

查看资源使用与排队情况
在创建工作负载时,平台提供两个视图帮助用户了解资源状态:占用情况显示当前资源使用详情,负载排队情况显示等待资源的工作负载队列。这两个视图帮助用户评估资源可用性,决定是否调整 GPU 需求或选择其他资源池。
概述
创建工作负载前,了解资源状态有助于做出合理决策:
- 占用情况:显示资源池中各节点的 GPU 使用情况,包括总 GPU 数、已用数量、空闲数量,以及哪些工作负载正在使用资源。帮助判断是否有足够的连续 GPU 满足需求
- 负载排队情况:显示当前排队等待资源的工作负载列表。帮助评估等待时间和队列位置
访问方式
在创建开发机、任务或推理服务页面,选择包年包月资源池后,可看到两个按钮:
- 占用情况:点击查看当前资源使用详情
- 负载排队情况:点击查看排队工作负载列表
信息
这两个按钮仅在选择包年包月资源时显示。按量付费资源不支持这些功能。
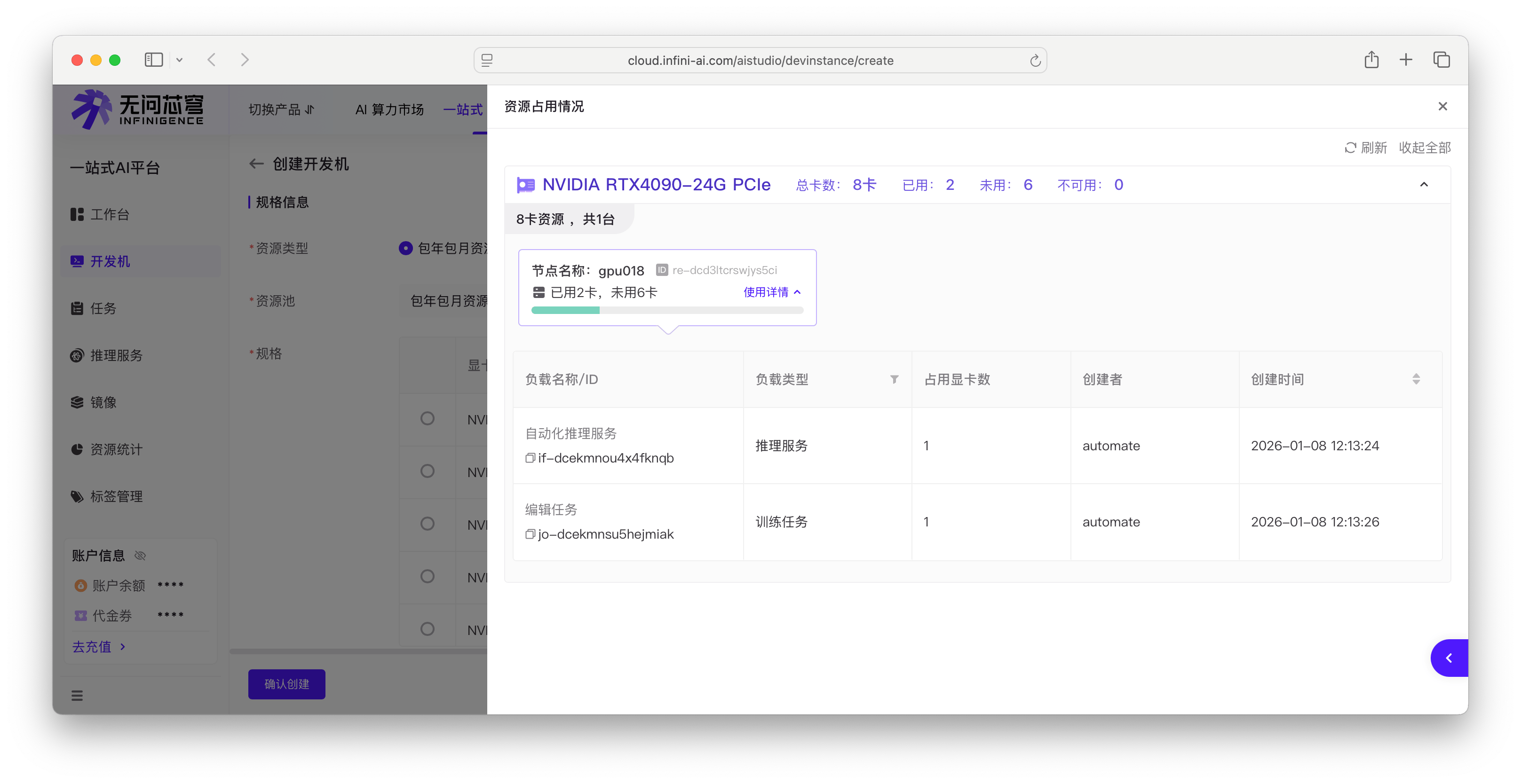
占用情况
占用情况视图显示资源池中各节点的 GPU 使用详情,帮助判断是否有足够的连续 GPU 资源满足工作负载需求。
资源占用情况视图
资源占用情况视图包含以下信息:
- 资源汇总:显示 GPU 规格(如 NVIDIA A100-80G)、总卡数、已用数量、未用数量
