数据结构与阅读方式;实际输出字段可能随版本演进、运行环境和采集方式调整。
示例结构:
[
{
"pid": 4250,
"thread_id": 140200437851456,
"thread_name": "MainThread",
"os_thread_id": 4250,
"active": true,
"owns_gil": false,
"frames": [
{
"name": "cuStreamSynchronize",
"filename": "/usr/local/cuda/lib64/libcuda.so",
"module": "/usr/local/cuda/lib64/libcuda.so",
"short_filename": "libcuda.so",
"line": 0,
"locals": null,
"is_entry": true,
"is_shim_entry": true
},
{
"name": "train_step",
"filename": "/mnt/public/project/training.py",
"module": null,
"short_filename": "training.py",
"line": 1241,
"locals": null,
"is_entry": false,
"is_shim_entry": false
}
],
"process_info": null
}
]信息
上述内容仅为示意示例,并非固定不变的完整 schema。平台可能在后续版本中调整字段、补充元数据,或优化原生栈帧展示方式。若您需要对原始 JSON 做自动化处理,请以实际环境输出为准并做好兼容。
常见字段说明:
pid:进程 IDthread_id:线程 IDthread_name:线程名称,如MainThread、QueueFeederThread;部分线程名称可能为空或为nullos_thread_id:操作系统线程 IDactive:线程是否活跃owns_gil:是否持有 Python GIL(全局解释器锁)frames:调用栈帧数组,通常按采集结果顺序展示该线程的栈信息process_info:进程级附加信息;当前可能为空或为null
栈帧中的常见字段包括:
name:帧名称。可能是 Python 函数名、原生符号名、原始地址,少数情况下也可能为空字符串filename:源文件路径、二进制路径或动态库路径module:帧所属模块或动态库路径;部分 Python 源码帧可能为nullshort_filename:简化后的文件名或路径片段,便于快速阅读line:对应源码行号;对于原生帧或无法映射到源码位置的帧,可能为0locals:局部变量信息;当前可能为空或为nullis_entry:该帧是否被识别为入口帧或边界帧is_shim_entry:该帧是否属于桥接层、封装层或兼容层入口帧
数据特点:
- 每个进程可能包含多个线程(主线程、数据加载线程、后台线程等)
- 同一线程的栈中,可能同时出现 Python 源码帧、CPython 运行时帧,以及来自 C++ 动态库、PyTorch、CUDA 运行时等原生代码相关帧
- 原始数据字段可能随平台能力迭代而调整,因此不建议将当前 JSON 结构视为稳定接口契约
- 部分字段可能为空、缺失或仅在特定环境下返回;原生帧的符号解析完整度也可能因运行环境和调试符号情况而异
- 对于系统动态库或框架原生库中的帧,
line字段可能为0,这通常表示该帧无法直接映射到源码行,而不代表数据异常 active: false的线程通常处于等待状态
信息
原生栈帧(C++ 动态库等):在支持的情况下,进程栈中除 Python 调用外,还可包含 C++ 动态库等原生代码相关帧,便于排查扩展与底层库问题。具体展示与完整度因运行环境而异,部分场景下原生栈可能较少或缺失。
查看 NCCL 状态
NCCL 状态标签显示 NCCL 通信系统的运行状态,帮助诊断分布式通信问题。
信息
NCCL 状态信息由 NCCL RAS Server 提供,仅在使用 NCCL 进行分布式通信时可用。
NCCL 状态报告内容
版本信息:
NCCL version 2.26.3 compiled with CUDA 12.9
CUDA runtime version 12090, driver version 12080任务摘要:
Nodes Processes GPUs per process Processes (total) GPUs (total)
1 8 1 8 8显示任务的节点数、进程数和 GPU 数。
通信器状态(Communicators):
Group Comms Nodes Ranks Ranks Ranks Status Errors
# in group per comm per node per comm in group
0 1 1 7 8 7 RUNNING INCOMPLETE
3 2 1 2 2 4 RUNNING OK每个通信组的状态:
- RUNNING:通信器正在运行
- INIT:通信器正在初始化
- OK:通信正常
- INCOMPLETE:部分 rank 数据缺失
错误信息(Errors):
DEAD
1 job process is considered dead (unreachable via the RAS network)
Process 19377 on node 172.25.9.225 managing GPU 0
#0-0 (0623e6289c3f6e3c) INCOMPLETE
Missing communicator data from 1 rank
Rank 0 -- GPU 0 managed by process 19377 on node 172.25.9.225显示检测到的通信错误:
- DEAD:进程不可达
- INCOMPLETE:缺失部分 rank 数据
警告信息(Warnings):
可能的性能或配置问题。
数据保留和管理
数据保留期限
进程栈采集数据保留 30 天,过期后自动删除。
数据导出
进程栈数据无法直接导出下载,但可以通过直接复制到剪贴板。
性能影响
进程栈采集对训练任务的 GPU 算力占用可忽略,对日常训练影响通常很小。
- 自动采集:仅在 Hang 检测触发时执行,正常运行时无额外开销
- 手动采集:单次采集一般持续数秒至数十秒;采集瞬间可能对任务进程产生极短暂停顿,绝大多数场景可忽略,若对延迟极度敏感请酌情使用
建议在生产环境中开启自动采集,以便在问题发生时第一时间获取诊断数据。
相关文档
- 容错功能 - Hang 检测:了解 Hang 检测功能及其配置
- 使用 atlctl 进行原地调试:了解手动调试工具
- 查看容错日志:了解如何查看任务的容错日志