- 节点列表:按规格分组显示节点(如"8卡资源,共3台"),每个节点显示已用和未用的 GPU 数量
- 使用详情:点击节点可展开查看该节点上运行的工作负载,显示负载名称、类型、创建者等信息。包年包月资源池和专属资源池则显示占用 GPU 数量。共享资源池特别展示「占用显卡与显存占比」 字段(显示当前占用的全部显卡编号及显存使用情况)。详细字段说明见资源池占用情况。
判断资源可用性
多数 AI/ML 工作负载需要单个节点上的连续 GPU。例如,8 卡训练任务无法在多个节点上分散运行。查看占用情况时:
- 检查节点空闲情况:确认是否有单个节点具备所需数量的空闲 GPU。如所有节点都是"已用6卡,未用2卡",则无法启动 8 卡工作负载
- 评估总体使用率:即使总空闲 GPU 数量充足,如果分散在多个节点,也可能无法满足需求
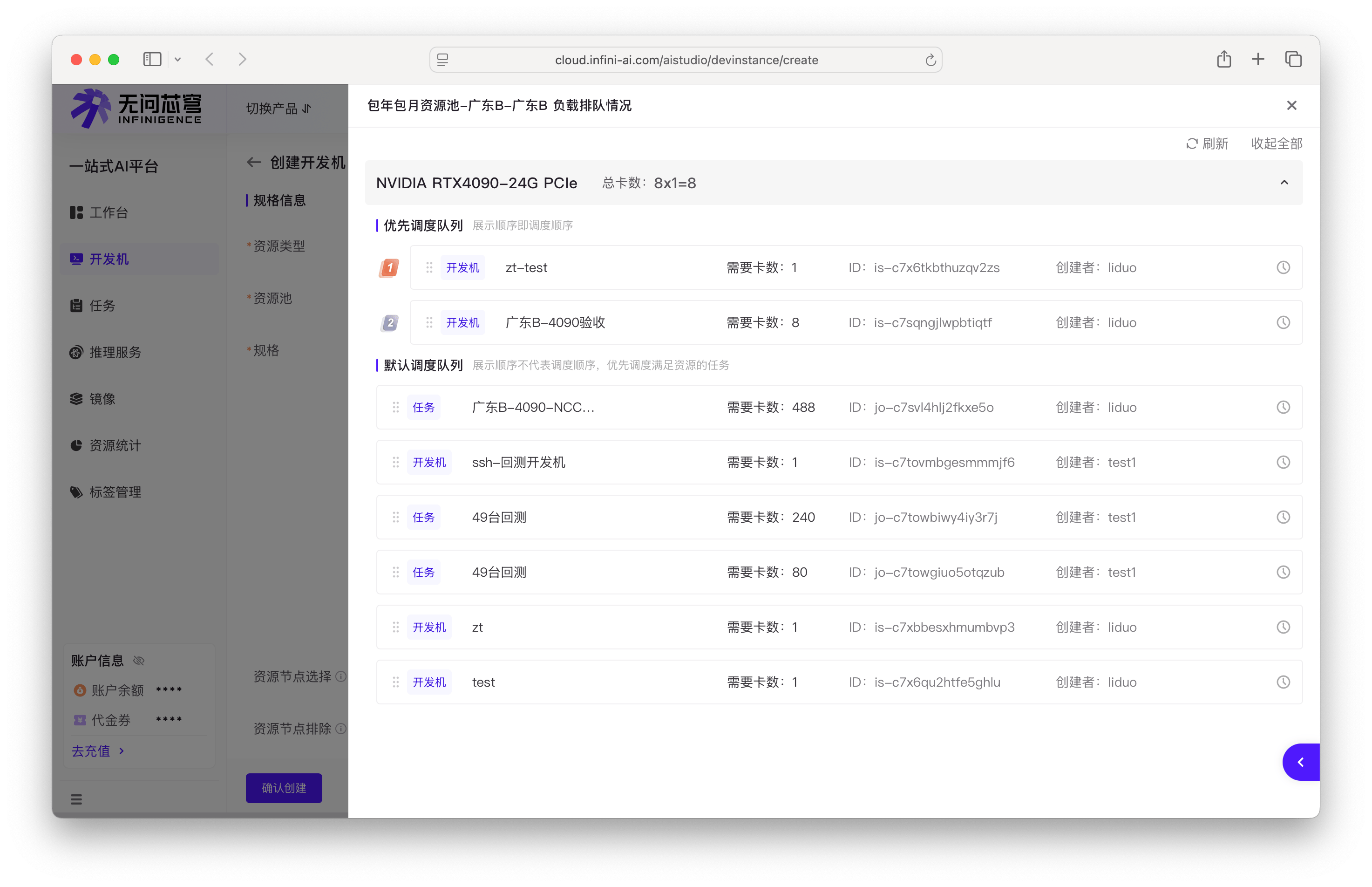
负载排队情况
负载排队情况视图显示当前排队等待资源的工作负载列表,帮助评估等待时间。租户管理员(或已授权用户)可手动调整工作负载优先级。
队列机制
平台采用两级队列机制:
- 优先调度队列:高优先级工作负载队列,系统严格按顺序调度。包括重调度、重跑、改配等恢复类请求,以及租户管理员手动提升优先级的工作负载
- 默认调度队列:普通工作负载队列,系统采用灵活调度策略,优先满足与当前空闲资源最匹配的工作负载
默认调度队列中,系统不是严格按排队顺序调度,而是优先调度 GPU 需求与空闲资源匹配的工作负载。例如,当节点释放 8 张 GPU 时,队列中第一个请求 8 卡的工作负载会被优先调度,而非队列头部的 1 卡工作负载。
负载排队情况视图
队列中每个工作负载显示以下信息:
- 负载名称/ID:工作负载的名称和唯一标识符
- 负载类型:开发机、推理服务或训练任务
- GPU 需求:请求的 GPU 数量和规格
- 创建者:创建该工作负载的用户
- 排队时间:进入队列的时间
- 队列位置:在当前队列中的位置序号
评估等待时间
查看队列时,可通过以下信息评估等待时间:
- 队列位置:位置越靠前,被调度的可能性越大
- GPU 需求匹配度:在默认调度队列中,GPU 需求与常见释放资源匹配时,等待时间可能更短
- 优先队列长度:优先调度队列清空后才会调度默认队列
优化策略
结合两个视图的信息,可采取以下措施优化资源使用:
- 调整 GPU 数量:查看占用情况后,如发现无连续空闲 GPU,可降低需求。例如,将 8 卡需求降为 4 卡
- 选择其他资源池:对比不同资源池的占用情况和排队长度,选择资源更充足的资源池
- 评估等待时间:查看排队情况后,决定是立即排队等待,还是调整配置或错峰使用
信息
两个视图显示的都是当前选中资源池的状态。切换资源池后需重新查看。租户管理员可手动调整工作负载优先级。